tm : 시간정보를 담은 tm구조체가 들어와야합니다. tm구초제는 아래와 같이 정의되어있습니다.
struct tm {
int tm_sec; /* 초 (0-60) */
int tm_min; /* 분 (0-59) */
int tm_hour; /* 시간 (0-23) */
int tm_mday; /* 월의 일 (1-31) */
int tm_mon; /* 월(0부터 시작) (0-11) */
int tm_year; /* 년 */
int tm_wday; /* 주의 일 (0-6, Sunday = 0) */
int tm_yday; /* 년의 일 (0-365, 1 Jan = 0) */
int tm_isdst; /* Daylight saving time */
};
반환: 성공시 문자열의 크기, 실패시 0이 반환됩니다.
format의 문자는 매우 다양합니다. 아래의 표로 정리하긴했지만, 이것보다 훨씬 많습니다. 여기에 나오지 않는 format문자는 인터넷 서치하시거나 매뉴얼 페이지를 보시기바랍니다.
프로세스 간 통신 방식인 IPC기법 중 하나인 메시지 큐는 두 가지 사용 방법이 있습니다. msgget, msgsend, msgrecv와 같은 함수를 사용하는 방식인 System V 방식의 메시지큐, 그리고 지금 알아볼 mq_open, mq_send, mq_recv와 같은 함수를 사용하는 방식인 POSIX 방식이 있습니다.
System V의 메시지 큐를 사용하는 방법과 예제를 보시려면 아래의 포스팅을 방문하여 확인해보세요.
System V는 옛날 유닉스 방식으로 보시면 되구요. 이후에 나온것이 POSIX입니다. POSIX는 Portable Operating System Interface라고 해서 이식 가능 운영체제 인터페이스라고 합니다. 리눅스가 POSIX를 준수하는 운영체제이구요.
우선 다음의 헤더파일들이 필요합니다.
#include <fcntl.h> /* For O_* constants */
#include <sys/stat.h> /* For mode constants */
#include <mqueue.h>
컴파일할때는 -lrt로 링크를 걸어줘야하구요. 아래에서 코드를 실행하고 컴파일할때 다 설명할겁니다.
1) mq_open
mqd_t mq_open(const char *name, int oflag);
mqd_t mq_open(const char *name, int oflag, mode_t mode, struct mq_attr *attr);
메시지 큐를 여는 함수로 2개가 존재하네요. mode와 메시지 큐의 속성을 정의하는 attr도 같이 넘겨줄수 있는 함수가 따로 존재합니다.
name : 메시지 큐 이름을 지정합니다.
oflag : 메시지큐에 옵션을 줄 수 있습니다. 아래와 같은 flag들이 존재합니다. 아래의 flag를 쓰려고 fcntl.h 파일을 include해야하는 겁니다.
flag
설명
O_RDONLY
읽기(메시지 받기:recv) 전용으로 메시지 큐를 엽니다.
O_WRONLY
쓰기(메시지 전송:send) 전용으로 메시지 큐를 엽니다.
O_RDWR
읽기, 쓰기 전용으로 메시지 큐를 엽니다.
O_CLOEXEC
close-on-exec이라고 하여, exec시 메시지큐를 닫습니다.
O_CREAT
메시지 큐가 존재하지 않으면 메시지큐를 생성합니다. 이 플래그를 사용하려면 두가지 인자가 추가로 더 필요한데 그게 바로 mode와 attr입니다.
O_EXCL
O_CREAT과 같이 사용하여 이미 파일이 존재하면 EEXIST에러를 발생시킵니다.
O_NONBLOCK
비블록 형식으로 메시지큐를 엽니다. mq_send나 mq_receive시에 메시지가 없으면 지속적으로 기다리게 되는데, 이 플래그를 사용하면 기다리지 않습니다.
mode : O_CREAT과 같이 사용합니다. 메시지큐를 만들때 권한을 설정합니다.
attr : mq_attr의 포인터로 다음과 같이 정의되어있습니다. 메시지큐의 속성을 지정하는데, 최대 메시지수, 최대 메시지 사이즈(바이트) 등을 정할 수 있습니다.
struct mq_attr {
long mq_flags; /* Flags (ignored for mq_open()) */
long mq_maxmsg; /* Max. # of messages on queue */
long mq_msgsize; /* Max. message size (bytes) */
long mq_curmsgs; /* # of messages currently in queue
(ignored for mq_open()) */
};
반환 : 만약 메시지큐가 올바르게 생성되었다면 메시지큐를 제어할 수 있는 mqd_t가 반환됩니다. 우리는 이것을 통해서 메시지를 주고 받을 수 있습니다.
2) mq_send, mq_timedsend
int mq_send(mqd_t mqdes, const char *msg_ptr,nsize_t msg_len, unsigned int msg_prio);
#include <time.h>
int mq_timedsend(mqd_t mqdes, const char *msg_ptr, size_t msg_len, unsigned int msg_prio,
const struct timespec *abs_timeout);
메시지를 보내는 함수는 두가지가 존재합니다.
mqdes : mq_open시에 받은 mqd_t입니다.
msg_ptr : char형 메시지 포인터입니다. 메시지 내용을 의미합니다.
msg_len : 이름에서 알 수 있듯이 메시지의 크기를 의미합니다.
msg_prio : 메시지의 우선순위를 지정합니다.
abs_timeout : 지정된 시간동안 메시지 전송을 보류합니다. 큐가 꽉 찼을 경우가 있을 경우에 말이죠. NON_BLOCK 플래그가 없어야합니다. timespec 구조체는 아래와 같습니다. 이 구조체를 사용하기 위해서 time.h가 필요합니다.
자, 메시지를 보냈으니까 받아야겠죠. mq_send와 받는다는 것 외에는 모두 똑같습니다. msg_ptr에 메시지가 들어오게 됩니다. 그리고 mq_timedreceive를 통해서 역시 메시지가 쌓일때까지 지정된 시간만큼 기다릴수 있습니다.
반환 : 만약 올바르게 받았다면 실제로 받은 메시지의 사이즈가 반환되고 실패할 경우 -1이 반환됩니다.
혹시 Message too long 에러가 발생한다면, 이것은 mq_receive 계열 함수에서 발생할 수 있는 에러인데, mq_receive의 man 페이지에서는 아래와 같이 설명하고 있습니다. mq_receive의 msg_len의 값은 attribute에서 설정한 mq_msgsize보다 작으면 안됩니다. (msg_len >= mq_msgsize)
EMSGSIZE
msg_len was less than the mq_msgsize attribute of the message queue.
4) mq_close
int mq_close(mqd_t mqdes);
mqdes : 닫을 mq를 지정합니다.
반환 : 성공시 0, 실패시 -1을 반환합니다.
mq 기본예제
다음의 server.c는 메시지큐를 열고 받은 메시지를 출력하는 아주 간단한 역할을 합니다.
server.c
#include <stdlib.h>
#include <fcntl.h>
#include <stdio.h>
#include <mqueue.h>
#include <sys/stat.h>
int main()
{
struct mq_attr attr;
//attr 때문에 에러 발생할 수 있음
attr.mq_maxmsg = 20;
attr.mq_msgsize = 128;
char buf[128] = {0,};
mqd_t mq;
mq = mq_open("/reakwon_mq", O_RDWR | O_CREAT, 0666, &attr);
if (mq == -1)
{
perror("message queue open error");
exit(1);
}
if((mq_receive(mq, buf, attr.mq_msgsize,NULL)) == -1){
perror("mq_receive error");
exit(-1);
}
printf("mq received : %s\n", buf);
mq_close(mq);
}
위처럼 각 메시지의 최대 사이즈는 8192, 큐의 최대 들어갈 수 있는 메시지는 10개 입니다. 그래서 invalid argument 에러가 발생한 건데, 방법은 두 가지 입니다. 1. attr을 아래와 같이 시스템 limit에 맞게 수정하던지, 아니면 2. /proc/sys/fs/mqueue 안의 파일 내용을 강제로 고치던지 말이죠.
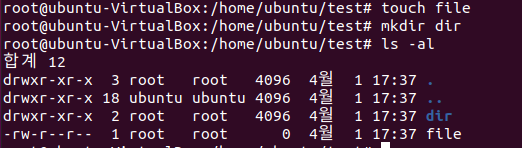
우리가 유닉스 시스템에서 파일을 만들때 저처럼 별 생각없이 만드시는 분이 있을거라고 생각합니다. 파일 혹은 디렉토리를 생성할때 권한은 어떻게 결정이 될까요? 다음은 저의 리눅스에서 파일과 디렉토리를 생성했을때 어떤 권한을 가지고 있는지 확인해보겠습니다.
파일은 권한이 644, 디렉토리는 755로 설정이 되어있네요. 리눅스에서 원래 파일은 0666, 디렉토리는 0777로 생성되게 됩니다.
644, 755?
읽기, 쓰기, 실행 권한은 숫자로 표현할 수가 있습니다. 각 권한은 비트로 대응되어 설정되어있으면 1, 아니면 0이 됩니다. 그래서 읽기, 쓰기만 권한이 설정되어있고, 실행권한이 없다면 110이 되어서 10진수로 읽으면 6이 됩니다. 그래서 소유자, 그룹, 다른 사용자 권한까지 포함이 되면 세글자의 10진수로 표현이 될 수 있습니다. 666이라면 소유자, 그룹, 다른 사용자가 모두 읽기, 쓰기가 허용됩니다. 네 자리로 0666으로 표현할 수 있는데, 앞 숫자는 setuid, setgid, sticky 비트의 표현이 됩니다. 이 설명은 지금 포스팅에서 하지 않기로 합니다.
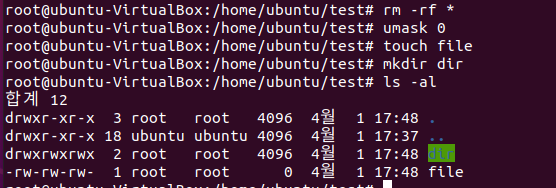
근데 위의 결과와는 다르네요? 네, 그것은 umask를 통해서 생성시 권한을 바꿔줄 수가 있기 때문이죠. umask 명령어를 그냥 쳐보면 현재 적용되어있는 umask의 값을 확인할 수 있습니다. 아래는 저의 리눅스의 umask값입니다.
0022입니다. umask가 적용되지 않았을때, 파일은 0666, 디렉토리는 0777 권한으로 생성되어진다고 했었죠? 그런데 지금 umask값은 0022이니까 0666에서 0222를 빼게 되면 0644, 0777에서 0022를 빼면 0755가 됩니다. 그래서 제가 아까 파일과 디렉토리를 생성했을때 0644, 0755의 권한으로 생성이 되었던 거죠.
생성 파일
권한
file
0666 - 0022 = 0644
dir
0777 - 0022 = 0755
umask를 해제하고 싶다면 umask 0으로 해제할 수 있습니다. 그렇기 때문에 아래와 같이 다시 파일과 디렉토리를 생성했을때 0666, 0777로 권한이 설정됩니다.
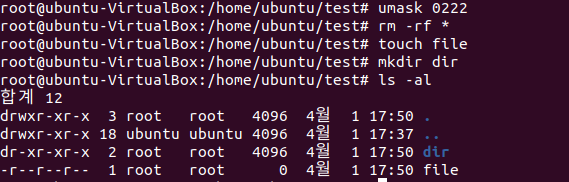
한번만 더 umask를 통해 생성시 권한을 변경시켜보도록 하겠습니다. 파일을 모두 읽기 권한만 설정하는 umask는 아래와 같습니다.
umask를 사용할때 주의하셔야할 점은 권한을 설정해주는 것이 아니라 기본 권한(파일 : 0666, 디렉토리 :0777)에서 그 권한을 빼는 것을 기억해두시기 바랍니다.
chmod
chmod명령을 이용하면 디렉토리나 파일의 권한을 변경할 수 있습니다. 단, 변경하려는 파일이나 디렉토리의 소유자만이 가능합니다. 다음의 권한이 있는 파일이 있을때 소유자는 읽기,쓰기 그리고 그 외에는 읽기만 할 수 있도록 권한을 주고 싶다면 아래와 같이 권한을 변경할 수 있습니다.
이렇게 숫자로 줄 수도 있고, 문자 약자로 더하거나(+) 뺄수(-)도 있습니다. 아래와 같이 말이죠.
반대로 뺄때는 - 기호를 사용하면 됩니다. 약자는 아래 표로 설명하도록 하겠습니다.
약자 표현
설명
u
user로 파일 소유자를 의미합니다.
g
group으로 파일 소유자의 그룹을 의미합니다.
o
other로 다른 사용자를 의미합니다.
+, -
권한을 추가하려면 +, 빼려면 -를 사용하면 됩니다.
r
read로 읽기 권한을 의미합니다.
w
write로 쓰기 권한을 의미합니다.
x
execute로 실행권한을 의미합니다.
s
setuid, setgid 비트를 의미합니다.
위 표에 나와있는것 외에도 몇가지가 더 있습니다만, 잘 안써서 패스합니다
chmod를 설정할때 setuid, setgid, sticky 비트를 명시적으로 지정하지 않으면 그 전에 있던 suid, sgid, sticky 비트를 유지합니다.
여기까지 파일 생성시에 권한과 권한 변경과 관련한 umask, chmod 명령어에 대해서 알아보았습니다.
명령어는 /bin/ls를 사용합니다. 그리고 첫번째 인자는 옵션 "-al"이며 두번째 인자는 내용을 출력할 디렉토리인 /etc입니다. argv를 잘 보시면 가장 첫번째 배열 원소는 실행할 파일 이름이 있다는 것 마지막은 NULL을 기억하세요. exec명령을 여러번 실행할 수는 없습니다. 그러니까 하나씩 실행하면서 결과를 확인해보세요.
exec의 특징
exec를 사용하게 되면 기존의 exec를 실행시킨 프로세스는 exec가 실행한 프로그램으로 대체가 됩니다. 그렇기 때문에 exec를 실행시킨 프로세스 ID와 exec로 실행된 프로세스 ID와 같습니다. 실험해볼까요?
아래의 프로그램 코드는 exec로 실행시킬 프로그램입니다. 이 프로그램은 프로세스 ID, 부모 프로세스 ID, 세션 ID를 출력합니다.
//myexec.c
#include <unistd.h>
#include <stdio.h>
int main(){
char *file="myprogram";
char *argv[]={file, NULL};
printf("before exec\n");
printf("pid : %d, ppid : %d\n",getpid(),getppid());
printf("session id : %d\n", getsid(getpid()));
printf("\n");
execvp(file,argv);
printf("exec end\n"); //출력되지 않을 것
return 0;
}
이제 이 둘을 컴파일을 하고 다음과 같이 실행시켜보세요. PATH에 현재 디렉토리를 추가하여 myprogram을 실행시켜주도록 합시다. execvp는 PATH에 있는 환경 변수의 경로를 찾게 되니까요. 이렇게 현재 디렉토리를 PATH에 추가하면 보안상 매우 좋지 않습니다. 하지만 이해를 돕기 위해서 진행합니다.
# export PATH=$PATH:.
# gcc myprogram.c -o myprogram
# gcc myexec.c
# a.out
before exec
pid : 500050, ppid : 500036
session id : 499935
after exec
pid : 500050, ppid : 500036
session id : 499935
실행결과는 모두 같습니다.
이 밖에도 exec수행 시에 실행시킨 프로세스의 여러 속성들을 물려받는데, 그중 몇가지를 아래에 기재하였습니다.
프로세스 그룹 ID
제어 터미널
실제 사용자 ID, 실제 그룹 ID
현재 작업 디렉토리
프로세스 Signal mask
유보 중인 신호들
파일모드 생성 마스크
초간단 shell 만들기
프로세스를 생성하는 함수인 fork()와 exec()를 사용하여 간단한 쉘을 만들어볼 수도 있습니다. 아래는 간단한 쉘을 흉내내본 프로그램 코드입니다.
디렉토리를 읽는 것은 파일을 읽는것과는 다른 함수들을 사용합니다. 오늘은 관련 함수들 간단히 살펴보고 사용하는 예를 보도록 하겠습니다.
우선 관련 함수를 사용하려면 아래와 같은 헤더파일을 include해야합니다.
#include <sys/types.h>
#include <dirent.h>
1) opendir
DIR *opendir(const char *name);
opendir에 디렉토리 이름을 인자로 넣어주게 되면 정상적으로 종료시 DIR 포인터에 그 디렉토리에 대한 포인터가 반환이 됩니다. 에러시 NULL이 반환되고, errno에 에러 번호가 기록이 됩니다.
2) readdir
struct dirent *readdir(DIR *dirp);
디렉토리의 내용을 읽게 되면 그 디렉토리 안의 디렉토리나 파일이 dirent 구조체 포인터로 반환되게 됩니다. 이 함수는 주로 while문과 같이 사용됩니다. dirent의 구조체 내용은 아래와 같습니다. 만약 읽을 파일이나 디렉토리가 없으면 NULL을 반환하게 됩니다.
struct dirent {
ino_t d_ino; /* Inode number */
off_t d_off; /* Not an offset; see below */
unsigned short d_reclen; /* Length of this record */
unsigned char d_type; /* Type of file; not supported
by all filesystem types */
char d_name[256]; /* Null-terminated filename */
};
주석만 잘 읽어도 위의 필드들이 무엇을 의미하는지는 알 수 있겠습니다.
3. closedir
int closedir(DIR *dirp);
파일을 열고난 이후 close() 함수로 닫아주듯이 디렉토리 역시 마찬가지입니다. 이 함수가 closedir이고, opendir()에서 반환받은 DIR*를 전달해주면 됩니다. 에러없이 성공적으로 디렉토리를 닫았다면 0이 반환되고, 그렇지 않으면 -1이 반환됩니다. 이 역시 errno를 통해서 에러 번호를 확인할 수 있습니다.
디렉토리 내용 읽기
위의 함수들만을 이용해서 디렉토리의 내용들을 볼 수 있습니다. 아래는 그러한 예의 프로그램 코드입니다.
read_dirent() 함수는 간단합니다. 먼저 디렉토리의 이름을 인자로 받고 있습니다. 1. 이름을 통해서 opendir을 통해 디렉토리를 열고, 이후 2.read_dir로 반복적으로 그 디렉토리의 내용을 읽습니다. 마지막은 3,closedir로 닫는 역할을 합니다.
코드가 길어보이지만, 어렵지 않은 코드입니다. 바로 위의 코드에 비해서 1. 완전한 경로를 구할 수 있는 코드(concat_path)를 추가한것과 2. 재귀적으로 호출하는 부분이 전부입니다. 이렇게 구현하게 되면 아래와 같이 재귀적으로 하위 디렉토리까지 출력하게 됩니다.
void main() {
int i, j;
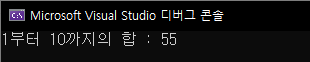
for (i = 1; i <= 4; i++) {
for (j = 1; j <= i; j++)
printf("*");
printf("\n");
}
}
2.
**** *** ** *
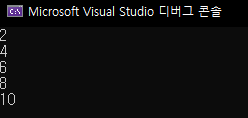
void main() {
int i,j;
for (i = 4; i > 0; i--) {
for (j = 1; j <= i; j++)
printf("*");
printf("\n");
}
}
3.
* *** ***** *******
여기서부터 좀 많이 헤메실수 있어서 풀이방법도 기재해드립니다. 우선 코드분석해보시고 풀이를 봐주세요.
#include <stdio.h>
void main() {
int i, j, height;
scanf("%d", &height);
for (i = 1; i <= height; i++) {
for (j = 1; j <= height - i; j++) //공백 먼저 출력
printf(" ");
for (j = 1; j <= i * 2 - 1; j++) //*출력
printf("*");
printf("\n");
}
}
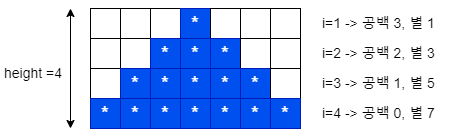
우선 i는 *과 공백을 포함한 한 줄을 의미합니다. 공백과 별을 어떻게 출력하는지는 아래와 같은 규칙을 갖게 됩니다. 아래의 그림은 높이가 4인 삼각형 모양의 별을 나타내었습니다.
i가 1일 경우 ) 우선 공백이 3개 출력되고, 별이 1개 출력이 됩니다.
i가 2일 경우 ) 공백이 2개 출력되고, 별이 3개 출력됩니다.
i가 3일 경우 ) 공백이 1개, 별이 5개 출력됩니다.
i가 4일 경우 ) 공백이 0개, 별이 7개 출력됩니다.
자, 이제 일반화하게 되면, 아래와 같은 규칙을 얻게 되지요.
공백 : height - i 까지 출력
별 : i*2 -1까지 출력
그래서 위의 코드와 같이 쓸 수 있습니다.
4.
******* ***** *** *
이거는 i를 처음부터 height값으로 놓고 --i로 거꾸로 돌리면 됩니다.
void main() {
int i, j, height;
scanf("%d", &height);
for (i = height; i >= 0; i--) {
for (j = 1; j <= height - i; j++) //공백 먼저 출력
printf(" ");
for (j = 1; j <= i * 2 - 1; j++) //*출력
printf("*");
printf("\n");
}
}
4.
* *** ***** ******* ***** *** *
위의 두 코드를 합치면 되는데, 중간에 같은줄이 두개 나오기 때문에 밑에는 height -1로 하여 한번 빼줍시다.
for (i = 1; i <= height; i++) {
for (j = 1; j <= height - i; j++) //공백 먼저 출력
printf(" ");
for (j = 1; j <= i * 2 - 1; j++) //*출력
printf("*");
printf("\n");
}
for (i = height-1; i >= 0; i--) {
for (j = 1; j <= height - i; j++) //공백 먼저 출력
printf(" ");
for (j = 1; j <= i * 2 - 1; j++) //*출력
printf("*");
printf("\n");
}
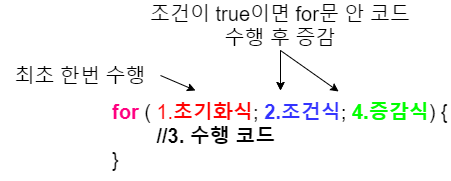
이상으로 별까지 출력하는 코드로 for문을 활용해보았습니다. for문은 배열과 같이 많이 쓰이기 때문에 반드시 알아야하는 반복문입니다.
switch ~ case 문법은 if문과 비슷하지만 약간은 다른 문법인데요. if 문은 괄호안에 조건식에 따라서 비교를 하고 조건식이 꽤나 복잡해질 수 있습니다. 이럴때 가독성이 조금 떨어지게 되지요. 하지만 switch case 문은 보다 명료하고 간단하게 조건에 따라 실행하는 case들이 나눠지기 때문에 가독성이 뛰어나다는 장점이 있죠. 이제 switch ~ case를 어떻게 사용하는가, 그리고 흔하게 할 수 있는 실수들은 무엇인가에 대해서 설명해보려고 합니다.
1. 기본 사용법
switch case의 기본 템플릿은 아래와 같습니다.
switch: switch안에는 정수형으로 이 정수의 데이터를 가지고 case 옆의 데이터와 비교하게 됩니다.
case n: 실제 수행 부분입니다. swtich에 전달한 정수형 인자와일치하면 그 case문을 실행하게 되는거죠.
default: case에 모두 포함되지 않을 경우 default 안쪽의 코드가 실행됩니다. default는 생략할 수도 있습니다.
switch(정수형){
case 1:
//...//
break;
case 2:
//...//
break;
case 3:
//...//
break;
//...//
default:
//...//
}
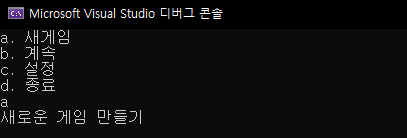
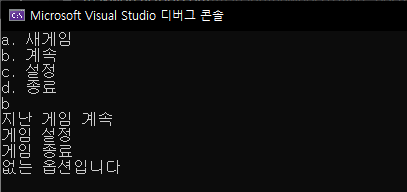
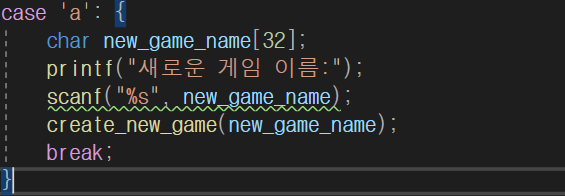
아래는 switch ~ case를 이용한 간단한 예제입니다.
#include <stdio.h>
void create_new_game() {
printf("새로운 게임 만들기\n");
}
void continue_game() {
printf("지난 게임 계속\n");
}
void game_setting() {
printf("게임 설정\n");
}
void exit_game() {
printf("게임 종료\n");
}
void main() {
int selection;
printf("1. 새게임\n");
printf("2. 계속\n");
printf("3. 설정\n");
printf("4. 종료\n");
scanf("%d", &selection);
switch (selection) {
case 1:
create_new_game();
break;
case 2:
continue_game();
break;
case 3:
game_setting();
break;
case 4:
exit_game();
break;
default:
printf("없는 옵션입니다\n");
}
}
자료구조 중 하나인 Map은 키(key)와 값(value)를 쌍으로 갖는 STL입니다. Map의 특징 중 하나는 키 값이 중복되지 않는 다는 것입니다. C++에 있는 Map은 레드블랙트리로 이루어져있으며 검색, 삽입, 삭제가 O(log n)입니다.
코드를 보면서 어떻게 사용할 수 있는지 확인해보도록 하겠습니다. map을 사용하기 위해서는 아래와 같이 map 헤더파일을 include해주어야합니다.
#include <map>
1. 데이터 삽입, 조회, 변경
#include <iostream>
#include <map>
#include <string>
using namespace std;
int main() {
map<string, string> m;
m["seoul"] = "02";
m["kyungki"] = "031";
m["daegu"] = "051";
m["incheon"] = "032";
//맵의 모든 데이터를 순환
//first, second를 보아 pair객체를 사용하는 것을 알 수 있다.
for (auto iter : m) {
cout << iter.first << "의 지역번호:" << iter.second << endl;
}
cout << endl;
//[]로도 접근 가능
cout <<"seoul:"<< m["seoul"] << endl;
//변경
m["daegu"] = "053";
cout << "daegu:" << m["daegu"] << endl;
}
배열 인덱스를 다루듯이 사용할 수가 있습니다.
아래는 결과화면입니다.
그런데 한가지 유심히 보면 map의 키,값을 순회할때 키가 오름차순으로 나오고 있네요(daegu - incheon - kyungki - seoul). 내림차순으로 map을 구성하고 싶다면 아래와 같이 사용하세요.
map<string, string,greater<string>> m;
그리고 insert()함수를 통해서 삽입할 수도 있습니다. Map은 내부적으로 pair 객체를 이용하여 키와 값을 저장하는데요. first는 키, second는 값이 들어가게 됩니다.
#include <iostream>
#include <map>
#include <string>
#include <vector>
using namespace std;
int n, m;
int main() {
cin >> n >> m;
//값은 0으로 default로 설정됨
map<string, int> outsiders;
vector<string> ans;
for (int i = 0; i < n+m; i++) { //듣+보 전부 한꺼번에 입력받음(n+m)
string name;
cin >> name; //이름이 2번 등장하면 outsiders[name] = 2가 된다
outsiders[name]++;
}
//2면 정답
for (auto it : outsiders) {
if (it.second == 2) ans.push_back(it.first);
}
cout << ans.size() << endl;
for (int i = 0; i < ans.size(); i++)
cout << ans[i] << endl;
}
Standard Template Library의 컨테이너로 정의된 클래스인데요. 배열과 비슷한 특징이 있습니다만, 동적으로 계속하여 뒤에 원소를 추가할 수 있습니다. 배열을 다루는 사용자의 불편함을 vector를 사용하면 어느정도 편리하게 사용할 수 있습니다. 이 포스팅에서는 vector의 사용방법에 대해서 다룹니다.
C++에서 vector를 사용하기 위해서는 아래와 같이 vector 헤더파일을 추가시키시면 됩니다.
#include <vector>
1. 초기화
배열과 비슷하다고 했습니다만 초기화 방법에서는 약간 차이가 있습니다. 아래의 코드는 초기화 방식을 설명합니다.
vector<int> v1; //아무것도 없는 비어있는 vector
vector<int> v2(5); //5개의 int형을 저장하는 vector(전부 0으로 초기화)
vector<int> v3(5,1); //5개의 int형을 저장하는 vector(전부 1로 초기화)
vector<int> v4 = { 1,2,3,4,5 }; //배열과 같은 초기화
vector<int> v5(v4); //v4의 벡터 요소를 복사해서 초기화
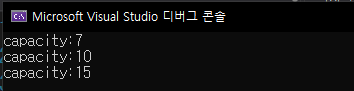
2. 크기와 용량(size & capacity)
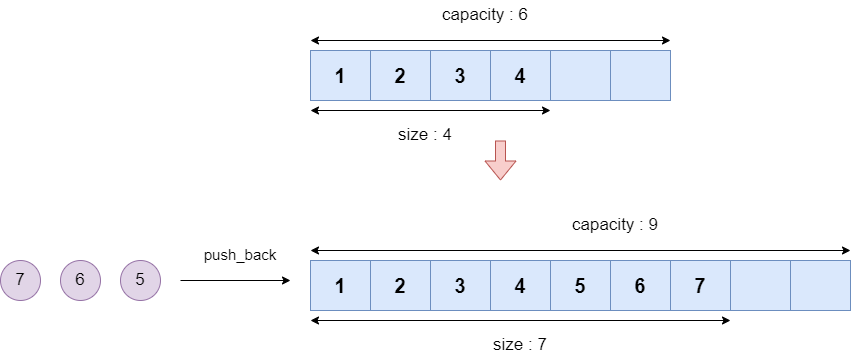
vector는 현재 가지고 있는 데이터의 수를 나타내는 크기(size)와 얼만큼의 데이터를 담을 수 있는지에 대한 용량(capacity)가 있습니다. 만약 용량이 전부 꽉 차게 되면 용량을 동적으로 더 늘려서 데이터를 추가할 수 있습니다. vector의 용량은 항상 size보다 크거나 같습니다. 아래의 그림처럼 capacity가 모자라게 되면 늘리게 되는거죠.
코드로 직접 확인해보세요.
#include <iostream>
#include <vector>
using namespace std;
int main() {
vector<int> v;
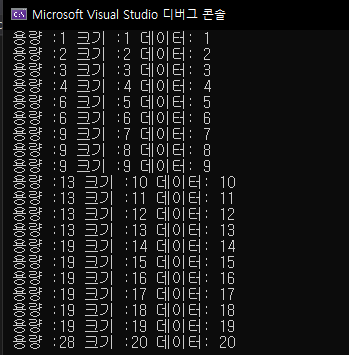
for (int i = 0; i < 20; i++) {
v.push_back(i + 1);
cout << " 용량 :" << v.capacity();
cout << " 크기 :" << v.size();
cout << " 데이터: " << v[i] << endl;
}
return 0;
}
3. 데이터 읽기
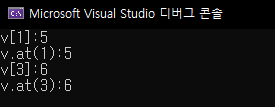
데이터읽는 방법은 배열과 같이 []로 접근하는 방법과 at() 으로 접근하는 방법이 있습니다. 둘은 같은 값을 나타내줍니다. 아래의 코드를 보고 결과가 같은지 확인해봅시다.
둘은 같은 값을 나타내고 있죠? 하지만 차이는 없을까요? 있겠죠. 만약 배열 접근 기호([])로 10번째 요소를 읽어봅시다. 현재 5번째까지 초기화했고, 10번째는 아직 접근할 수 없기 때문에 아래와 같은 에러를 보이고 종료하고 맙니다. at()통해서도 마찬가지일거에요. 하지만 둘의 차이는 예외를 뜨게해서 처리할수 있게 만들었느냐 아니냐입니다.
아래의 코드를 실행시켜보시고, 바꿔서 윗줄은 주석처리, 아랫줄은 주석 해제하여 실행해보세요. 차이점을 알 수 있습니다.
#include <iostream>
#include <vector>
using namespace std;
int main() {
vector<int> v = { 1,5,3,6,8 };
try {
cout << v[10] << endl;
//cout << v.at(10) << endl;
}
catch (out_of_range& e) {
cout << "예외 발생 처리 " << endl;
}
return 0;
}
프로그래밍을 at()으로 하면 더 안전하게 사용할 수 있는 대신 검사때문에 []를 이용하는 방법보다는 느립니다. 두 방식 중 알맞게 선택하여 사용하세요.
4. 데이터쓰기
데이터쓰기는 너무 편합니다. 그냥 배열과 같이 사용하면 됩니다.
vector<int> v = { 5,3,1,6,7 };
v[2] = 3;
5. 데이터 뒤에 추가 및 뒤에서 삭제
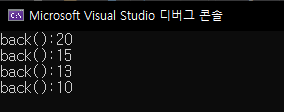
push_back()을 사용하면 아래와 같이 vector 뒤에 차곡차곡 데이터를 추가합니다. 반대로 삭제하려면 pop_back()을 사용하시면 됩니다. pop_back()은 데이터를 return하지는 않고, 단지 꺼내주기만 합니다. 가장 마지막 원소를 가져오려면 back()을 이용하세요.
#include <iostream>
#include <vector>
using namespace std;
int main() {
vector<int> v;
v.push_back(10);
v.push_back(13);
v.push_back(15);
v.push_back(20);
int size = v.size();
for (int i = 0; i < size; i++) {
cout << "back():" << v.back() << endl;
v.pop_back();
}
return 0;
}
6. Iterator
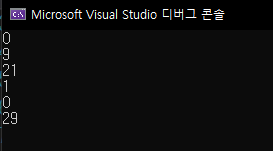
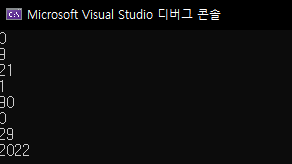
Iterator를 통해서 for문을 돌수도 있습니다. vector의 begin()은 vector의 처음 요소를 가리키고 있습니다. vector의 end()는 vector의 마지막 요소 다음을 가리키고 있습니다. 마지막 요소 다음이지 마지막 요소를 가리키는게 아닙니다.
그래서 아래와 같이 for문을 사용하는 방법이 가능합니다.
vector<int> v = { 0,9,21,1,0,29 };
for (vector<int>::iterator it = v.begin(); it != v.end(); it++)
cout << *it << endl;
너무 복잡하죠? 아래와 같이 auto로 코드를 줄일 수 있습니다.
for (auto it = v.begin(); it != v.end(); it++)
cout << *it << endl;
C언어를 배우는 중에 조건에 따라 실행흐름을 분기시키는 예약어인 if문에 대해서 자세히 알아보도록 합시다. if문와 else if는 괄호에 조건식을 써주는데요. 이 조건에 따라 실행을 다르게 시킬 목적으로 사용이 됩니다. 아래와 같은 방식으로 사용하게 됩니다. 이제 예제를 보면서 하나씩 이해하도록 합시다.
if문은 다음과 같이 괄호 안에 비교식을 써주면 되는데요. 이때 괄호식 안에 조건이 참이 되는 경우에만, if안의 코드를 실행하게 됩니다. if 안의 문장이 한문장일 경우에 아래의 중괄호는 생략이 될 수 있습니다.
#include <stdio.h>
void main() {
int a = 10;
if (a == 10) { //if안의 구문이 한 줄이면 '{' 생략가능
printf("a = 10\n");
}//if안의 구문이 한 줄이면 '}' 생략가능
printf("종료\n");
}
위의 코드는 아래와 같이 수행이 됩니다. a가 5라면 if안에 printf는 호출이 되지 않지요.
2. if ~ else ~ 구문 예제
if에 조건에 맞지 않는 조건을 수행할 때에는 else 구문을 이용할 수 있습니다.
#include <stdio.h>
void main() {
int a = 2;
if (a == 10) {
printf("a의 값은 10.\n");
}
else {
printf("a의 값은 10이 아님.\n");
}
}
아래는 위 코드의 결과입니다.
3. 조건이 여러가지일 경우 else if
조건이 여러 가지가 있을 경우에는 else if를 통해서 여러 조건을 줄 수가 있습니다. if 부터 순차적으로 아래쪽으로 비교해서 그 중 참이 되는 경우에 있는 블록만 실행하고 바로 if문을 빠져나옵니다.
#include <stdio.h>
void main() {
int a = 3;
if (a >= 5) {
printf("a의 값은 5 이상\n");
}
else if (a >= 2) {
printf("a의 값은 2 이상\n");
}
else {
printf("a의 값은 2 미만\n");
}
}
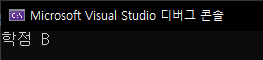
#include <stdio.h>
void main() {
int score = 85;
if (score >= 90) {
printf("학점 A\n");
}
else if (score >= 80) {
printf("학점 B\n");
}
else if (score >= 70) {
printf("학점 C\n");
}
else if (score >= 60) {
printf("학점 D\n");
}
else {
printf("학점 F\n");
}
}
4. 조건이 참인 경우 = 0이 아닌 경우
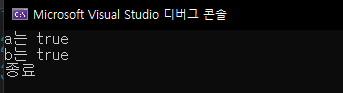
C, C++에서 거짓의 조건은 간단합니다. 0만 false라고 간주한다는 것이죠. 그 외의 모든 수는 전부 참으로 간주합니다. 즉, 여기 if문이나 else if에서 조건이 참인 경우는 0이 아닌 경우입니다. 0외에 숫자는 모두 참으로 간주하게 됩니다. 그래서 아래의 코드중 a와 b가 참이되는 이유입니다.
#include <stdio.h>
void main() {
int a = 1;
int b = -1;
int c = 0;
if (a) {
printf("a는 true\n");
}
if (b) {
printf("b는 true\n");
}
if (c) {
printf("c는 true\n");
}
printf("종료\n");
}
5. &&조건과 || 조건
&&(논리 AND 연산)은 모든 조건이 전부 true여야 true이고, ||(논리 OR 연산)은 모든 조건중에 하나라도 true이면 true입니다.
#include <stdio.h>
void main() {
int a = 1;
int b = 2;
if (a == 1 && b == 2) {
printf("a=1이고 b=2이다.");
}
else {
printf("a=1이 아니거나, b=2가 아니다.");
}
}
6.1 하기 쉬운 실수1 (모든 비교문이 수행이 되지 않음)
다음은 if문이나 조건식에서 흔하게 하기 쉬운 실수입니다. 아래의 코드를 예측해보시기 바랍니다.
#include <stdio.h>
void main() {
int a = 10;
int b = 20;
if (a > 10 && (b++) > 20) {
printf("실행이 될까요?\n");
}
printf("b의 값:%d\n", b);
}
조건을 보게 되면 a는 10보다 크지 않죠. 딱 10이니까요. 그렇다면 a>10은 false가 됩니다.
그리고 다음 조건에서 b를 선증가시킨 후 20과 비교합니다. b는 21의 값이 되겠네요. 그렇다면 b>20의 조건은 true가 되겠네요.
그렇다면 if문 안의 printf는 실행이 되지 않겠네요. 그렇다면 b의 값은 얼마일까요? 아래 결과 화면입니다.
b의 값은 고스란히 20입니다. 조건식에서 비교할때 &&이나 ||이 오게 되면 true나 false가 확정일 경우에는 그 뒤의 식은 보지도 않고 건너 뛰어버립니다. 그래서 b++은 수행되지 않게 되죠. 그래서 b가 21로 나오게 할 경우에는 아래와 같이 수정이 되어야 21이 나오게 됩니다.
#include <stdio.h>
void main() {
int a = 10;
int b = 20;
if (a > 9 && (b++) > 20) {
printf("실행이 될까요?\n");
}
printf("b의 값:%d\n", b);
}
6.2 하기 쉬운 실수 2 (실수로 값 대입)
== 연산자나 != 연산자를 사용할때 흔히 이런 실수를 많이 하게 됩니다. 아래의 코드는 원래 finished == 1일 경우 프로그램이 종료되야하는 조건입니다. finished가 그전에 0이기 때문에 if문을 수행하지 않는것이 프로그래머의 의도입니다. 하지만 코드에서 프로그래머의 실수로 '=' 하나 빠지는 바람에 finished=0에서 finished=1로 대입이 되었고, if문이 실행이 됩니다.
#include <stdio.h>
void main() {
int finished = 0;
if (finished = 1) { //이 식은 문법상 문제가 없는 문장이므로 에러없이 컴파일됨
printf("finished\n");
}
}
이런 오류들은 컴파일에서 잡아낼 수 없으며 찾는데도 오래 걸리게 됩니다. 따라서 비교식을 쓸때 상수는 왼쪽에 쓰는 것이 이런 휴먼 에러를 막을 수 있습니다.
이렇게 빨간색으로 뜨니까 컴파일단계에서 바로 알 수 있고 아래처럼 올바르게 수정하여 프로그램을 더 안전하게 만들 수 있습니다.
#include <stdio.h>
void main() {
int finished = 0;
if (1 == finished) {
printf("finished\n");
}
}
여기까지 C언어의 if문에 대해서 알아보았습니다. if문은 어렵지는 않지만 비교문이 끝까지 비교가 진행이 되는지 되지 않는지 모르는 것과 아는 것은 다릅니다. 공부하는데 도움이 되었으면 좋겠습니다.