


Vector
Standard Template Library의 컨테이너로 정의된 클래스인데요. 배열과 비슷한 특징이 있습니다만, 동적으로 계속하여 뒤에 원소를 추가할 수 있습니다. 배열을 다루는 사용자의 불편함을 vector를 사용하면 어느정도 편리하게 사용할 수 있습니다. 이 포스팅에서는 vector의 사용방법에 대해서 다룹니다.
C++에서 vector를 사용하기 위해서는 아래와 같이 vector 헤더파일을 추가시키시면 됩니다.
#include <vector>
1. 초기화
배열과 비슷하다고 했습니다만 초기화 방법에서는 약간 차이가 있습니다. 아래의 코드는 초기화 방식을 설명합니다.
vector<int> v1; //아무것도 없는 비어있는 vector
vector<int> v2(5); //5개의 int형을 저장하는 vector(전부 0으로 초기화)
vector<int> v3(5,1); //5개의 int형을 저장하는 vector(전부 1로 초기화)
vector<int> v4 = { 1,2,3,4,5 }; //배열과 같은 초기화
vector<int> v5(v4); //v4의 벡터 요소를 복사해서 초기화
2. 크기와 용량(size & capacity)
vector는 현재 가지고 있는 데이터의 수를 나타내는 크기(size)와 얼만큼의 데이터를 담을 수 있는지에 대한 용량(capacity)가 있습니다. 만약 용량이 전부 꽉 차게 되면 용량을 동적으로 더 늘려서 데이터를 추가할 수 있습니다. vector의 용량은 항상 size보다 크거나 같습니다. 아래의 그림처럼 capacity가 모자라게 되면 늘리게 되는거죠.
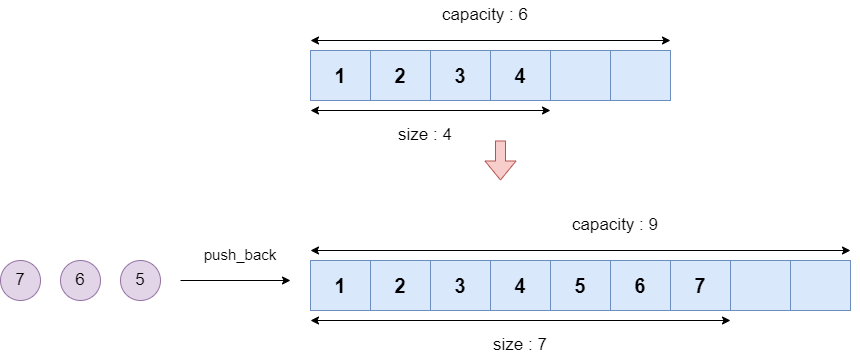
코드로 직접 확인해보세요.
#include <iostream>
#include <vector>
using namespace std;
int main() {
vector<int> v;
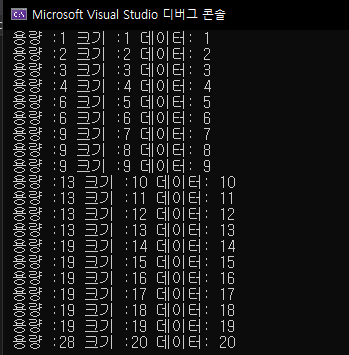
for (int i = 0; i < 20; i++) {
v.push_back(i + 1);
cout << " 용량 :" << v.capacity();
cout << " 크기 :" << v.size();
cout << " 데이터: " << v[i] << endl;
}
return 0;
}
3. 데이터 읽기
데이터읽는 방법은 배열과 같이 []로 접근하는 방법과 at() 으로 접근하는 방법이 있습니다. 둘은 같은 값을 나타내줍니다. 아래의 코드를 보고 결과가 같은지 확인해봅시다.
int main() {
vector<int> v = { 1,5,3,6,8 };
cout << "v[1]:" << v[1] << endl;
cout << "v.at(1):" << v.at(1) << endl;
cout << "v[3]:" << v[3] << endl;
cout << "v.at(3):" << v.at(3) << endl;
return 0;
}
둘은 같은 값을 나타내고 있죠? 하지만 차이는 없을까요? 있겠죠. 만약 배열 접근 기호([])로 10번째 요소를 읽어봅시다. 현재 5번째까지 초기화했고, 10번째는 아직 접근할 수 없기 때문에 아래와 같은 에러를 보이고 종료하고 맙니다. at()통해서도 마찬가지일거에요. 하지만 둘의 차이는 예외를 뜨게해서 처리할수 있게 만들었느냐 아니냐입니다.
아래의 코드를 실행시켜보시고, 바꿔서 윗줄은 주석처리, 아랫줄은 주석 해제하여 실행해보세요. 차이점을 알 수 있습니다.
#include <iostream>
#include <vector>
using namespace std;
int main() {
vector<int> v = { 1,5,3,6,8 };
try {
cout << v[10] << endl;
//cout << v.at(10) << endl;
}
catch (out_of_range& e) {
cout << "예외 발생 처리 " << endl;
}
return 0;
}
프로그래밍을 at()으로 하면 더 안전하게 사용할 수 있는 대신 검사때문에 []를 이용하는 방법보다는 느립니다. 두 방식 중 알맞게 선택하여 사용하세요.
4. 데이터쓰기
데이터쓰기는 너무 편합니다. 그냥 배열과 같이 사용하면 됩니다.
vector<int> v = { 5,3,1,6,7 };
v[2] = 3;
5. 데이터 뒤에 추가 및 뒤에서 삭제
push_back()을 사용하면 아래와 같이 vector 뒤에 차곡차곡 데이터를 추가합니다. 반대로 삭제하려면 pop_back()을 사용하시면 됩니다. pop_back()은 데이터를 return하지는 않고, 단지 꺼내주기만 합니다. 가장 마지막 원소를 가져오려면 back()을 이용하세요.
#include <iostream>
#include <vector>
using namespace std;
int main() {
vector<int> v;
v.push_back(10);
v.push_back(13);
v.push_back(15);
v.push_back(20);
int size = v.size();
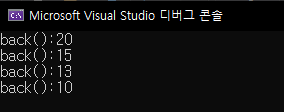
for (int i = 0; i < size; i++) {
cout << "back():" << v.back() << endl;
v.pop_back();
}
return 0;
}
6. Iterator
Iterator를 통해서 for문을 돌수도 있습니다. vector의 begin()은 vector의 처음 요소를 가리키고 있습니다. vector의 end()는 vector의 마지막 요소 다음을 가리키고 있습니다. 마지막 요소 다음이지 마지막 요소를 가리키는게 아닙니다.
그래서 아래와 같이 for문을 사용하는 방법이 가능합니다.
vector<int> v = { 0,9,21,1,0,29 };
for (vector<int>::iterator it = v.begin(); it != v.end(); it++)
cout << *it << endl;
너무 복잡하죠? 아래와 같이 auto로 코드를 줄일 수 있습니다.
for (auto it = v.begin(); it != v.end(); it++)
cout << *it << endl;
7. reserve
용량을 지정한 수대로 동적할당을 미리 시켜놓습니다.
int main() {
vector<int> v = { 0,9,21,1,0,29,2022 };
cout << "capacity:" << v.capacity() << endl;
v.reserve(10);
cout << "capacity:" << v.capacity() << endl;
v.reserve(15);
cout << "capacity:" << v.capacity() << endl;
return 0;
}
8. insert
insert는 iterator를 통해서 원소를 삽입하는 방식입니다. 아래와 같이 사용가능합니다.
#include <iostream>
#include <vector>
using namespace std;
int main() {
vector<int> v = { 0,9,21,1,0,29,2022 };
vector<int>::iterator it=v.begin(); //맨앞
//v.insert(it, 90); //맨앞에 90삽입
v.insert(it + 4, 90); //4번째 원소에 90삽입
for (auto it = v.begin(); it != v.end(); it++)
cout << *it << endl;
return 0;
}
이 밖에도 insert는 오버로딩이 되어있으므로 찾아보셔서 알맞는 것을 사용하면 됩니다.
9. 정렬
vector는 algorithm 헤더파일의 sort()함수로 정렬이 가능합니다. 다만 기본 자료형만 가능하다는 점이고, 클래스같은 경우는 별도로 비교 함수를 사용하여 delegator 방식으로 처리해야합니다.
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
int main() {
vector<int> v = { 0,9,21,1,0,29,2022 };
sort(v.begin(), v.end());
for (auto it = v.begin(); it != v.end(); it++)
cout << *it << endl;
return 0;
}이 밖에도 insert는 오버로딩이 되어있으므로 찾아보셔서 알맞는 것을 사용하면 됩니다.

그외에도 여러가지 vector 관련 함수들이 있는데요. 어렵지 않은 함수들이니까 나중에 직접 찾아서 활용해보시기 바랍니다.
'언어 > C++' 카테고리의 다른 글
| [C++] Map 개념과 사용방법, 예제 코드 + 백준 문제 풀이(BOJ 1764) (0) | 2022.03.28 |
|---|---|
| [C언어/C++] lower_bound(하한)과 upper_bound(상한)을 C와 C++에서 사용하는 예제 코드 (0) | 2021.03.23 |
| [C++] new,delete 키워드와 오버라이딩(Overriding),다형성(Polymorphism)의 개념과 virtual키워드 사용방법, 객체의 this 포인터 개념 (0) | 2021.03.18 |
| [C++] 클래스와 상속(Inheritance)의 개념과 사용법, 캡슐화의 이해 (0) | 2021.03.16 |
| [C++]C++ 함수의 특징(오버로딩, 디폴트 인수, 참조자, 인라인 함수) (0) | 2019.05.06 |

REAKWON
와나진짜
