문제에서 말하는 오등큰수는 이 수가 나타난 수보다 더 많이 나타난 수 중 가장 가까운 오른쪽 수를 의미합니다. 특정 수의 오등큰수가 없을 수가 있습니다. 이런 경우 그 수의 오등큰수는 -1로 정해줍니다. 문제의 예제는 이렇습니다.
A = [1, 1, 2, 3, 4, 2, 1]
우선 F(Ai)는 빈도수라고 하여 차례대로 빈도수를 구하면 이렇게 되겠네요.
F(1) = 3, F(2) = 2, F(3) = 1, F(4) = 1
이렇게 빈도수가 구해지면 NGF라는 오등큰수를 구할 수 있습니다. NGF(1)을 구하는데, 1보다 빈도수가 큰 수는 없으므로 NGF(1) = -1이 됩니다. NGF(2) = 1이됩니다. 왜냐면 2보다 빈번하게 나타난 수는 1이고 이 수가 가장 가까운 오른쪽에 있는 수가 되기 때문이죠. 예제의 답은 그래서 아래와 같습니다.
-1 -1 1 2 2 1 -1
풀이
이 문제는 스택으로 풀 수 있습니다. 우선 F(Ai)를 구해야하는데요. 이건 간단합니다. 비어있는 배열 F에 입력받은 수를 index삼아서 하나씩 증가시키면 되기 때문입니다. 이제 F를 구했으면 스택을 이용해서 본격적으로 문제를 풀어봅시다.
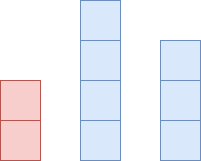
아래의 블록은 F를 나타냅니다. 높을 수록 F가 높다는뜻입니다.
왼쪽의 빨간 블록의 오등큰수를 구하려면 오른쪽에서 찾아야합니다. 그런데 자신보다 큰 오등큰수가 두개가 있습니다. 4와 3이 있네요. 이때 빨간색의 오등큰수는 4가 됩니다. 이때 3은 이 다음 왼쪽 수의 오등큰수가 될 수 있을까요? 이미 4한테 막혀있고 4가 더 큰값이기 때문에 가능성이 없습니다. 그래서 3은 지워버립니다. 대신 4가 왼쪽의 오등큰수가 될 수 있는것을 알 수 있네요.
따라서 현재 자신보다 큰 값의 오등큰수가 존재하면 스택에 저장하고 작거나 같으면 스택에서 지워버리는 식으로 문제를 풀 수 있습니다.
코드
문제 해답에 대한 전체코드는 아래와 같습니다.
#include <cstdio>
#include <stack>
using namespace std;
int n;
int F[1000001], ans[1000001], nums[1000001];
stack<int> st;
int main() {
scanf("%d", &n);
for (int i = 0; i < n; i++) {
scanf("%d", &nums[i]);
F[nums[i]]++;
}
for (int i = n - 1; i >= 0; i--) {
int number = nums[i];
int height = F[number];
while (!st.empty()) {
int topNum = nums[st.top()];
int topHeight = F[topNum];
if (height >= topHeight) st.pop();
else break;
}
ans[i] = -1;
if (!st.empty()) ans[i] = nums[st.top()];
st.push(i);
}
for (int i = 0; i < n; i++)
printf("%d ", ans[i]);
printf("\n");
}
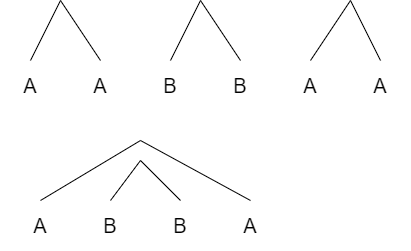
같은 글자를 짝지어 주는 문제입니다. 아치형으로 서로 짝을 지어주고 모든 짝을 지어줄 수 있다면 그 단어는 좋은 단어라고 합니다. 단, 아치형이 서로 겹치지 않게 짝을 이뤄줘야합니다. 아래의 그림을 보면 바로 이해가 가실겁니다.
다음의 경우에는 좋은 단어입니다. 아치형이 겹치지 않죠
좋은단어
아래의 경우는 아치가 겹치므로 좋은단어가 아닙니다.
안좋은 단어
풀이
이 문제의 힌트는 바로 스택을 활용한 괄호 짝 맞추기 문제입니다. 가장 최근에 나온 짝이 자신의 짝인지 확인하는 문제와 컨셉이 같은데요. 여기서 괄호( '(', ')' )만 살짝 'A','B'로 바꾼것일 뿐입니다.
ABBA를 예로 들겠습니다.
1. A는 스택이 이미 비어있으니 스택에 집어넣습니다. (현재 스택 - A)
2. B는 스택 꼭대기 글자가 A이므로 B는 스택이 저장합니다. (현재 스택 - A B)
3. B는 스택 top의 글자가 B이므로 이전의 B를 스택에서 pop합니다. (현재 스택 - A)
4. A는 현재 스택 top의 글자와 같으므로 A를 스택에서 pop합니다. (현재 스택 - ' ' )
코드
아래는 전체 문제 풀이 코드입니다.
#include <cstdio>
#include <stack>
#include <string.h>
using namespace std;
char str[100001];
int n;
int main() {
int ans = 0;
scanf("%d", &n);
for (int i = 0; i < n; i++) {
scanf("%s", str);
stack<char> st;
int m = strlen(str);
for (int j = 0; j < m; j++) {
if (!st.empty()&&st.top()==str[j]) st.pop();
else st.push(str[j]);
}
if (st.empty()) ans++;
}
printf("%d\n", ans);
}
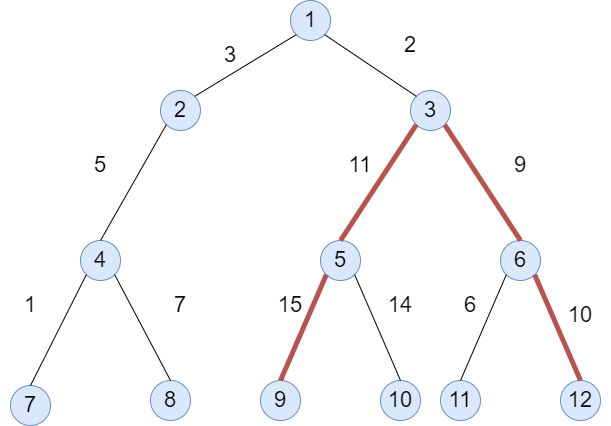
이 문제는 가중치가 주어진 트리에서 leaf과 leaf 사이, 혹은 루트와 leaf 사이의 모든 가중치의 합 중 가장 큰 값을 구하는 문제입니다.
예제에서 주어진 그래프에서는 45의 값으로 답이 됩니다. 빨간색 선을 따라가면 9 - 5 - 3 - 6 - 12의 노드를 지나게 되고 가중치 합은 45라는 것을 알 수 있습니다. 이 값보다 큰 값은 존재하지 않습니다.
이 문제는 트리를 사용하여 풀 수 있습니다. 트리의 잎부터 시작해 올라오면서 서브트리의 양쪽 잎까지의 가중치 합과 서브트리의 루트와 잎까지 합중 가장 큰 값으로 계속 업데이트를 하면 됩니다.
설명 및 전체 코드
입력받은 값으로 트리를 구성해야하는데, 이때 Node라는 구조체로 노드를 만들겠습니다. 이 Node 구조체는 자식 Node들을 가지고 있고, 부모로 향하는 weight값을 가지고 있는 구조체로 정의되어 있습니다. 노드의 자식은 여러개일 수 있으므로 vector를 사용했습니다.
typedef struct Node {
vector<Node*> children = vector<Node*>();
int weight;
};
기저사례로는 자식이 없을 경우 바로 부모로 향하는 weight를 return해줍니다. 더 이상 진행할 필요가 없으니까요. 그리고 자식이 한개일 경우에는 weight와 그 밑으로 향하는 큰 값중 하나를 더해서 반환해주면 됩니다.
if (root->children.size() == 0) return root->weight;
if (root->children.size() == 1)
return root->weight + traverse(root->children[0]);
그 외에는 자식이 둘 이상이겠죠. 양쪽으로 분기되는 값 중 가장 큰 값 두개를 선택해서 더해준 값을 현재까지 업데이트된 값하고 비교하여 둘 중 가장 큰 값으로 업데이트해줍니다. 현재까지 업데이트된 값을 value라고 임시로 정해줍시다.
이 과정을 루트로 올라올때까지 진행해주면 답을 구할 수 있습니다. 아래는 정답 코드입니다.
#include <cstdio>
#include <vector>
#include <algorithm>
using namespace std;
int n;
typedef struct Node {
vector<Node*> children = vector<Node*>();
int weight;
};
Node nodes[10001];
int value = 0;
int traverse(Node *root) {
//자식이 없는 경우 부모쪽으로 가는 간선의 값 return
if (root->children.size() == 0) return root->weight;
//자식이 하나일 경우 자신의 weight을 더해 return
if (root->children.size() == 1)
return root->weight + traverse(root->children[0]);
//여기서부터는 자식이 둘 이상
vector<int> weights = vector<int>(root->children.size());
//자식들 모두 다 돌때까지
for (int i = 0; i < root->children.size(); i++)
weights[i] = traverse(root->children[i]);
//오름차순으로 정렬
sort(weights.begin(), weights.end());
//가장 큰 값을 가진 두 값을 더해서 value와 비교하여 value업데이트
value = max(weights[root->children.size()-1]
+ weights[root->children.size()-2], value);
//현재의 weight와 다 더한값의 제일큰 weights값을 더하여 return
return root->weight+weights[root->children.size()-1];
}
int main() {
scanf("%d", &n);
nodes[1] = Node();
nodes[1].weight = 0;
n--;
for (int i = 0; i < n; i++) {
int from, to, weight;
scanf("%d %d %d", &from, &to, &weight);
nodes[to] = Node();
nodes[to].weight = weight;
nodes[from].children.push_back(&nodes[to]);
}
int ret = max(value, traverse(&nodes[1]));
printf("%d\n", ret);
}
어떤 수열이 있는데요. 이 수열의 한 원소를 기준으로 오른쪽에 있는 자신보다 큰 원소 중 가장 왼쪽에 있는 수가 오큰수라고 합니다. 이때 수열에 대해 모든 원소의 오큰수를 구하는 것이 문제입니다.
이때 오큰수가 없는 경우도 있습니다. 가장 큰 원소이거나 가장 오른쪽에 있는 원소는 오큰수가 없을 수가 있죠. 이때는 -1로 오큰수를 정해줍니다.
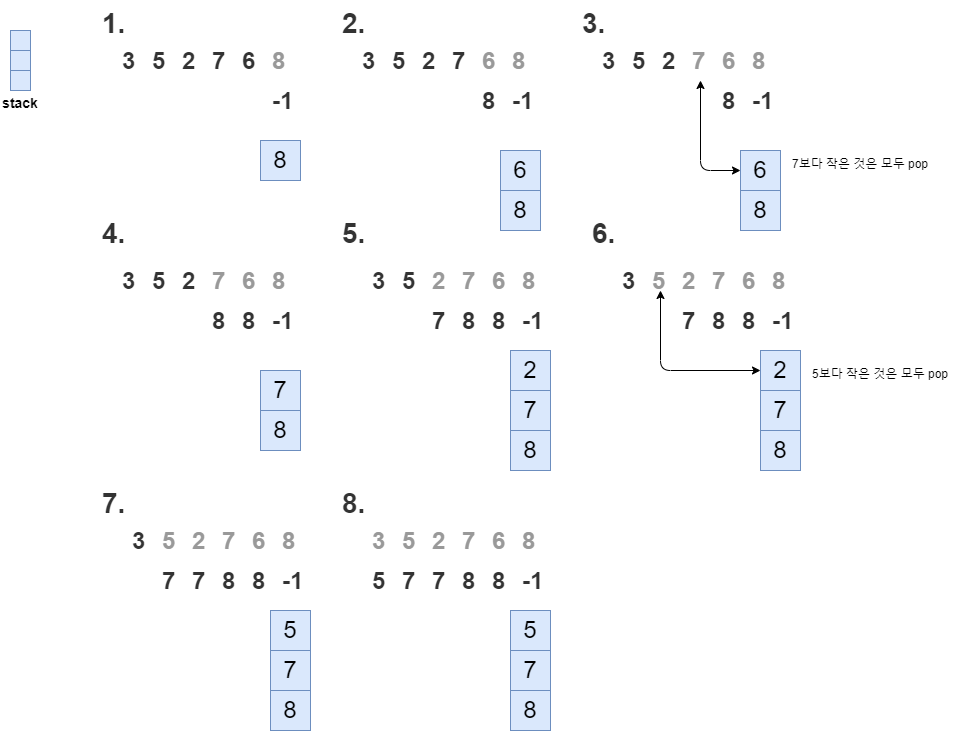
예를 들어 3 5 2 7 6 8이라는 수열이 있다면 5 7 7 8 8 -1이 해답이 됩니다. 5의 오른쪽에 있는 큰 수들은 7 6 8이 있는데, 이때 가장 왼쪽에 있는 수가 7이므로 5의 오큰수는 7이 됩니다. 여기까지 이해를 했으면 이제 문제를 풀어보겠습니다.
풀이
이 문제에 대해서 왼쪽부터 시작하지 말고 오른쪽부터 시작하면 접근이 쉽습니다. 가장 오른쪽에 있는 오큰수는 없으니까 -1로 시작하게 됩니다.
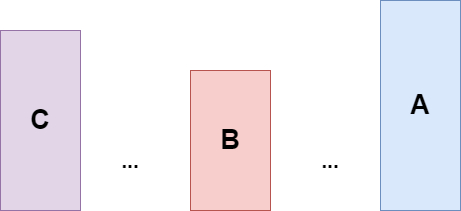
가장 최근에 큰 수(A)을 기억하고 있다가 그것보다 작은 수(B)가 나오게 되면 B의 오큰수는 A가 됩니다. 이때 B는 그냥 버리면 안됩니다. 왜냐면 B가 왼쪽 어떤 C의 오큰수 일 수 있으니까요. 그래서 B를 기억하고 있어야합니다. 아래와 같은 상황에서 B는 C의 오큰수가 됩니다. 이때 C도 역시 기억하고 있어야됩니다. C도 어떤 수의 오큰수가 될 수 있게 되니까요. 아래의 그림은 이해하기 쉽게 도형의 크기로 수의 크기를 표현하였습니다.
하지만 C가 B보다 큰 경우 B는 오큰수가 아니게 되겠죠? C 이전의 수들은 B가 필요없게 됩니다. 왜냐면 C가 B보다 크면서 더 왼쪽에 있으니까요. 그래서 B는 이제 기억에서 사라지고 C를 기억하고 있어야됩니다.
자, 이제 뭔가 좀 감이 잡힐 수 있습니다. 가장 최근에 것을 상황에 따라 보관하고 있다가 비교하거나 버리고 하는 것을 알 수 있게 됩니다. 그래서 스택이라는 자료구조가 이 문제에서 사용됩니다.
Stack에는 가장 오른쪽부터 시작해서 오큰수들이 들어가게 됩니다. 이때 value는 현재 수열의 비교할 값을 말한다고 합시다. 스택의 가장 위(top)는 어떠한 오큰수가 들어가게 되는데, value보다 작다면 이 오큰수는 쓸모가 없게 되므로 스택에서 pop하면 됩니다. stack의 top이 value보다 더 클때까지 계속 pop하게 되면 결국 stack이 비게 되거나, value보다 큰 오큰수가 존재하게 됩니다.
이때 스택이 비어있다면 value의 오큰수가 없다는 것, 비어있지 않다면 스택에 있는 top의 값이 오큰수가 되게 됩니다.
위 설명을 따른 예제에 대한 그림 풀이가 아래에 있습니다. 참고하시기 바랍니다.
전체코드
전체 코드는 아래와 같습니다. 주석처리하여 추가설명하였습니다.
#include <cstdio>
#include <stack>
using namespace std;
int n, numbers[1000001], ans[1000001];
int main() {
stack<int> st = stack<int>();
scanf("%d", &n);
for (int i = 0; i < n; i++)
scanf("%d", &numbers[i]);
st.push(numbers[n - 1]); //가장 오른쪽에 있는 수는 stack에 push
ans[n - 1] = -1; //가장 오른쪽의 있는 수는 오큰수가 없으므로 -1
for (int i = n - 2; i >= 0; i--) { //거꾸로 for문
int value = numbers[i]; //stack의 top과 비교할 숫자
while (!st.empty() && value >= st.top()) { //스택이 비어있지 않고, 스택의 top이 value보다 작거나 같으면
st.pop(); //그 수는 버린다.
}
//이렇게 되면 두가지 상황이 발생하는데,
//스택이 비어있으면 value 오른쪽에 오큰수가 없다는 것으로 value의 오큰수는 -1
//숫자가 남아있다면 value보다 큰 수가 있는 것으로 오큰수는 st.top
ans[i] = st.empty() ? -1 : st.top();
//그리고 value를 stack에 push
st.push(value);
}
for (int i = 0; i < n; i++) printf("%d\n", ans[i]);
printf("\n");
}
리눅스에서도 비슷한 의미로 쓰이는 것 같아요. 왜 비슷한 의미로 쓰이는 지는 포스팅을 보시면서 느껴보시기 바랍니다.
요즘 컴퓨터들보면 CD를 넣었을때나 DVD를 넣었을때, 그리고 USB를 넣었을때 시스템이 자동으로 인지하고 실행시키거나 읽어주죠? 너무 편리합니다. 하지만 이전에 시스템, 혹은 가벼운 전자 제품에 리눅스와 같은 커널을 사용할 경우 시스템이 저절로 인식하지 못할 수도 있습니다. USB나 CD를 넣었을때 인식하고 사용하기 위해서 필요한 명령어가 바로 mount 명령입니다. 간단하게 USB를 mount해보도록 합시다.
USB mount 해보기
0. 먼저 mount를 그냥 치게되면 현재 마운트된 시스템의 하드웨어들이 보이게 될겁니다. 그 중 sda, sdb 등이 디스크라고 보시면 됩니다. 아래는 저의 시스템에 마운트된 sda입니다.
1. 옹골진 USB를 일단 꽂습니다.핡
2. fdisk -l로 USB 메모리가 꽂힌 블록 디바이스 파일(/dev/ 밑에 있는 파일) 이름을 확인합니다. sda, sdb, sdc,, ... 처럼 앞에 'sd'가 붙는 것이 일반적입니다. 가장 간단하게 확인할 수 있는 것은 새로 생긴 sd*를 보고 용량을 보면 알 수 있습니다. 참고로 USB가 128G 용량이라고 해서 128G 온전히 다 잡히지는 않습니다. 한 116G정도로 약간 적게 잡힙니다.
제 경우에는 sdb1이라는 이름입니다.
3. 아래의 명령으로 mount합니다.
mount [-t file_system_type] [USB로 인식된 블록 디바이스 파일] [마운트 지점]
앞에 file_system_type은 생략 가능한데, 리눅스가 그 파일 시스템을 지원할때 가능합니다. 그것이 아니라면 명시적으로 지정해주어야합니다. 물론 리눅스 파일 시스템인 ext계열 파일 시스템은 지원가능하지만 윈도우즈(ntfs)의 파일 시스템의 경우나 CD-Rom을 위한 파일 시스템(iso9660)은 지원하지 않을 수 있습니다.
저의 usb의 경우에는 FAT32 파일 시스템을 사용하고, 혹시 지원하는지 확인하기 위해서 그냥 -t 옵션 사용하지 않고 해본 결과 잘되는 것을 확인했습니다.
mount /dev/sdb1 /tmp/usb
파일 시스템(File System)이란?
사실 말이 어려워서 File System이지, 간단하게 생각하면 별거 없습니다. 자, 여러분이 책을 정리할때를 생각해보세요. 저같은 경우는 일단 책을 보지 않습니다. 어떤 사람은 책꽂이 맨윗줄은 만화책, 그리고 그 다음 줄에는 전공서적, 그리고 그 다음 줄은 소설책 등으로 카테고리를 정리할 수 있습니다. 그리고 각 카테고리마다 또 사전순으로 책을 잘 정리하겠죠. 그래서 만약 "원피스"라는 만화책을 찾으려면 맨 윗줄, 'ㅇ'으로 시작되는 만화책 부분을 찾으면 되겠군요. 그리고 다 본후에는 다시 원위치에 꽂아서 넣으면 됩니다. 이렇게 책을 관리하는 나름대로의 체계가 있듯이 컴퓨터도 파일을 정리할때 체계가 존재합니다. 그래서 어떻게 파일을 삭제하고, 파일을 기록하고, 찾는지 등을 쳬계화해놓은 것이 File System이라고하며 저장 매체나 OS마다 각기 다른 파일 시스템을 사용하고 있습니다. 여러분이 책 정리할때 반드시 위의 사람과 같이 정리하지는 않듯이 말이죠.
여기서 간략하게 OS마다 어떤 파일 시스템을 갖는지만 살펴보도록 하지요. Linux : ext, ext2, ext3, ext4, xfs Windows : FAT12, FAT16, FAT32, exFAT, NTFS Mac : HFS, HFS+
한가지 자주쓰이는 옵션은 -r옵션인데요. 파일을 오직 읽기(read-only)만 하는 용도로 사용하겠다는 옵션입니다. 예를들어 CD겠죠? CD에 파일을 추가하거나 삭제할 수는 없으니까요. 또한 민감하거나 삭제되지 말아야할 경우에 쓰이기도 합니다. -o ro와 같은 옵션이기도 합니다.
혹시 mount에서 read-only로 마운트된 것을 read, write 가능하게 바꾸려면 아래의 명령을 사용하시면 됩니다. 단, rw가 가능한 파일시스템에 대해서만 입니다. CD-ROM은 당연안됩니다.
mount -o rw,remount [마운트지점]
4. 마운트를 해제할 경우 umount 명령을 사용하여 해제할 수 있습니다.
umount [마운트 지점]
그래서 umount /tmp/usb라는 명령어로 마운트 해제할 수 있습니다.
여기서 한가지 의문점이 들지 않나요?
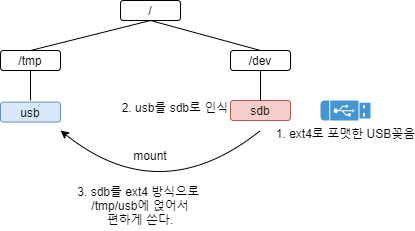
왜 굳이 mount해서 쓰는 거지? 어차피 /dev/sdb1와 같이 자동으로 인식해주는데, 뭐하러 디렉토리를 만들고 mount하고 쓰는 것일까?
여러분이 기억하셔야할 점은 리눅스에서 모든 장치들은 파일로 취급한다는 점입니다. sdb 역시 파일로 인식되지요. 그래서 'cd /dev/sdb'와 같은 명령으로 디렉토리같이 사용할 수 없다는 것입니다. 또 어떻게 파일을 추가하고, 파일을 추가할때 이름은 몇자까지 제한이 되며, 파일을 삭제할때는 어떻게 삭제하는지도 모릅니다. 이러한 동작 방식들은 파일 시스템에서 정의하고 있기 때문입니다. 그렇기 때문에 우리는 파일 시스템을 명시하여 파일의 동작(operation)을 알려주면서 USB를 사용할 수 있게 됩니다(물론 아까도 말씀했다시피 지원되는 파일 시스템은 명시적으로 지정해주지 않아도 알아서 파일 시스템을 찾아줍니다.).
그래서 mount 명령어로 인식된 sdb에 대해서 파일이 동작하는 방식은 파일 시스템을 딱 알려주고 이것을 /tmp/usb 디렉토리에 얹어 쓰겠다고 리눅스에게 말해주는 것이죠. (아래 그림에서 sdb가 아니고 sdb1입니다.)
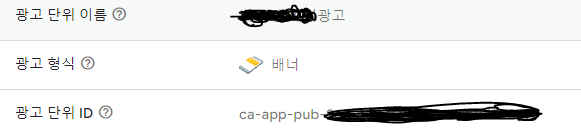
애드몹을 쓰던 중, 잘만 나오던 광고가 아래 오류가 어느 순간 갑자기 나오기 시작하면서 테스트 배너 광고가 나오지 않았습니다. 그래서 어떤 오류인가 했더니 아래와 같은 오류였네요.
광고 요청은 성공(그러니까 구현에는 문제가 없다는것)했는데, 인벤토리에 광고가 없어서 광고를 못보여준다고합니다. 어, 하지만 스토어에 있는 내 앱에는 광고가 잘 나오는데요? 저의 증상은 출시 앱에는 광고가 잘 나오고, 오히려 테스트 ID를 써서 앱 개발할때에는 테스트 광고가 나오지 않는 것이었습니다.
구글링을 해보니 광고가 잘 나오다가 이와 같은 증상을 겪은 사람들의 공통점이 어느 순간 갑자기 안나온다는 것이었습니다. 몇가지 조치할 수 있는 방법이 있는데 한번 확인해보세요.
1. 구글 플레이 스토어에 구글 광고가 포함되어있다고 체크했는지 확인
구글 플레이 콘솔 -> 출시 앱 선택 -> 왼쪽 하단 앱 콘텐츠 선택 -> 중간쯤에 광고란 확인
2. 부정클릭이 발생했는지 확인. 이 경우 30일간 광고가 일시 정지되거나 영구정지 될 수도 있다고 하네요. 어떤 경우라고 자신의 광고를 클릭하지 맙시다.
3. app-ads.txt를 추가하고 테스트 기기 등록했는지 확인
저의 경우는 3번이었습니다. 갑자기 안나온것이라 생각했는데, 기억을 더듬어 보니 app-ads.txt를 추가한 이후에 테스트 광고가 안나오는 것이었어요. 역시 나만 갑자기라고 생각했나봐요..
이 방법은 바로 적용이 가능한 방법입니다. 저는 바로 확인을 원하기 때문에 2번, 테스트 기기를 등록하는 방법을 사용할 것입니다.
그래서 이번 포스팅은 안드로이드 테스트 디바이스를 설정하는 방법에 대한 것입니다. 이때 테스트 광고 ID를 쓰는 것이 아니고 발급받은 ID를 사용해야한다는 점입니다.
아래의 코드를 추가하세요.
MobileAds.initialize(this);
//앱 출시시 반드시 주석 처리
List<String> testDeviceIds = Arrays.asList("Your Device ID");
RequestConfiguration configuration =
new RequestConfiguration.Builder().setTestDeviceIds(testDeviceIds).build();
MobileAds.setRequestConfiguration(configuration);
//앱 출시시 반드시 주석 처리
Arrays.asList에는 자신의 고유 Device ID를 기재해주어야합니다. 어떻게 아냐구요? 안드로이드 스튜디오 Logcat에 나와있습니다.
I/Ads: Use RequestConfiguration.Builder.setTestDeviceIds(Arrays.asList("33BE2250B43518CCDA7DE426D04EE231"))
to get test ads on this device."
Logcat에서 RequestConfiguration을 검색하여 찾아보세요.
다음으로 중요한 것은 Test 광고 ID를 사용하는 것이라고 했죠? adUnitId를 발급받은 광고 ID로 바꿔주세요.
2. 아까 다운 받은 그 폴더를 설정해주고 Finish를 누르면 됩니다. 아래 사진에서는 Module Name이 :nativetemplate이지만 :nativetemplates로 해주셔야해요. 저는 어떤 이유인지는 모르겠지만 Finish가 활성화되어있지 않고 이 방법으로 모듈을 Import할 수 없었습니다.
다른 방법으로 Import
1. 아래와 같이 다운받은 폴더를 같은 프로젝트에 둡니다.
2. settigs.gradle 파일에 nativetemplates를 추가시켜줍니다.
프로젝트 수준의 settigns.gradle
include ':app',':nativetemplates'
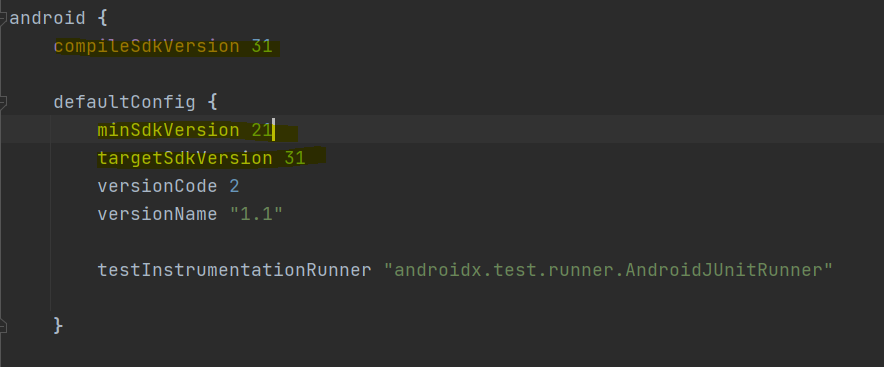
3. 한가지 추가적으로 nativetemplates의 build.gradle의 버전을 맞춰줘야합니다. 자신의 기존 프로젝트와 같이 sdk버전을 맞춰주시면 됩니다. 그리고 sync를 눌러주세요.
Calendar 클래스는 날짜와 시간을 다루기 위해서 Date와 함께 많이 쓰이는 클래스 중 하나입니다. Calendar를 사용하기 위해서는 java.util.Calendar를 import 시켜야합니다.
가장 기본적으로 현재 날짜와 시간을 가져올 수도 있고, 특정 시간으로 시간을 되돌리거나 뒤로갈 수도 있습니다. 이는 Calendar에서 제공하는 상수들을, 예를 들면 YEAR, MONTH, DAY_OF_MONTH등을 이용하여 설정할 수 있습니다. 어떤 필드가 있는지 볼까요? 아래의 필드를 이용해서 get, set 메소드를 통해 값을 얻어오거나 설정할 수 있습니다.
Field(static int)
설명
YEAR
년도를 나타냅니다.
MONTH
월을 나타내는데, 이때 1월을 상수 0으로 대응이 됩니다. 그래서 실제 월을 구할때는 +1을 해주어야합니다.
DATE, DAY_OF_MONTH
월의 날짜를 의미합니다.
DAY_OF_WEEK
일주일에 해당되는 요일을 의미합니다. 일요일부터 시작이며 일요일은 1입니다. 수요일은 4의 값을 갖습니다.
HOUR
시간을 표시하는데 12시간 단위의 시간을 의미합니다.
HOUR_OF_DAY
시간을 표시하는데 24시간 단위의 시간을 의미합니다.
MINUTE
분을 의미하는 필드입니다.
SECOND
초를 의마하는 필드입니다.
MILLISECOND
밀리 세건드 단위를 의미하는 필드입니다.
아래의 필드는 get, set으로 얻지는 않고 비교할때 사용할 수 있습니다.
Field(static int)
설명
JANUARY
1월을 나타냅니다. 0의 값을 갖고 있습니다. 월을 나타내는 필드는 전부 대문자입니다. 2월을 FEBURARY, 3월은 MARCH입니다. 각 숫자는 월-1에 값을 갖습니다.
SUNDAY
일요일에 해당하는 값이며 1을 가집니다. 요일을 나타내는 상수도 마찬가지로 전부 대문자로 표시할 수 있으며 SUNDAY의 1부터 SATURDAY의 7까지 나타낼 수 있습니다.
이번 포스팅에서는 Calendar클래스를 어떻게 사용하고 다루는지 예를 통해서 설명하도록 하겠습니다.
1. 현재 시간의 정보를 표시하는 예제
public static void main(String[] args){
Calendar cal=Calendar.getInstance(); //getInstance()로 객체 생성
System.out.println("현재 날짜:"+cal.get(Calendar.YEAR)+"-"+(cal.get(Calendar.MONTH)+1)+"-"+cal.get(Calendar.DAY_OF_MONTH));
System.out.println("일주일 중 오늘은 "+cal.get(Calendar.DAY_OF_WEEK)+"번째 요일 (1은 일요일)");
System.out.println("일년 중 오늘은 "+cal.get(Calendar.DAY_OF_YEAR)+"번째 날");
System.out.println("현재 시간 "+cal.get(Calendar.HOUR_OF_DAY)+":"+cal.get(Calendar.MINUTE)+":"+cal.get(Calendar.SECOND)+":"+cal.get(Calendar.MILLISECOND));
System.out.println("현재 시간 "+cal.get(Calendar.AM_PM)+":"+cal.get(Calendar.MINUTE)+":"+cal.get(Calendar.SECOND));
System.out.println("이번 주는 일년 중 "+cal.get(Calendar.WEEK_OF_YEAR)+"번째 주");
}
Calendar객체는 new 키워드로 객체를 생성할 수 없고 getInstance() 메소드로 객체를 생성할 수 있습니다. 위 예제는 현재 날짜와 시간을 나타내며 위에 설명한 표의 데이터가 어떤 값을 나타내는 지 확인하는 예제입니다.
현재 날짜:2021-10-20
일주일 중 오늘은 4번째 요일 (1은 일요일)
일년 중 오늘은 293번째 날
현재 시간 19:36:39:959
현재 시간 1:36:39
이번 주는 일년 중 43번째 주
2. set 메소드로 날짜 설정
public static void main(String[] args){
Calendar cal=Calendar.getInstance(); //getInstance()로 객체 생성. 기본 현재 날짜
cal.set(Calendar.MONDAY,Calendar.DECEMBER); //12월로 설정
cal.set(Calendar.HOUR_OF_DAY,14); //오후 2시로 Calendar 객체 설정
System.out.println("설정된 날짜 - "+(cal.get(Calendar.MONTH)+1)+"월 "+cal.get(Calendar.DATE)+"일");
System.out.println("설정된 시간 - "+cal.get(Calendar.HOUR_OF_DAY)+":"+cal.get(Calendar.MINUTE)+":"+cal.get(Calendar.SECOND));
}
이번에는 set 메소드로 month와 hour를 설정해보았습니다. 아래처럼 원래의 date와 minute, second는 현재의 시간과 동일하며 month와 hour만 바뀐 것을 알 수 있네요.
설정된 날짜 - 12월 20일
설정된 시간 - 14:43:55
이렇게 개별적으로 바꿀 수도 있습니다만, 만약 한꺼번에 바꾸고 싶다고 하면 오버로딩된 set메소드를 활용하시면 됩니다.
public static void main(String[] args){
Calendar newYear=Calendar.getInstance();
newYear.set(2022,Calendar.JANUARY,1); //년, 월, 일 설정
System.out.println(newYear.get(Calendar.YEAR)+"년 "+(newYear.get(Calendar.MONTH)+1)+"월 "+newYear.get(Calendar.DATE)+"일");
newYear.set(2022,Calendar.JANUARY,1,0,0); //년, 월, 일, 시, 분 설정
System.out.println(newYear.get(Calendar.YEAR)+"년 "+(newYear.get(Calendar.MONTH)+1)+"월 "+newYear.get(Calendar.DATE)+"일");
System.out.println(newYear.get(Calendar.HOUR_OF_DAY)+"시 "+newYear.get(Calendar.MINUTE));
}
2022년 1월 1
2022년 1월 1
0시 0
3. 밀리초로 1970년 1월 1일 00시 00분부터 흐른 시간 구하기
public static void main(String[] args){
Calendar today=Calendar.getInstance(); //getInstance()로 객체 생성. 기본 현재 날짜
System.out.println("1970년 00시 00분부터 흐른 초 :"+today.getTimeInMillis()/1000);
SimpleDateFormat format=new SimpleDateFormat("a hh:mm:ss");
System.out.println("현재시간 "+format.format(today.getTimeInMillis())); //SimpleDateFormat으로 출력
Calendar newYear=Calendar.getInstance(); //현지 시간으로 설정
newYear.set(Calendar.YEAR, 2021);
newYear.set(Calendar.MONTH, Calendar.OCTOBER);
newYear.set(Calendar.DAY_OF_MONTH, 21);
long diff=newYear.getTimeInMillis()-today.getTimeInMillis();
Calendar dDay=Calendar.getInstance();
dDay.setTimeInMillis(diff); //1년 이내로만 이 코드를 쓸 수 있음
System.out.println("남은 날 수 :"+(dDay.get(Calendar.DAY_OF_YEAR)-1)); //오늘이 포함되므로 -1
diff=diff/(60*60*24*1000); //60(분) * 60(1분) * 24(시간) * 1(초) = 하루
System.out.println("남은 날 수 :"+diff);
}
getTimeInMillis를 통해서 밀리초단위로 구할 수 있습니다. 밀리초 단위로 SimpleDateFormat에 설정하여 더 쉽게 볼 수도 있고, 두 시간 사이의 계산도 가능합니다.
1970년 00시 00분부터 흐른 초 :1634727499
현재시간 오후 07:58:19
남은 날 수 :2
남은 날 수 :1
리눅스에서 파일을 다루는 방법은 세가지가 있습니다. 파일을 읽고(read), 쓰고(write), 실행(execute)하는 것이 그 세가지입니다. 리눅스는 서버용 멀티유저 운영체제이기 때문에 권한이 매우 중요합니다. 어떤 관리자는 특정 파일에 대해서 읽고 쓸 수 있는 권한이 있을 수 있고, 다른 관리자는 수정이 불가한 파일이 있을 수가 있겠죠. 이렇게 파일을 다룰 수 있게 리눅스에서는 파일의 속성을 줄 수가 있습니다.
ls -l 명령으로 exam.txt파일의 실행권한을 보도록 하겠습니다.
노란색으로 표시한 부분이 이 파일의 권한을 의미합니다. 이 파일을 만든 소유자는 ubuntu이고 ubuntu라는 그룹이라는 것도 알 수 있습니다.
-rw-rw-r--
-
r
w
-
r
w
-
r
-
-
파일 종류 -는 일반 정규 파일
소유자의 read 권한
소유자의 write권한
소유자의 실행권한 X
소유자 그룹의 read권한
소유자 그룹의 write권한
소유자 그룹의 실행권한X
다른 사용자의 read권한
다른 사용자의 write권한X
다른 사용자의 실행권한X
맨앞의 파일의 종류를 나타내는 '-'를 제외하고 권한의 '-'는 그 파일에 대한 해당 권한이 없다는 것을 의미합니다. 권한은 아까 세종류가 있다고 했는데 각각 이렇습니다.
r
read로 파일을 읽을 수 있는 권한입니다.
w
write로 파일을 수정할 수 있는 권한입니다.
x
execute로 파일을 실행할 수 있는 권한입니다. 파일에는 단순 기록하는 파일외에도 실행파일이 있기 때문에 이러한 권한이 필요합니다.
chmod 명령어
chmod는 파일의 권한을 바꿀 수 있는 명령어입니다. 명령어 형식은 이렇습니다.
chmod [파일에 추가거나 뺄 권한] [파일 이름]
만일 다른 유저들의 쓰기 권한을 추가하고 싶다면 아래의 명령으로 권한을 추가할 수 있습니다.
u+w의 앞 u는 사용자를 의미합니다. 여기서 +는 더한다는것을 알 수 있겠죠? 반대로 뺄때는 -를 씁니다. 마지막 글자 w는 어떤 권한인지를 말합니다. 읽기 권한을 추가하려면 r를 사용하면 되겠네요. 맨 처음 글자는 아래와 같습니다.
u
user의 앞글자로 소유자를 의미합니다.
g
group의 앞글자로 소유자의 그룹을 의미합니다.
o
other의 앞글자로 다른 유저들을 의미합니다.
여러 권한을 설정할때는 쉼표로 나열해주면 됩니다. 아래는 그룹과 다른 유저들에게 r,w를 더해주는 명령어의 예입니다.
chmod g+rw,o+rw file.txt
그리고 숫자로 권한을 일괄적으로 바꾸는 방법도 있습니다.
파일의 권한을 설명할때 rwxrwxrwx로 해도되지만 보통은 정수를 사용하여 권한을 이야기합니다. 앞에 rw-rw-r--는 숫자 664로 대응이 되는데, 왜 이렇게 되는걸까요? 세개를 묶어서 세비트로 표현하기 때문입니다.
r
w
-
r
w
-
r
-
-
1
1
0
1
1
0
1
0
0
4
2
0
4
2
0
4
0
0
두번째 줄은 이진수, 세번째 줄은 10진수로 표현했습니다. 그래서 rw-는 결국 이진수 110으로 되어 6이 됩니다. 그렇다면 rwx는 111이 되어서 7이겠네요.
아래는 chmod로 유저는 모든 권한을, 그룹 사용자는 읽기, 쓰기 권한을, 그리고 다른 사용자는 읽기 권한만 추가하는 명령어의 예입니다.
- chmod 764 a.out
그리고 setuid와 setgid, sticky의 비트를 사용하여 네자리로 표현할 수도 있습니다. 각각 setuid는 4, setgid는 2, sticky는 1로 대응이됩니다.
- chmod 4764 a.out
위 명령은 setuid를 설정하는 명령입니다. setuid와 setgid, sticky는 아래에 설명하도록 하겠습니다.
setuid
setuid를 설명하기에 앞서 리눅스에서는 유저를 id로 구별합니다. 두 종류가 있는데 아래와 같습니다.
UID (REAL UID) : 이는 실제 사용자 본인의 아이디를 표현한다고 해서 real id라고도 하면 uid라고 합니다.
EUID (EFFECTIVE UID) : 유효 사용자 아이디라고해서 프로그램이 실행될때 갖는 아이디를 말합니다. 즉, 실행시에 이 프로그램을 만든 사용자의 ID로 실행이 된다는 겁니다.
setuid의 예1)
그렇다면 setuid의 예를 하나 들어보도록 할까요? 아래와 같이 root가 파일 하나를 만들고 본인만 읽을 수 있게 만들어 놓았습니다.
그리고 root 사용자는 아래와 같은 코드로 이 파일을 읽는 코드를 짜서 실행파일을 만들었습니다.
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <fcntl.h>
int main(){
int fd=open("root_read_only.txt",O_RDONLY);
int n;
char buf[128];
printf("uid:%d\n",getuid()); //실제 사용자 ID
printf("euid:%d\n",geteuid()); //이 프로그램을 실행할때만 갖는 ID
n=read(fd,buf,sizeof(buf));
if(n<0){
printf("파일을읽을 수 없습니다. erorr code:%d\n",n);
exit(1);
}
printf("file content:%s\n",buf);
}
root 사용자가 이 실행파일의 주인이고 실행파일의 권한은 모든 사용자가 실행할 수 있게 만들었습니다.
이제 다른 사용자인 ubuntu가 이 read.out이라는 실행파일을 실행하게 되면 아래의 내용과 같이 나옵니다. 지금 현재 uid는 1000이고 euid도 1000이라서 root_read_only.txt를 볼 수 없습니다. 왜냐면 root_read_only.txt는 오직 root만 읽을 수 있게 설정했거든요.
이때 이 실행파일이 실행될때만 루트의 권한을 갖도록 하여 파일을 읽을 수 있게 하는 방법은 euid를 root로 설정하는 setuid를 주면 될텐데요. root 계정으로 그 권한을 줘보도록 하겠습니다. chmod u+s read.out으로 setuid를 줄 수 있고, 이때 rwsrwxrwx로 바뀌게 된것을 알 수 있습니다. 소유자의 실행권한인 s로 바뀐 것은 setuid가 설정되어 있는 파일이며 실행시에 파일의 소유자의 권한으로 실행된다는 것을 의미합니다.
이제 ubuntu라는 유저는 이 root_read_only.txt라는 파일을 읽을 수 있을까요? 그럴 수 있는지 read.out을 실행해보도록 합시다.
euid가 0으로 바뀐것을 확인할 수 있으면서 file의 내용을 읽어볼 수 있습니다.
setuid의 예2) passwd
setuid를 설명하기 위해서 임의로 제가 만든 하나의 예입니다. 리눅스에서 가장 대표적으로 setuid를 사용하는 실행파일은 /bin/passwd파일입니다. 이 파일은 사용자의 비밀번호를 바꾸는데, 필요한 명령어로 /etc/passwd를 수정해야합니다. 하지만 /etc/passwd는 절대 root만 수정할 수 있으므로 다른 사용자는 변경할 수가 없죠. 그렇지만 다른 사용자들이 비밀번호를 바꿀때 /etc/passwd를 수정해야하므로 수정 프로그램이 필요하고 그 파일이 바로 /bin/passwd파일입니다. /bin/passwd는 실행시에 루트권한으로 실행이되어 /etc/passwd파일을 수정할 수 있게 됩니다.
setgid
setgid 역시 비슷합니다. 실행시에 그룹의 권한을 갖는 다는 것인데요. 앞서 설명한 setuid와 개념은 비슷하며 그룹 권한에 s로 표시가 됩니다.
sticky비트
sticky비트는 다른 사용자가 자유롭게 디렉토리를 사용할 수 있도록 만드는 권한입니다. 원래 디렉토리도 디렉토리를 만든 사람만이 읽기, 쓰기가 가능합니다. 하지만 sticky를 쓰면 모든 사용자가 자유롭게 읽기, 쓰기가 가능합니다. 마치 공유폴더와 아주 비슷한 개념입니다. 이 권한은 디렉토리에만 해당되는 권한입니다. 예를 들어설명해볼까요?
아래와 같이 root는 공유폴더를 만들 목적으로 디렉토리를 하나 만들었습니다. 하지만 권한을 주지는 않았죠.
그래서 ubuntu라는 유저는 이 디렉토리에 파일을 기록하려고 했으나 아래와 같이 권한이 없다는 메시지를 받게 됩니다.
아래와 같이 root는 다른 유저에 대해서 sticky비트를 설정합니다.
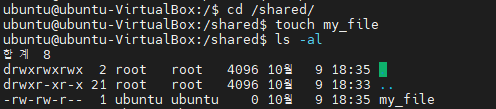
이렇게 되면 아래와 같이 ubuntu는 /shared 디렉토리를 자유롭게 이용할 수 있습니다.
여기까지 리눅스 파일의 실행권한과 setuid, setgid, sticky에 대한 개념을 알아보았습니다. 최대한 쉽게 예를 들어 설명하려고 했는데, 이해가 가셨는지 모르겠네요.