ViewPager, TabLayout
ViewPager는 화면을 양옆으로 밀어서 Page를 바꾸는 슬라이드 동작을 하는 View입니다. 굉장히 많이 사용하는 방식인데요. 보통 TabLayout과 같이 사용하는 것이 일반적입니다.
아래처럼 1번, 2번과 같이 선택할 수 있게 하는 것이 TabLayout이며 프래그먼트를 포함하는 것이 ViewPager입니다. 물론 둘은 독립적으로도 사용할 수 있습니다.
아래와 같은 결과를 만들어내는것이 이번 포스팅의 목표입니다.
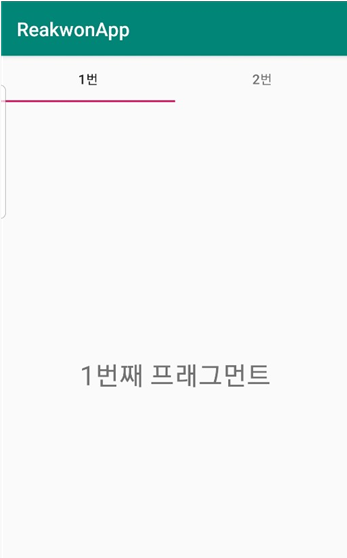 |
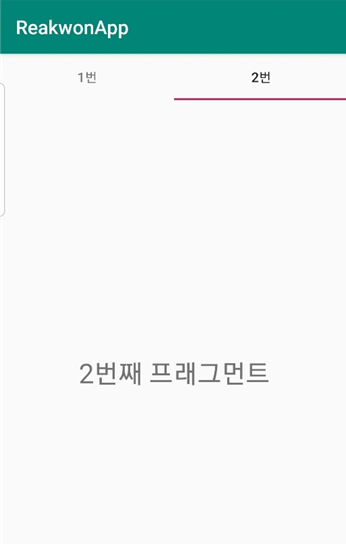 |
우선 구현하기에 앞서 TabLayout은 아래의 라이브러리가 있어야 사용할 수 있습니다. 추가합시다.
File - Project Structure - app - '+' - design 검색 후 아래 라이브러리 추가
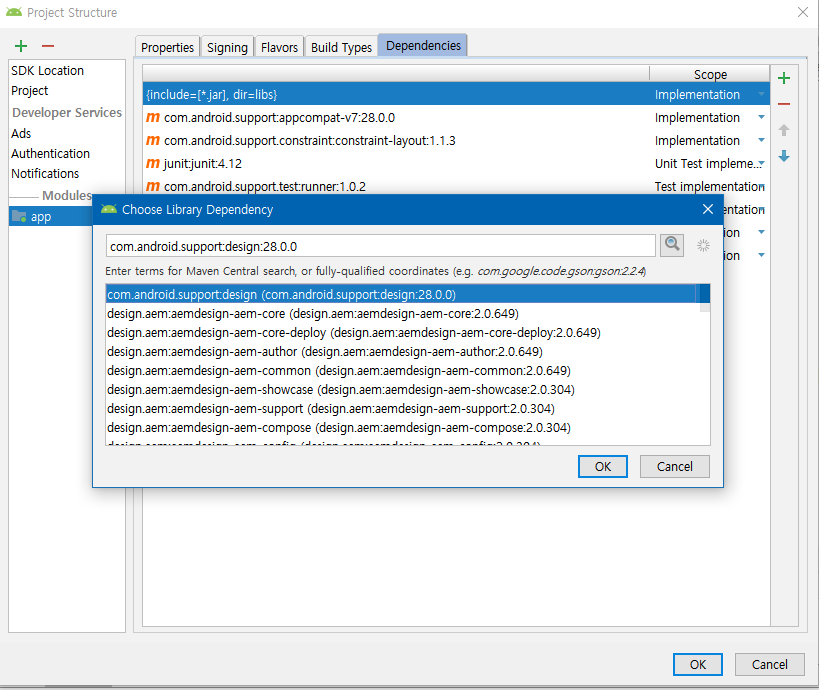
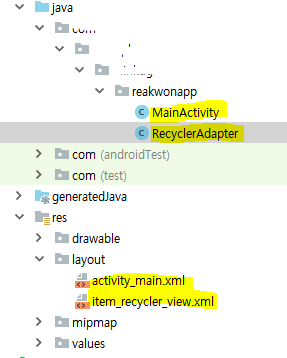
1) activity_main.xml
MainActivity에서 사용할 activity_main에서는 TabLayout과 ViewPager를 추가합니다.
<?xml version="1.0" encoding="utf-8"?>
<LinearLayout xmlns:android="http://schemas.android.com/apk/res/android"
xmlns:app="http://schemas.android.com/apk/res-auto"
xmlns:tools="http://schemas.android.com/tools"
android:layout_width="match_parent"
android:layout_height="match_parent"
android:orientation="vertical"
tools:context=".MainActivity">
<android.support.design.widget.TabLayout
android:id="@+id/tabLayout"
android:layout_width="match_parent"
android:layout_height="wrap_content" />
<android.support.v4.view.ViewPager
android:layout_width="match_parent"
android:layout_height="match_parent"
android:id="@+id/viewPager"/>
</LinearLayout>2) fragment1.xml, fragment2.xml
ViewPager에서 사용될 실제 내용을 담는 두 fragment의 layout입니다. 간단하게 TextView만이 존재하는 간단한 layout이네요.
fragment1.xml
<?xml version="1.0" encoding="utf-8"?>
<LinearLayout
xmlns:android="http://schemas.android.com/apk/res/android" android:layout_width="match_parent"
android:layout_height="match_parent">
<TextView
android:layout_width="match_parent"
android:layout_height="wrap_content"
android:layout_gravity="center"
android:textAlignment="center"
android:textSize="28dp"
android:text="1번째 프래그먼트"/>
</LinearLayout>fragment2.xml
<?xml version="1.0" encoding="utf-8"?>
<LinearLayout
xmlns:android="http://schemas.android.com/apk/res/android" android:layout_width="match_parent"
android:layout_height="match_parent">
<TextView
android:layout_width="match_parent"
android:layout_height="wrap_content"
android:layout_gravity="center"
android:textAlignment="center"
android:textSize="28dp"
android:text="2번째 프래그먼트"/>
</LinearLayout>
3) Fragment1, Fragment2
위에서 정의한 layout을 inflate하는 Fragment1과 Fragment2입니다. 역시 아주 간단하게 onCreateView만 정의하였습니다.
Fragment1
package com.example.minkug.reakwonapp;
import android.os.Bundle;
import android.support.annotation.NonNull;
import android.support.annotation.Nullable;
import android.support.v4.app.Fragment;
import android.view.LayoutInflater;
import android.view.View;
import android.view.ViewGroup;
public class Fragment1 extends Fragment {
@Nullable
@Override
public View onCreateView(@NonNull LayoutInflater inflater, @Nullable ViewGroup container, @Nullable Bundle savedInstanceState) {
return inflater.inflate(R.layout.fragment1,container,false);
}
}
Fragment2
package com.example.minkug.reakwonapp;
import android.os.Bundle;
import android.support.annotation.NonNull;
import android.support.annotation.Nullable;
import android.support.v4.app.Fragment;
import android.view.LayoutInflater;
import android.view.View;
import android.view.ViewGroup;
public class Fragment2 extends Fragment {
@Nullable
@Override
public View onCreateView(@NonNull LayoutInflater inflater, @Nullable ViewGroup container, @Nullable Bundle savedInstanceState) {
return inflater.inflate(R.layout.fragment2,container,false);
}
}
4) PagerAdapter
가장 중요한 PagerAdapter를 구현할 차례입니다. 우서 가장 먼저할 것은 FragmentStatePagerAdapter를 상속을 받아야하지요.
이제 1개의 생성자와 2개의 메소드만 Overriding하면 기본적인 Adapter 작성은 끝이납니다.
4-1) FragmentManager를 받는 생성자 구현
4-2) 실제 Fragment를 반환하는 getItem 구현
4-3) 페이지의 개수를 반환하는 getCount구현
여기서는 Adapter가 생성될때 fragments라는 list에 우리가 위에서 정의한 2개의 프래그먼트를 추가합니다. 그렇게 되면 getItem은 리스트의 i번재 아이템을 반환하면 될 것이고, getCount 역시 리스트의 사이즈를 반환하면 되기 때문에 구현이 조금 더 간단해집니다.
package com.example.minkug.reakwonapp;
import android.support.v4.app.Fragment;
import android.support.v4.app.FragmentManager;
import android.support.v4.app.FragmentStatePagerAdapter;
import java.util.ArrayList;
import java.util.List;
public class PagerAdapter extends FragmentStatePagerAdapter {
List<Fragment> fragments=new ArrayList<>();
public PagerAdapter(FragmentManager fm) {
super(fm);
fragments.add(new Fragment1());
fragments.add(new Fragment2());
}
@Override
public Fragment getItem(int i) {
return fragments.get(i);
}
@Override
public int getCount() {
return fragments.size();
}
}
5) MainActivity
MainActivity가 코드가 조금 길어보이기는 하나 별다른 것이 없습니다. 우선 ViewPager, TabLayout을 얻어오고, TabLayout에는 Tab을 설정해주네요.
조금 눈여겨봐야될 것은 아래 2개의 Listener입니다.
5-1) viewPager.addOnPageChangeListener : Pager가 변경될때 발생하는 이벤트인데, 이때는 TabLayout의 탭까지 변경을 해줘야합니다. Pager를 슬라이딩하여 바꾼다고 하더라도 이 동작을 처리하지 않으면 Tab은 같이 변경되지 않습니다.
5-2) tabLayout.addOnTabSelectedListener : 마찬가지로 tab이 눌려졌다면 page도 같이 변경해주어야합니다. 탭이 선탤될때 발생하는 이벤트는 onTabSelected이며 tab이라는 인자로 선택된 tab의 위치를 알 수 있습니다. 이것을 이용해서 pager를 선택하면 되는 것이죠.
package com.example.minkug.reakwonapp;
import android.support.design.widget.TabLayout;
import android.support.v4.view.ViewPager;
import android.support.v7.app.AppCompatActivity;
import android.os.Bundle;
public class MainActivity extends AppCompatActivity {
private ViewPager viewPager;
private TabLayout tabLayout;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
tabLayout=(TabLayout)findViewById(R.id.tabLayout);
tabLayout.addTab(tabLayout.newTab().setText("1번"));
tabLayout.addTab(tabLayout.newTab().setText("2번"));
viewPager=(ViewPager)findViewById(R.id.viewPager);
viewPager.setAdapter(new PagerAdapter(getSupportFragmentManager()));
viewPager.addOnPageChangeListener(new TabLayout.TabLayoutOnPageChangeListener(tabLayout));
tabLayout.addOnTabSelectedListener(new TabLayout.OnTabSelectedListener() {
@Override
public void onTabSelected(TabLayout.Tab tab) {
viewPager.setCurrentItem(tab.getPosition());
}
@Override
public void onTabUnselected(TabLayout.Tab tab) { }
@Override
public void onTabReselected(TabLayout.Tab tab) { }
});
}
}
구현은 끝났고 여러분이 원하는 방향으로 기능을 추가해보시기 바랍니다.
'안드로이드' 카테고리의 다른 글
| [안드로이드] 서울시 버스 도착 정보 조회 api 사용 - 공공데이터포털 Open API (0) | 2021.05.01 |
|---|---|
| [안드로이드] RecyclerView 수평 이동 및 한번에 항목 하나만 보이게 만들기 (0) | 2020.07.01 |
| [안드로이드] AsyncTask를 이용하여 시계(Timer) 구현 (0) | 2020.06.29 |
| [안드로이드/android] RecyclerView 사용법(Recycler Adpater, View Holder, 이벤트 전달) (0) | 2020.03.20 |
| android 프래그먼트(Fragment) (0) | 2018.09.27 |

REAKWON
와나진짜