


14499번 주사위 굴리기
https://www.acmicpc.net/problem/14499
14499번: 주사위 굴리기
첫째 줄에 지도의 세로 크기 N, 가로 크기 M (1 ≤ N, M ≤ 20), 주사위를 놓은 곳의 좌표 x y(0 ≤ x ≤ N-1, 0 ≤ y ≤ M-1), 그리고 명령의 개수 K (1 ≤ K ≤ 1,000)가 주어진다. 둘째 줄부터 N개의 줄에 지도에 쓰여 있는 수가 북쪽부터 남쪽으로, 각 줄은 서쪽부터 동쪽 순서대로 주어진다. 주사위를 놓은 칸에 쓰여 있는 수는 항상 0이다. 지도의 각 칸에 쓰여 있는 수는 10을 넘지 않는 자연수이다. 마지막 줄에
www.acmicpc.net
문제 해석
어떤 판 위에 주사위가 있습니다. 이 판에는 임의의 숫자가 적혀있습니다. 주사위를 입력받은 방향으로 굴리면서 주사위 윗면의 숫자를 조건에 따라 출력해주는 문제입니다. 규칙을 따져보자면 이렇습니다.
1. 처음 주사위의 모든 면에는 0이 쓰여있습니다. 그러니까 처음 6면에는 모두 0인 수가 적혀있는 것이죠.
2. 주사위가 굴러가면서 주사위 아랫면에 판의 숫자가 쓰여집니다. 단, 판의 숫자가 0일때는 주사위 윗면의 숫자를 출력해줍니다.
3. 만약 주사위가 판의 범위에서 나가는 입력이 들어왔을때는 깔끔하게 무시해주면 됩니다.
제약 조건
판의 가로(N), 세로(M) 크기는 1이상 20이하, 그리고 주사위를 어느 방향으로 굴릴지에 대한 입력은 1이상 1000이하로 들어옵니다. 주사위의 처음 위치는 판의 범위에 있어야하므로 좌표의 위치(x,y)는 0 ≤ x ≤ N-1, 0 ≤ y ≤ M-1 입니다.
풀이
문제의 조건이 약간 이상하긴 합니다. 보통 x는 가로, y는 세로를 문제로 주고 역시 n도 세로의 길이, m도 가로의 길이로 주는게 조금 일반적이거든요.
그래서 저는 y를 세로 좌표, x를 가로 좌표로 두고 문제를 풀겠습니다.
우선 주사위를 어떻게 굴릴지 머리부터 굴려봅시다. 우선 전개도로 어떻게 주사위를 굴려볼까 봅시다.
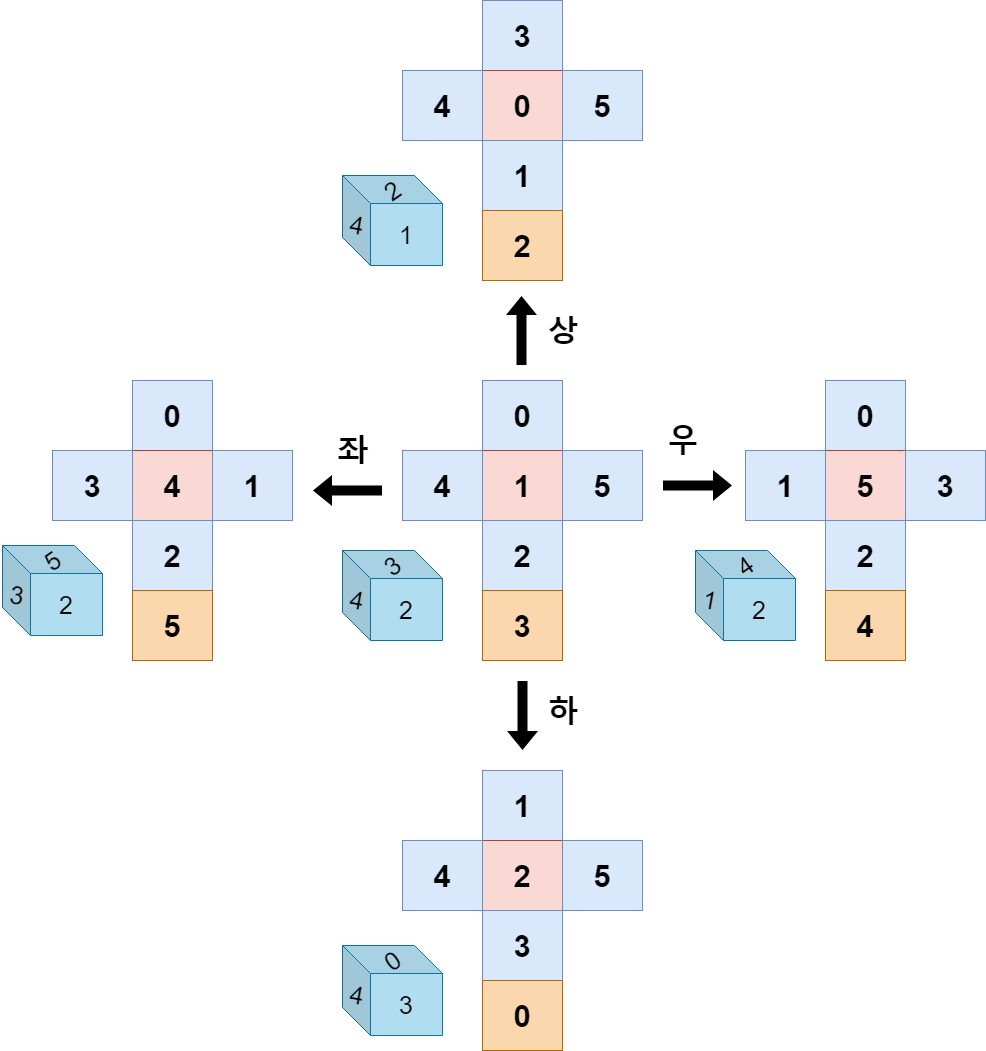
그림에서 가장 가운데 주사위의 전개도가 초기의 주사위입니다. 분홍색이 아랫면, 주황색이 윗면이라고 가정하지요. 주사위의 왼쪽면은 왼쪽 날개, 오른쪽 면은 오른쪽 날개라고 가정한다면 가운데의 주사위 전개도의 모든 면은 이렇게 되겠네요.
0번: 뒷면, 1번: 아랫면, 2번: 앞면, 3번: 윗면, 4번: 왼쪽면, 5번: 오른쪽면
그렇죠?
우리는 이것을 배열 인덱스로 생각해야합니다. 그러니 전개도의 숫자는 적혀져있는 숫자가 아니고 자리를 나타냅니다.
만약 이 상태에서 오른쪽으로 주사위를 굴린다면 0번 자리에 있던 수는 그대로 0번 자리에 있던 수가, 기존 1의 위치에는 5번의 자리에 있는 수가, 기존 2의 자리에는 그대로 2의 자리에 있던 수가, 기존 3의 자리에는 4의 자리에 있던 수가, 기존 4의 자리에는 1의 자리에 있던 수가, 기존 5의 자리에는 3의 자리에 있던 수가 됩니다. 숫자들이 자리를 찾아 이동하게 된것이죠.
정리하자면 이렇습니다.
| 기존 자리 | 이동 |
| 0 | 0 |
| 5 | 1 |
| 2 | 2 |
| 4 | 3 |
| 1 | 4 |
| 3 | 5 |
이처럼 오른쪽으로 이동할때 5번째 자리에 있던 숫자는 1번째 자리로 이동하며, 4번째 자리에 있던 숫자는 3번째 자리로 이동합니다.
그렇게 위로 굴렸을때, 아래로 굴렸을때, 왼쪽으로 굴렸을때, 오른쪽으로 굴렸을때는 위의 그림의 전개도와 같습니다.
자, 이것을 이제 배열로 표현해보지요.
int dice[6];
int perm[5][6] = {
{},
{ 0,5,2,4,1,3 },{ 0,4,2,5,3,1 },
{ 3,0,1,2,4,5 },{ 1,2,3,0,4,5 }
};
주어지는 입력에서 주사위를 굴릴때 동쪽은 1(오른쪽으로 굴릴 때), 서쪽은 2(왼쪽으로 굴릴 때), 북쪽은 3(위쪽으로 굴릴때), 남쪽은 4(아래쪽으로 굴릴 때) 이니까 그 순서대로 배열에 초기화했습니다. 0번은 동서남북으로 쓰여지 않으니 비어두었습니다.
그리고 dice라는 배열은 실제 주사위를 의미합니다. 여기에 주사위에 실제 적혀있는 숫자가 저장이 되죠.
이제 perm이라는 2차원 배열과 dice가 어떻게 동작하게 될까요? 우선 주사위 dice에는 다음과 같이 {5, 4, 3, 6, 8, 9}라는 수가 적혀져있다고 가정해보겠습니다. 이것을 오른쪽으로 굴리면 dice의 숫자는 어떻게 변할까요?

dice는 perm의 값의 따라 위치를 찾아 이동합니다. 오른쪽으로 이동할때 0번의 숫자는 0번으로, 5번의 숫자는 1번으로, 2번의 수는 2번으로, 4번의 수는 3번으로, 1번의 수는 4번으로, 3번의 수는 5번으로 이동하게 됩니다.
코드로 구현하면 이렇습니다.
void roll(int d) {
int temp[6];
for (int i = 0; i < 6; i++)
temp[i] = dice[perm[d][i]];
for (int i = 0; i < 6; i++)
dice[i] = temp[i];
}
roll이라는 함수는 방향 d를 인자로 받습니다. 이렇게 d(1은 오른쪽, 2는 왼쪽, 3은 위쪽, 4는 아래쪽)에 따라서 perm을 결정하고 어떻게 dice를 배열할지를 정하게 됩니다.
이를 토대로 이제 전체 문제를 풀면 됩니다.
int map[21][21], command[1001], n, m, k;
int perm[5][6] = {
{},
{ 0,5,2,4,1,3 },{ 0,4,2,5,3,1 },
{ 3,0,1,2,4,5 },{ 1,2,3,0,4,5 }
};
int inc[5][2]{ {},{ 0,1 },{ 0,-1 },{ -1,0 },{ 1,0 } };
int dice[6];
void roll(int d) {
int temp[6];
for (int i = 0; i < 6; i++)
temp[i] = dice[perm[d][i]];
for (int i = 0; i < 6; i++)
dice[i] = temp[i];
}
void solve(int next, int y, int x) {
if (next == k) return;
int dir = command[next];
int Y = y + inc[dir][0], X = x + inc[dir][1];
if (Y < 0 || Y >= n || X < 0 || X >= m) {
solve(next + 1, y, x);
return;
}
roll(dir);
if (map[Y][X] == 0) map[Y][X] = dice[1];
else {
dice[1] = map[Y][X];
map[Y][X] = 0;
}
printf("%d\n", dice[3]);
solve(next + 1, Y, X);
}
solve라는 함수가 이제 문제를 푸는 재귀함수입니다. 인자 next는 다음 방향으로 이동하라는 인덱스입니다. 이것을 comand가 사용합니다.
command라는 배열은 어떻게 이동할지를 담고 있는 변수입니다. 동서남북 이동이 그것이죠. 동서남북 이동 입력이 1000개가 주어지니 command의 배열을 1000+1개로 잡아놓았습니다.
inc는 어떻게 주사위 위치를 증가할지를 담고 있는 변수입니다. inc는 방향에 따라서 (1,2,3,4) 1이이면 x축으로 1증가, 2이면 x축으로 1감소,.. 이런 식입니다.
solve함수에서 만일 범위 밖이면 다음 명령어를 실행하죠. 그것이 조건문에 걸려있군요. 조건에 걸리지 않았다면 주사위를 방향에 따라 굴리고, 이동했던 판의 숫자가 0이면 주사위의 아랫면의 숫자를 판에 복사하며 그것이 아니라면 판의 숫자를 주사위의 아랫면에 복사하고 그 판의 숫자를 0으로 바꾸어줍니다. 그 후 이제 윗면의 수 dice[3]을 출력하면 되지요.
전체 코드는 아래와 같습니다.
#include <cstdio>
using namespace std;
int map[21][21], command[1001], n, m, k;
int perm[5][6] = {
{},
{ 0,5,2,4,1,3 },{ 0,4,2,5,3,1 },
{ 3,0,1,2,4,5 },{ 1,2,3,0,4,5 }
};
int inc[5][2]{ {},{ 0,1 },{ 0,-1 },{ -1,0 },{ 1,0 } };
int dice[6];
void roll(int d) {
int temp[6];
for (int i = 0; i < 6; i++)
temp[i] = dice[perm[d][i]];
for (int i = 0; i < 6; i++)
dice[i] = temp[i];
}
void solve(int next, int y, int x) {
if (next == k) return;
int dir = command[next];
int Y = y + inc[dir][0], X = x + inc[dir][1];
if (Y < 0 || Y >= n || X < 0 || X >= m) {
solve(next + 1, y, x);
return;
}
roll(dir);
if (map[Y][X] == 0) map[Y][X] = dice[1];
else {
dice[1] = map[Y][X];
map[Y][X] = 0;
}
printf("%d\n", dice[3]);
solve(next + 1, Y, X);
}
int main() {
int y, x;
scanf("%d %d %d %d %d", &n, &m, &y, &x, &k);
for (int i = 0; i < n; i++)
for (int j = 0; j < m; j++)
scanf("%d", &map[i][j]);
for (int i = 0; i < k; i++) scanf("%d", &command[i]);
solve(0, y, x);
}
'알고리즘 > 삼성 SW 역량 테스트' 카테고리의 다른 글
| [삼성 SW 역량테스트] 백준 온라인 저지(BOJ) 14500번 테트로미노 (0) | 2019.04.08 |
|---|

REAKWON
와나진짜







