HashSet
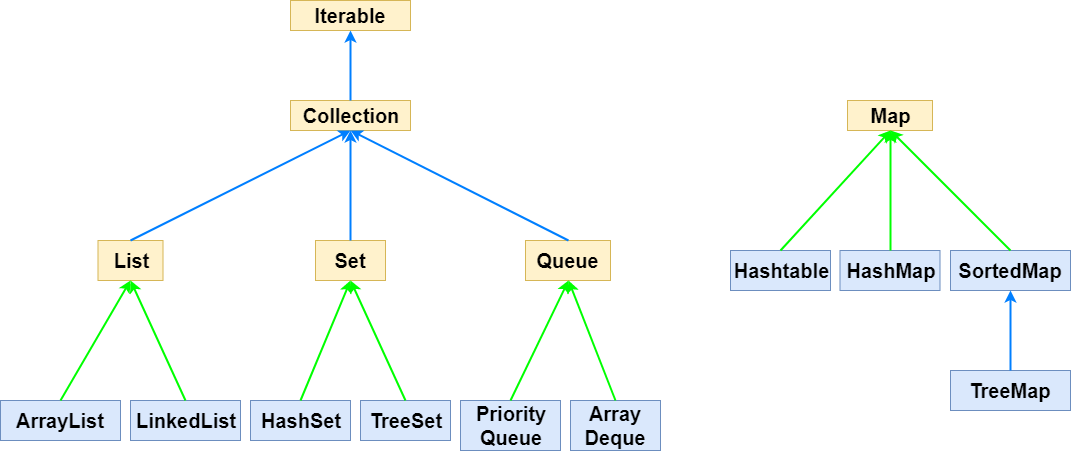
자바 Collection 중 Set의 대표적인 HashSet 클래스를 다루어 보도록 하겠습니다. HashSet은 Set의 파생클래스로 Set은 기본적으로 집합으로 중복된 원소를 허용하지 않습니다. HashSet은 순서 역시 고려가 되지 않습니다. 그렇다면 다음의 예제로 HashSet의 기본적인 동작을 살펴보도록 하겠습니다.
public static void main(String[] args){
Set hashSet=new HashSet();
hashSet.add("F");
hashSet.add("B");
hashSet.add("D");
hashSet.add("A");
hashSet.add("C");
/* 위와 같은 데이터들을 다시 add */
hashSet.add("F");
hashSet.add("B");
hashSet.add("D");
hashSet.add("A");
hashSet.add("C");
/* HasSet의 "C"라는 원소 삭제 */
hashSet.remove("C");
/* HashSet 모든 원소 출력 */
System.out.println("HashSet 원소 출력");
Iterator it=hashSet.iterator();
while(it.hasNext()){
System.out.print(it.next()+" ");
}
/* HashSet의 모든 원소를 ArrayList로 전달 */
List arrayList=new ArrayList();
arrayList.addAll(hashSet);
/* ArrayList의 모든 원소 출력 */
System.out.println();
System.out.println("ArrayList 원소 출력");
for(int i=0;i<arrayList.size();i++){
System.out.print(arrayList.get(i)+" ");
}
}
우선 HashSet에 "F", "B", "D", "A", "C"라는 문자열을 차례대로 넣었습니다. 그리고 나서 다시 같은 데이터들을 넣게 되죠. Set에는 중복을 허용하지 않는다고 하였으니 Set에는 현재 { "F", "B", "D", "A", "C" }가 존재합니다.
그 후에 "C"라는 문자열을 지우는 군요. 뭐 쉽습니다. "C"라는 원소를 삭제했으니 { "F", "B", "D", "A"}만이 남는것을 알 수 있겠군요. HashSet을 출력하는 부분을 보고 확인해보세요.
|
아, HashSet에는 순서가 없으므로 Iterator를 사용해서 집합안의 원소를 출력하고 있습니다. Iterator의 메소드는 3개가 다인데요. hasNext() : 다음 원소가 남아있는지 여부를 알아냅니다. 다음 원소가 남았다면 true를 반환합니다. next() : 다음 원소를 가져옵니다. remove() : 현재 반복자가 가리키고 있는 원소를 삭제합니다. |
장난삼아서 ArrayList에 HashSet의 원소를 모두 전달해서 확인해봤습니다. 아래는 그 결과입니다.
| HashSet 원소 출력 A B D F ArrayList 원소 출력 A B D F |
이제 우리는 단순히 String 타입의 자료형이 아닌 우리가 정의한 클래스의 객체를 HashSet의 원소에 넣고 싶습니다. 그렇다면 어떻게 중복된 원소인지 아닌지를 확인할 수 있을까요?
위에서 String 객체를 HashSet은 어떻게 중복된 원소라고 감지했을까요? HashSet이 알아서 판단해 줄까요?
우리가 다음과 같은 Person 클래스가 있다고 합시다.
class Person{
String name; //이름
int residentNumber; //주민번호
}
사람이 같은지 여부를 판별하는 것은 주민등록번호를 보고 알 수 있지요? 허나 Set에 단순히 이 Person 클래스를 넘겨준다면 중복 여부를 판별하지 못할 겁니다. Set이 Person 객체의 어떤 메소드를 호출해서 같은지 말지를 판변할 수 있으니까요. 그 메소드가 바로 equals와 hashCode입니다.
1. equals(Object o)
만약 두 객체(현재 이 객체와 인자로 넘어온 객체 o)가 같다는 것을 알려주려면 equals 메소드에서 true를 반환해주어야합니다.
2. hashCode()
만약 equals에서 두 객체가 같다라고 true를 반환했다면 hashCode는 두 객체에서 항상 같은 값을 반환해야합니다. 만일 equals에서 false를 반환하여 같지 않다고 반환했다면 hashCode 역시 다르게 반환하는 것이 좋습니다.
위의 조건을 고려해서 구현한 Person 클래스를 다시 봅시다.
class Person{
String name; //이름
int residentNumber; //주민번호
public Person(String name,int residentNumber){
this.name=name;
this.residentNumber=residentNumber;
}
@Override
public int hashCode(){
/* Objects.hash 메소드로 residentNumber의 해쉬값 반환 */
return Objects.hash(residentNumber);
}
@Override
public boolean equals(Object o){
/* 주민 번호가 같은 Person은 true 반환 */
Person p=(Person)o;
return p.residentNumber==this.residentNumber;
}
}
equals와 hashCode를 Override한 코드를 확인해봅시다.
equals에서는 단순히 residentNumber만 비교해서 같다면 true, 다르다면 false입니다.
hashCode에서는 Objects.hash 메소드로 residentNumber의 해쉬값을 반환합니다. 이 hash는 residentNumber가 다르다면 항상 다른 값이 반환됩니다.
이제 Set에 원소를 넣고 확인해보도록 하지요.
public static void main(String[] args){
Set hashSet=new HashSet();
hashSet.add(new Person("reakwon",111111));
hashSet.add(new Person("KDC",222222));
hashSet.add(new Person("KSG",333333));
hashSet.add(new Person("reakwon",111112));
hashSet.add(new Person("MJW",111111));
Iterator it=hashSet.iterator();
while(it.hasNext()){
Person p=it.next();
System.out.println(p.name+"/"+p.residentNumber);
}
}
동명이인이 있군요. 주민 번호 111111인 reakwon과 주민 번호 111112인 reakwon인 객체들이네요. 우리는 이름이 같은것은 같은 객체로 보지 않습니다. 주민 번호가 같은 객체만 중복된 원소로 보는 것이죠.
그래서 이 두 객체는 집합에 추가가 됩니다.
하지만 이름이 주민번호가 111111의 "MJW"라는 객체와 주민번호 111111의 "reakwon"라는 객체는 같습니다. 주민번호가 같기때문입니다. 그래서 "MJW"라는 Person객체는 집합이 추가하지 않습니다.
그 집합의 모든 원소를 출력한 결과는 아래와 같습니다.
| KSG/333333 reakwon/111112 reakwon/111111 KDC/222222 |
이제 우리가 만든 객체들도 HashSet에 추가할 수 있습니다.
HashSet을 알아보았으니 다음은 HashMap에 대해서 알아볼 차례겠군요. 아래의 링크로 들어가서 개념과 사용법을 익혀보도록 합시다.
[자바] 해시맵(HashMap)의 개념과 사용 예, 기본 메소드와 같은 키인지 판별하는 방법
해시맵(HashMap) 해시맵은 이름 그대로 해싱(Hashing)된 맵(Map)입니다. 여기서 맵(Map)부터 짚고 넘어가야겠죠? 맵이라는 것은 키(Key)와 값(Value) 두 쌍으로 데이터를 보관하는 자료구조입니다. 여기서
reakwon.tistory.com
'언어 > JAVA' 카테고리의 다른 글
| [자바/JAVA] 쓰레드 동기화 (Thread Synchronization), synchronized (0) | 2019.12.07 |
|---|---|
| [JAVA/자바] 쓰레드(Thread) 다루기( Thread상속, Runnable 구현, join) (3) | 2019.12.07 |
| [JAVA] 자바 Collection개념,상속도, 파생클래스들 (0) | 2019.06.06 |
| [자바/JAVA] 문자열 다루기 2 String getBytes 인코딩, 디코딩 (0) | 2019.05.05 |
| [자바/JAVA] 문자열 다루기1 String 클래스 메소드 (0) | 2019.05.05 |

REAKWON
와나진짜