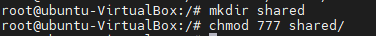이미지 출처 : https://www.hackerschool.org/Sub_Html/HS_University/HardwareHacking/04.html
CPU(Central Processing Unit) : 중앙처리장치
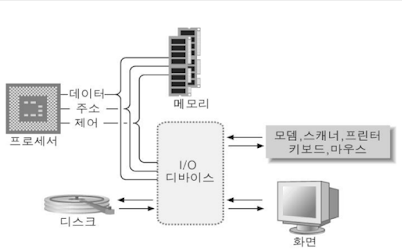
컴퓨터를 배울때 CPU, CPU 많이 얘기하잖아요? CPU가 중앙처리장치라고 해서 우리의 두뇌같은 역할을 한다고 이런 추상적인 말은 많이 들었을 겁니다. 저처럼 아무 생각이 없는 사람은 논외로 하고 대부분의 사람은 머리가 시키는 대로 팔, 다리가 움직이고, 보고 들으면서 반응을 하게 됩니다. CPU가 바로 이러한 기억과 연산, 제어를 종합적으로 처리하는 장치라고 보시면 됩니다. CPU는 이런 기능을 하고는 있지만, 단독으로는 사용할 수 없습니다. 그래서 메인보드, 주기억장치(RAM), 보조기억장치(하드디스크), 버스 등 주변 장치들이 필요합니다.
CPU를 단일 IC칩에 직접시켜 만든 소자가 MPU(Micro Processing Unit)라고 합니다. 자, 간단하게 이름을 보시면 더 이해하기 편합니다. 아주 작은(Micro) 연산 장치(Processing Unit)이라는 의미로 CPU를 소형화시킨 것이라고 이해하시면 됩니다. MPU는 결국 CPU의 한 종류이지만, CPU가 MPU인것은 아닙니다. 하지만 요즘에는 이 둘을 통용해서 CPU라고 칭합니다. 또 CPU는 프로세서(Processor)라고도 합니다.
이미지 출처 : https://computechlog.blogspot.com/2017/03/operating-system2.html
코어(Core)
이전에는 CPU하나가 모든 일을 전부 담당을 했었죠. 이제는 그렇지 않습니다. CPU안에서도 코어라는 개념을 두게 되었습니다. 코어는 일을 실제 하는 단위라고 보시면 됩니다. 그래서 코어가 두개이면 여러 일을 두 코어가 같이 처리하게 됩니다. 여러분들도 회사에서 혼자 일하는 것보다 두 사람이 일해서 빨리 끝나서 칼퇴해야되잖아요. 그런 개념입니다. 코어가 하나인 CPU는 싱글코어(Single Core)라고 합니다. 듀얼 코어 CPU는 물리적인 CPU 2개가 일하는 것과 비슷하다고 생각하시면 됩니다. 2개의 Core는 듀얼코어(Dual Core), 4개의 코어는 쿼드코어(Quad Core), 8개는 옥타코어(Octa Core)라고 합니다. 물론 클록수가 현저하게 차이나면 결과는 다르지만 코어가 많을 수록 좋습니다(한 사람이 100개의 일을 1시간에 처리하는 것이 2명이 10개의 일을 한시간에 처리하는 것보다 더 빠른 처리가 가능하겠죠.).
MCU(Micro Controll Unit) : 마이크로 컨트롤러
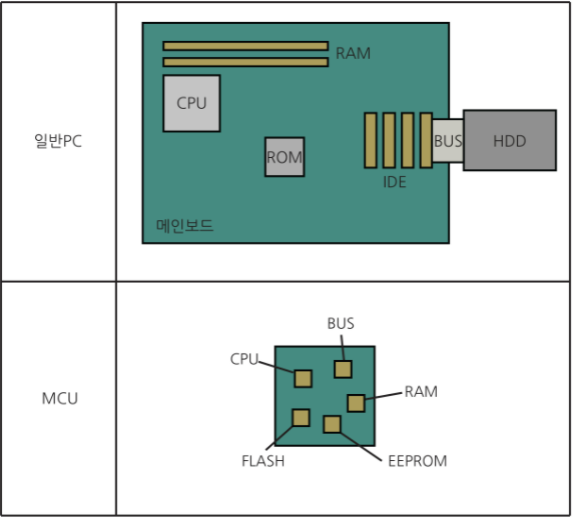
MCU는 작은 컴퓨터라고 해서 one-chip microcomputer 라고 합니다. MCU는 일반 CPU에 비해 작으면서, 구동할 수 있는 최소한의 필수적 기능만을 포함하면서, 그로인해 연결할 수 있는 핀의수도 적습니다. 이렇기 때문에 전력을 적게 쓸 수 있고, 비용도 저렴합니다. 일반적인 CPU와는 다르게 MCU는 이름에서도 알 수 있듯이 칩 안에 메모리, 버스, EEPROM 등 우리가 알고 있는 컴퓨터를 작게 축소해놓은 것과 같습니다. 그래서 매우 작은 컴퓨터(microcomputer)라고 지칭하는 것이겠죠. 이를 줄여서 마이컴(MICOM,micro-computer)라고도 합니다. 그렇기 때문에 기능이 그렇게 많이 정해져있지 않은 작은 전자제품(차량용 ECU 등)에 많이 쓰입니다.
EEPROM(Electrically Erased Programmable ROM) : 전기적으로 프로그래밍할 수 있는 비휘발성 메모리입니다. 이곳에다가 프로그래밍하여 값을 쓰게 되면 EEPROM에 기억이 됩니다. 비휘발성이라는 뜻은 직접 데이터를 지우지 않는 이상은 데이터가 보존된가는 뜻입니다. 시스템이 꺼져도 유지가 된다는 겁니다. 그렇기 때문에 MCU에서는 EEPROM이 하드디스크를 대체한다고 생각하시면 될 것 같습니다. 물론 대용량은 안되구요. 그리고 사용횟수에 제한이 있다는 점.
아래는 간략하게 CPU와 MCU를 비교한 그림입니다. 이와 같이 CPU가 주기억장치, 보조기억장치 등을 따로 연동시켜야하지만, MCU는 이를 포함하고 있죠. 아주 미니미니하게 포함하고 있다는 것입니다.
이미지 출처 : https://www.hackerschool.org/Sub_Html/HS_University/HardwareHacking/05.html
리눅스에서도 비슷한 의미로 쓰이는 것 같아요. 왜 비슷한 의미로 쓰이는 지는 포스팅을 보시면서 느껴보시기 바랍니다.
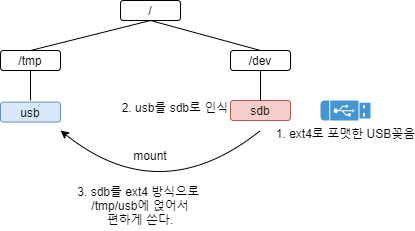
요즘 컴퓨터들보면 CD를 넣었을때나 DVD를 넣었을때, 그리고 USB를 넣었을때 시스템이 자동으로 인지하고 실행시키거나 읽어주죠? 너무 편리합니다. 하지만 이전에 시스템, 혹은 가벼운 전자 제품에 리눅스와 같은 커널을 사용할 경우 시스템이 저절로 인식하지 못할 수도 있습니다. USB나 CD를 넣었을때 인식하고 사용하기 위해서 필요한 명령어가 바로 mount 명령입니다. 간단하게 USB를 mount해보도록 합시다.
USB mount 해보기
0. 먼저 mount를 그냥 치게되면 현재 마운트된 시스템의 하드웨어들이 보이게 될겁니다. 그 중 sda, sdb 등이 디스크라고 보시면 됩니다. 아래는 저의 시스템에 마운트된 sda입니다.
1. 옹골진 USB를 일단 꽂습니다.핡
2. fdisk -l로 USB 메모리가 꽂힌 블록 디바이스 파일(/dev/ 밑에 있는 파일) 이름을 확인합니다. sda, sdb, sdc,, ... 처럼 앞에 'sd'가 붙는 것이 일반적입니다. 가장 간단하게 확인할 수 있는 것은 새로 생긴 sd*를 보고 용량을 보면 알 수 있습니다. 참고로 USB가 128G 용량이라고 해서 128G 온전히 다 잡히지는 않습니다. 한 116G정도로 약간 적게 잡힙니다.
제 경우에는 sdb1이라는 이름입니다.
3. 아래의 명령으로 mount합니다.
mount [-t file_system_type] [USB로 인식된 블록 디바이스 파일] [마운트 지점]
앞에 file_system_type은 생략 가능한데, 리눅스가 그 파일 시스템을 지원할때 가능합니다. 그것이 아니라면 명시적으로 지정해주어야합니다. 물론 리눅스 파일 시스템인 ext계열 파일 시스템은 지원가능하지만 윈도우즈(ntfs)의 파일 시스템의 경우나 CD-Rom을 위한 파일 시스템(iso9660)은 지원하지 않을 수 있습니다.
저의 usb의 경우에는 FAT32 파일 시스템을 사용하고, 혹시 지원하는지 확인하기 위해서 그냥 -t 옵션 사용하지 않고 해본 결과 잘되는 것을 확인했습니다.
mount /dev/sdb1 /tmp/usb
파일 시스템(File System)이란?
사실 말이 어려워서 File System이지, 간단하게 생각하면 별거 없습니다. 자, 여러분이 책을 정리할때를 생각해보세요. 저같은 경우는 일단 책을 보지 않습니다. 어떤 사람은 책꽂이 맨윗줄은 만화책, 그리고 그 다음 줄에는 전공서적, 그리고 그 다음 줄은 소설책 등으로 카테고리를 정리할 수 있습니다. 그리고 각 카테고리마다 또 사전순으로 책을 잘 정리하겠죠. 그래서 만약 "원피스"라는 만화책을 찾으려면 맨 윗줄, 'ㅇ'으로 시작되는 만화책 부분을 찾으면 되겠군요. 그리고 다 본후에는 다시 원위치에 꽂아서 넣으면 됩니다. 이렇게 책을 관리하는 나름대로의 체계가 있듯이 컴퓨터도 파일을 정리할때 체계가 존재합니다. 그래서 어떻게 파일을 삭제하고, 파일을 기록하고, 찾는지 등을 쳬계화해놓은 것이 File System이라고하며 저장 매체나 OS마다 각기 다른 파일 시스템을 사용하고 있습니다. 여러분이 책 정리할때 반드시 위의 사람과 같이 정리하지는 않듯이 말이죠.
여기서 간략하게 OS마다 어떤 파일 시스템을 갖는지만 살펴보도록 하지요. Linux : ext, ext2, ext3, ext4, xfs Windows : FAT12, FAT16, FAT32, exFAT, NTFS Mac : HFS, HFS+
한가지 자주쓰이는 옵션은 -r옵션인데요. 파일을 오직 읽기(read-only)만 하는 용도로 사용하겠다는 옵션입니다. 예를들어 CD겠죠? CD에 파일을 추가하거나 삭제할 수는 없으니까요. 또한 민감하거나 삭제되지 말아야할 경우에 쓰이기도 합니다. -o ro와 같은 옵션이기도 합니다.
혹시 mount에서 read-only로 마운트된 것을 read, write 가능하게 바꾸려면 아래의 명령을 사용하시면 됩니다. 단, rw가 가능한 파일시스템에 대해서만 입니다. CD-ROM은 당연안됩니다.
mount -o rw,remount [마운트지점]
4. 마운트를 해제할 경우 umount 명령을 사용하여 해제할 수 있습니다.
umount [마운트 지점]
그래서 umount /tmp/usb라는 명령어로 마운트 해제할 수 있습니다.
여기서 한가지 의문점이 들지 않나요?
왜 굳이 mount해서 쓰는 거지? 어차피 /dev/sdb1와 같이 자동으로 인식해주는데, 뭐하러 디렉토리를 만들고 mount하고 쓰는 것일까?
여러분이 기억하셔야할 점은 리눅스에서 모든 장치들은 파일로 취급한다는 점입니다. sdb 역시 파일로 인식되지요. 그래서 'cd /dev/sdb'와 같은 명령으로 디렉토리같이 사용할 수 없다는 것입니다. 또 어떻게 파일을 추가하고, 파일을 추가할때 이름은 몇자까지 제한이 되며, 파일을 삭제할때는 어떻게 삭제하는지도 모릅니다. 이러한 동작 방식들은 파일 시스템에서 정의하고 있기 때문입니다. 그렇기 때문에 우리는 파일 시스템을 명시하여 파일의 동작(operation)을 알려주면서 USB를 사용할 수 있게 됩니다(물론 아까도 말씀했다시피 지원되는 파일 시스템은 명시적으로 지정해주지 않아도 알아서 파일 시스템을 찾아줍니다.).
그래서 mount 명령어로 인식된 sdb에 대해서 파일이 동작하는 방식은 파일 시스템을 딱 알려주고 이것을 /tmp/usb 디렉토리에 얹어 쓰겠다고 리눅스에게 말해주는 것이죠. (아래 그림에서 sdb가 아니고 sdb1입니다.)
리눅스에서 파일을 다루는 방법은 세가지가 있습니다. 파일을 읽고(read), 쓰고(write), 실행(execute)하는 것이 그 세가지입니다. 리눅스는 서버용 멀티유저 운영체제이기 때문에 권한이 매우 중요합니다. 어떤 관리자는 특정 파일에 대해서 읽고 쓸 수 있는 권한이 있을 수 있고, 다른 관리자는 수정이 불가한 파일이 있을 수가 있겠죠. 이렇게 파일을 다룰 수 있게 리눅스에서는 파일의 속성을 줄 수가 있습니다.
ls -l 명령으로 exam.txt파일의 실행권한을 보도록 하겠습니다.
노란색으로 표시한 부분이 이 파일의 권한을 의미합니다. 이 파일을 만든 소유자는 ubuntu이고 ubuntu라는 그룹이라는 것도 알 수 있습니다.
-rw-rw-r--
-
r
w
-
r
w
-
r
-
-
파일 종류 -는 일반 정규 파일
소유자의 read 권한
소유자의 write권한
소유자의 실행권한 X
소유자 그룹의 read권한
소유자 그룹의 write권한
소유자 그룹의 실행권한X
다른 사용자의 read권한
다른 사용자의 write권한X
다른 사용자의 실행권한X
맨앞의 파일의 종류를 나타내는 '-'를 제외하고 권한의 '-'는 그 파일에 대한 해당 권한이 없다는 것을 의미합니다. 권한은 아까 세종류가 있다고 했는데 각각 이렇습니다.
r
read로 파일을 읽을 수 있는 권한입니다.
w
write로 파일을 수정할 수 있는 권한입니다.
x
execute로 파일을 실행할 수 있는 권한입니다. 파일에는 단순 기록하는 파일외에도 실행파일이 있기 때문에 이러한 권한이 필요합니다.
chmod 명령어
chmod는 파일의 권한을 바꿀 수 있는 명령어입니다. 명령어 형식은 이렇습니다.
chmod [파일에 추가거나 뺄 권한] [파일 이름]
만일 다른 유저들의 쓰기 권한을 추가하고 싶다면 아래의 명령으로 권한을 추가할 수 있습니다.
u+w의 앞 u는 사용자를 의미합니다. 여기서 +는 더한다는것을 알 수 있겠죠? 반대로 뺄때는 -를 씁니다. 마지막 글자 w는 어떤 권한인지를 말합니다. 읽기 권한을 추가하려면 r를 사용하면 되겠네요. 맨 처음 글자는 아래와 같습니다.
u
user의 앞글자로 소유자를 의미합니다.
g
group의 앞글자로 소유자의 그룹을 의미합니다.
o
other의 앞글자로 다른 유저들을 의미합니다.
여러 권한을 설정할때는 쉼표로 나열해주면 됩니다. 아래는 그룹과 다른 유저들에게 r,w를 더해주는 명령어의 예입니다.
chmod g+rw,o+rw file.txt
그리고 숫자로 권한을 일괄적으로 바꾸는 방법도 있습니다.
파일의 권한을 설명할때 rwxrwxrwx로 해도되지만 보통은 정수를 사용하여 권한을 이야기합니다. 앞에 rw-rw-r--는 숫자 664로 대응이 되는데, 왜 이렇게 되는걸까요? 세개를 묶어서 세비트로 표현하기 때문입니다.
r
w
-
r
w
-
r
-
-
1
1
0
1
1
0
1
0
0
4
2
0
4
2
0
4
0
0
두번째 줄은 이진수, 세번째 줄은 10진수로 표현했습니다. 그래서 rw-는 결국 이진수 110으로 되어 6이 됩니다. 그렇다면 rwx는 111이 되어서 7이겠네요.
아래는 chmod로 유저는 모든 권한을, 그룹 사용자는 읽기, 쓰기 권한을, 그리고 다른 사용자는 읽기 권한만 추가하는 명령어의 예입니다.
- chmod 764 a.out
그리고 setuid와 setgid, sticky의 비트를 사용하여 네자리로 표현할 수도 있습니다. 각각 setuid는 4, setgid는 2, sticky는 1로 대응이됩니다.
- chmod 4764 a.out
위 명령은 setuid를 설정하는 명령입니다. setuid와 setgid, sticky는 아래에 설명하도록 하겠습니다.
setuid
setuid를 설명하기에 앞서 리눅스에서는 유저를 id로 구별합니다. 두 종류가 있는데 아래와 같습니다.
UID (REAL UID) : 이는 실제 사용자 본인의 아이디를 표현한다고 해서 real id라고도 하면 uid라고 합니다.
EUID (EFFECTIVE UID) : 유효 사용자 아이디라고해서 프로그램이 실행될때 갖는 아이디를 말합니다. 즉, 실행시에 이 프로그램을 만든 사용자의 ID로 실행이 된다는 겁니다.
setuid의 예1)
그렇다면 setuid의 예를 하나 들어보도록 할까요? 아래와 같이 root가 파일 하나를 만들고 본인만 읽을 수 있게 만들어 놓았습니다.
그리고 root 사용자는 아래와 같은 코드로 이 파일을 읽는 코드를 짜서 실행파일을 만들었습니다.
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <fcntl.h>
int main(){
int fd=open("root_read_only.txt",O_RDONLY);
int n;
char buf[128];
printf("uid:%d\n",getuid()); //실제 사용자 ID
printf("euid:%d\n",geteuid()); //이 프로그램을 실행할때만 갖는 ID
n=read(fd,buf,sizeof(buf));
if(n<0){
printf("파일을읽을 수 없습니다. erorr code:%d\n",n);
exit(1);
}
printf("file content:%s\n",buf);
}
root 사용자가 이 실행파일의 주인이고 실행파일의 권한은 모든 사용자가 실행할 수 있게 만들었습니다.
이제 다른 사용자인 ubuntu가 이 read.out이라는 실행파일을 실행하게 되면 아래의 내용과 같이 나옵니다. 지금 현재 uid는 1000이고 euid도 1000이라서 root_read_only.txt를 볼 수 없습니다. 왜냐면 root_read_only.txt는 오직 root만 읽을 수 있게 설정했거든요.
이때 이 실행파일이 실행될때만 루트의 권한을 갖도록 하여 파일을 읽을 수 있게 하는 방법은 euid를 root로 설정하는 setuid를 주면 될텐데요. root 계정으로 그 권한을 줘보도록 하겠습니다. chmod u+s read.out으로 setuid를 줄 수 있고, 이때 rwsrwxrwx로 바뀌게 된것을 알 수 있습니다. 소유자의 실행권한인 s로 바뀐 것은 setuid가 설정되어 있는 파일이며 실행시에 파일의 소유자의 권한으로 실행된다는 것을 의미합니다.
이제 ubuntu라는 유저는 이 root_read_only.txt라는 파일을 읽을 수 있을까요? 그럴 수 있는지 read.out을 실행해보도록 합시다.
euid가 0으로 바뀐것을 확인할 수 있으면서 file의 내용을 읽어볼 수 있습니다.
setuid의 예2) passwd
setuid를 설명하기 위해서 임의로 제가 만든 하나의 예입니다. 리눅스에서 가장 대표적으로 setuid를 사용하는 실행파일은 /bin/passwd파일입니다. 이 파일은 사용자의 비밀번호를 바꾸는데, 필요한 명령어로 /etc/passwd를 수정해야합니다. 하지만 /etc/passwd는 절대 root만 수정할 수 있으므로 다른 사용자는 변경할 수가 없죠. 그렇지만 다른 사용자들이 비밀번호를 바꿀때 /etc/passwd를 수정해야하므로 수정 프로그램이 필요하고 그 파일이 바로 /bin/passwd파일입니다. /bin/passwd는 실행시에 루트권한으로 실행이되어 /etc/passwd파일을 수정할 수 있게 됩니다.
setgid
setgid 역시 비슷합니다. 실행시에 그룹의 권한을 갖는 다는 것인데요. 앞서 설명한 setuid와 개념은 비슷하며 그룹 권한에 s로 표시가 됩니다.
sticky비트
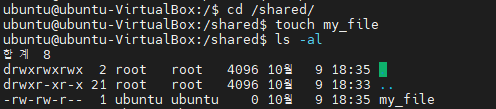
sticky비트는 다른 사용자가 자유롭게 디렉토리를 사용할 수 있도록 만드는 권한입니다. 원래 디렉토리도 디렉토리를 만든 사람만이 읽기, 쓰기가 가능합니다. 하지만 sticky를 쓰면 모든 사용자가 자유롭게 읽기, 쓰기가 가능합니다. 마치 공유폴더와 아주 비슷한 개념입니다. 이 권한은 디렉토리에만 해당되는 권한입니다. 예를 들어설명해볼까요?
아래와 같이 root는 공유폴더를 만들 목적으로 디렉토리를 하나 만들었습니다. 하지만 권한을 주지는 않았죠.
그래서 ubuntu라는 유저는 이 디렉토리에 파일을 기록하려고 했으나 아래와 같이 권한이 없다는 메시지를 받게 됩니다.
아래와 같이 root는 다른 유저에 대해서 sticky비트를 설정합니다.
이렇게 되면 아래와 같이 ubuntu는 /shared 디렉토리를 자유롭게 이용할 수 있습니다.
여기까지 리눅스 파일의 실행권한과 setuid, setgid, sticky에 대한 개념을 알아보았습니다. 최대한 쉽게 예를 들어 설명하려고 했는데, 이해가 가셨는지 모르겠네요.
2. 두번째 방식 : 옵션과 함께 정규표현식으로 PATTERNS을 정의하고 주어진 파일들에서 찾습니다.
3. 세번째 방식 : 옵션과 함께 파일에 정의된 PATTERN을 주어진 파일들에서 찾습니다.
FILE을 지정하는 방법에 따른 검색
FILE은 찾을 대상의 파일을 의미합니다. 찾을 파일들을 명시적으로 지정하게 되면 그 파일만들 탐색합니다. 만약 -(대쉬, dash)이면 stdin에서 찾습니다. 즉, 키보드로 입력이 되면 패턴을 찾는다는 방식입니다. 만약 파일이 주어지지 않았다면 -r 옵션에 따라 다릅니다. -r 옵션이 주어지면 현재 디렉토리에 있는 파일들을 대상으로 하위 디렉토리까지 패턴을 찾습니다. 그렇지 않는다면 표준 입력(stdin)으로 입력받습니다.
이러한 예를 들어보도록 하겠습니다.
ex ) FILE을 명시
현재 디렉토리 /etc이며 여기서 shadow, passwd 파일에서 root 패턴을 포함하는 라인을 출력합니다.
grep은 기본적으로 파일을 지정하지 않는다면 stdin으로 입력을 받는다고 위에서 설명을 했었습니다. 리눅스에서 파이프는 어떤 명령어의 출력(정확히 이야기하면 표준 출력, stdout)을 다음 명령어의 stdin으로 넘겨줍니다. 그래서 이런 명령어 형식을 자주쓰게 됩니다.
명령어| grep "찾을 패턴"
예를 들면 현재 실행되는 프로세스 중에 ssh와 관련된 프로세스를 알아보고 싶다면 아래와 같은 조합으로 사용할 수 있습니다.
여러분들이 컴퓨터를 사용할때 가장 많이 사용하는 명령이 있습니다. 그 중 한가지 경우가 프로세스에 대한 정보를 알고 싶을 경우인데요. 예를 들어 어떤 프로세스가 수행중인데, 이 프로세스가 CPU를 굉장히 많이 소모시킨다고 합니다. kill 명령으로 그 프로세스를 종료시키고 싶지만 pid를 알아야하겠죠. 이때 pid등의 정보를 볼 수 있는 명령이 있습니다. 그 process의 상태를 알고 싶을때 매우 많이 사용하는 명령이 바로 ps입니다.
ps는 프로세스에 대한 많은 정보를 담고 있고 매우 많이 사용되는 명령으로 옵션이 매우 다양합니다. ps는 옵션에는 세가지 종류가 있습니다.
1. Unix Option : 앞에 '-' (dash)가 붙는 옵션 표기방법입니다.
2. BSD Option : '-' 를 붙이지 않습니다.
3. GNU Option : 명령어 앞에 '--' (double dash)를 붙입니다.
물론 Unix, BSD, GNU 옵션들을 모두 우리가 알 수도 없고, 외울 수도 없지만 그래도 유용한 옵션정도는 알고 있어야겠죠?
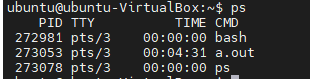
기본 ps 명령어 구성
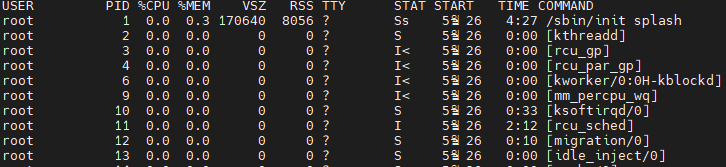
ps 명령어를 치면 아래와 같이 나오게 됩니다. 별로 몇개 나오지 않는 다는 것을 알 수 있는데, 이것은 ps가 기본적으로 같은 EUID(Effective User ID)의 프로세스이며 같은 터미널의 프로세스만을 골라서 보여주기 때문입니다.
보여주는 정보는 프로세스 ID(PID), 터미널(TTY), CPU 점유 시간(TIME), 그리고 프로세스가 수행된 명령어(CMD)입니다. 여기서 a.out은 제가 임의로 무한 루프를 돌린 프로세스를 실행시켜서 그렇고 시간은 TIME이 00:04:31인것을 볼 수 있네요.
ps -e, -A : 모든 프로세스를 보여줍니다.
ps -a : 세션 리더와 터미널과 연관된 프로세스들을 제외한 모든 프로세스를 보여줍니다.
ps -d : 세션 리더를 제외한 모든 프로세스를 보여줍니다.
ps -f : full format으로 세션의 정보를 표시합니다.
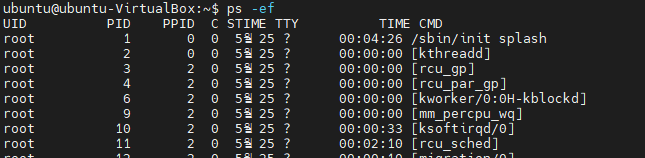
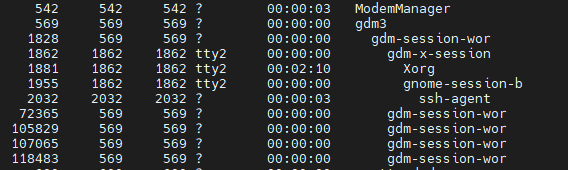
ps -ef : -e와 -f의 옵션 조합인데, 모든 프로세스를 full format으로 보여줍니다. 아래는 그 결과를 보여줍니다. UID, PID, PPID, C, STIME, TTY, TIME, CMD의 정보를 볼 수 있네요. TTY(연결 터미널)가 없으면 대부분 데몬 혹은 커널 프로세스입니다.
ps -ef 결과1ps -ef 결과 2
ps -u userlist : EUID 혹은 유저 이름으로 프로세스를 고릅니다. 이때 여러 uid를 줄수 있는데 ','(comma)로 구분하여 명시해줍니다. euid는 프로세스가 수행할때 갖는 유저 권한을 말합니다.
ps -U userlist : -u 옵션과는 동일하나 RUID가 갖는 프로세스만을 찾아냅니다. ruid는 real user id라는 것으로 실제 프로그램을 실행한 uid를 의미합니다. 이때도 쉼표로 여러 uid를 지정할 수 있습니다.
ps -p pidlist : 프로세스 id가 일치하는 프로세스를 출력합니다. 여러 pid들을 뽑아내고 싶다면 마찬가지로 ','(comma)로 pid를 구분하여 명시해줄 수 있습니다. 이 명령은 ps --pid pidlist와 같습니다.
ps --ppid pidlist : 부모 프로세스 id와 일치하는 프로세스를 출력합니다. 역시 여러 ppid를 ','(comma)로 구분가능합니다.
ps -t ttylist : tty와 일치하는 프로세스들을 출력해줍니다. 이 명령은 t 혹은 --tty 옵션과 같습니다.
ps -o format : 사용자가 지정한 format대로 출력합니다. format에 대해서는 설명이 길지만 간략하게 원하는 column만 보여준다고 기억하시면 됩니다. 예를 들어 사용자가 임의로 pid, ppid, cmd, uid 등을 표시할 수 있습니다.
다음의 표는 format에 대해 정리한 표입니다.
CODE
NORMAL
HEADER
%C
pcpu
%CPU
%G
group
GROUP
%P
ppid
PPID
%U
user
USER
%a
args
COMMAND
%c
comm
COMMAND
%g
rgroup
RGROUP
%n
nice
NI
%p
pid
PID
%r
pgid
PGID
%t
etime
ELAPSED
%u
ruser
RUSER
%x
time
TIME
%y
tty
TTY
%z
vsz
VSZ
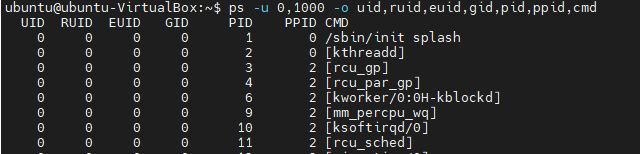
아래의 예는 uid가 0, 1000인 프로세스를 출력하는데, uid, ruid, euid, guid, pid, ppid, cmd를 출력해줍니다.
ps -u userlist -o format
ps aux : BSD 문법으로 실행중인 모든 프로세스를 나타냅니다. ps -aux와는 다른 옵션입니다.
ps aux
위의 보이는 것 중에 프로세스의 상태를 나타내는 STAT 혹은 S는 아래의 코드로 구성됩니다. 다른건 필요없고 Z나 <defunct>로 표시된 프로세스는 좀비 프로세스로 자원을 점유하므로 시스템 관리가 필요합니다. 반드시 없애야합니다.
Code
Desc
D
Uninterruptible sleep
Idle
Idle kernel thread
R
Running or runnable
S
Interruptible sleep
T
stopped by job control signal
t
stopped by debugger during tracing
W
paging
X
dead
Z
defuct (zombie) process
BSD format에서는 추가 문자가 쓰일 수 있습니다.
Character
Desc
<
high-priority(not nice to other users)
N
low-priority(nice to other users)
L
has pages locked into memory
s
is a session leader
l
is multi-threaded
+
is in the foreground process group
ps | grep - 원하는 프로세스만 추출
대개 ps명령은 많은 결과를 출력하는데 이때 grep을 이용하여 원하는 프로세스를 찾을 수 있습니다. 예를 들면 sshd와 관련된 프로세스를 찾기를 원하면 이렇게 사용할 수 있습니다.
ps -ef | grep sshd
ps -ejH
프로세스를 트리 형태로 조금 보기 좋게 표시하고 싶다면 -ejH옵션을 사용하면 됩니다. 자식 트리면 CMD가 한칸 띄어져서 출력이 됩니다.
ps -ejH 1ps -ejH 2
사실 트리모양으로 보기 좋게 출력하고 싶다면 아래의 pstree 명령이 더 보기 좋습니다.
pstree
여러분이 트리 형식으로 실행중인 프로세스를 보고 싶으시면 pstree 명령을 사용하시면 됩니다. 이 트리는 기본적으로 init 혹은 systemd 프로세스가 루트인데, 만약 pid를 명시한다면 그 pid가 루트가 됩니다.
pstree
이상으로 ps명령어와 옵션에 대해서 포스팅을 했습니다. 사실 모든 옵션을 사용할 일은 없습니다. 저는 ps -ef | grep 만 사용하게 되던데, 저도 나중에 참고할 겸 포스팅을 했습니다.
0 : 숫자 0을 누르면 그 줄의 맨 앞으로 커서가 이동합니다. 빈칸을 포함하여 맨 앞으로 이동합니다.
^ : 0과 같이 줄 맨 앞에 커서를 위치하지만 글자앞으로 이동합니다.
ex)
reakwon.tistory.com
ㄴ 0을 누를때 커서 ㄴ^를 누를때 커서
+ : 커서를 다음줄의 첫 글자로 이동합니다.
- : 커서를 이전 줄의 첫 글자로 이동합니다.
gg : 커서를 문서의 맨 처음 줄로 위치합니다.
G : 커서를 문서의 맨 마지막 줄으로 위치합니다.
w : 다음 단어의 첫 글자로 이동시킵니다. 특수문자 발견시 멈춥니다.
W : 다음 단어의 첫 글자로 이동시킵니다. 단어를 공백으로 구분합니다. 따라서 공백 이후를 다음 단어로 취급합니다.
b : 단어의 첫글자로 이동시킵니다. 특수문자 발견시 멈춥니다.
B : 단어의 첫글자로 이동시킵니다. 단어의 구분을 공백을 기준으로 합니다.
% : 짝이 되는 괄호의 위치까지 이동합니다. 만약 여는 괄호 '('에서 %을 누르면 짝맞는 ')'까지 커서가 이동합니다. 만약 선택이 된 상태에서 %를 누르면 그 괄호내용 모두를 선택할 수 있습니다. 이 기능을 폴딩할때 이용이 될 겁니다.
2. 입력
명령에서 대문자 명령을 소문자 명령의 반대의 기능을 하게 됩니다.
a : 현재 커서의 다음에 글자를 입력할 수 있습니다.
A : 현재 줄의 맨 끝에 글자를 입력할 수 있습니다.
i : 현재 커서에서 글자를 입력할 수 있습니다.
I : 현재 줄의 맨 앞에 글자를 입력할 수 있습니다.
o : 커서의 아랫줄에 입력할 수 있습니다.
O : 커서의 윗줄에 입력할 수 있습니다.
3. 화면 이동
Ctrl + f : 한 화면 다음(아래)으로 이동합니다. 보다 빠른 이동을 할때 좋습니다.
Ctrl + b : 한 화면 이전(위)으로 이동합니다.
4. 선택
v : 기본적으로 v를 누르고 방향키로 텍스트를 선택합니다.
4. 삭제, 되돌리기
d : 선택 영역을 삭제합니다. 이떄 선택은 위에 등장한 v로 선택합니다.
dw : 현재 커서부터 다음 단어(공백 포함, 특수문자 제외)까지 모두 지웁니다. 이것을 응용하면 bdw가 왜 한 단어를 삭제하는지 알 수 있습니다.
bdw : 현재 단어 삭제 (b - 단어 앞으로 이동, dw : 다음 단어까지 삭제)
dd : 한줄 전체를 삭제합니다.
ndd : n개의 줄을 한번에 삭제시킵니다.
u : 만약 잘못 삭제시켰다면 u를 눌러서 되돌릴 수 있습니다. 삭제 뿐만 아니라 모든 명령에서 실수했다 싶으면 u로 되돌리시면 됩니다.
5. 복사 & 붙여넣기
y : 선택한 영역을 복사합니다. 선택은 v로 선택할 수 있습니다.
yw : 현재부터 한 단어의 끝까지 복사할 수 있습니다.
byw : 현재 커서가 위치한 이 단어를 복사합니다.
yy : 한줄 복사를 할 수 있습니다.
nyy : n줄 복사
p : 현재 커서 아랫줄에 복사한 텍스트 붙여넣기
6. 단어 찾기
/찾을단어
n : 다음 단어 찾기
N : 이전 단어 찾기
이 방법은 아주 단순하긴한데 정확히 그 문자와 일치하는 단어만 검색합니다. 즉, 대소문자를 구분해서 검색하는 방법입니다. 대소문자 구분없이 검색하기를 원한다면 끝에 \c를 붙여주면 됩니다. 이렇게요
/찾을단어\c
이때는 대소문자 구분없이 찾을 수 있습니다.
7. : 기본 명령어 - ESC를 누르고 ':'를 누른 상태
: set nu - 줄 표시를 합니다. 코드에서 라인을 확인하고 싶다면 아래의 명령으로 볼 수 있습니다. 혹은 set number를 full로 쳐주어도 됩니다.
: set nonu - 줄 표시를 해제합니다. 더 이상 라인을 보고싶지 않으면 이 명령으로 해제할 수 있습니다.
: 숫자 - 한번에 라인을 이동하고 싶으면 숫자를 치고 이동할 수 있습니다.
: w - 지금 수정된 사항을 write한다는 것으로 저장을 의미합니다. 하지만 vi 프로그램을 닫지는 않습니다.
: wq - 수정된 사항을 저장하고 나가겠다(quit)는 명령입니다. vi 프로그램을 저장함과 동시에 닫는 명령입니다.
: q! - 어떨때는 vi 편집기가 수정했는데 저장하지 않는다는 이유로 놓아주지 않는 경우가 있는데 이떄 저장하기 싫다면 q!를 사용하면 됩니다.
: set ts=n - 탭의 간격을 조절하는 명령어로 n은 숫자입니다. 예를 들어 set ts=4인 명령을 내린다면 탭의 간격은 공백 4개와 같은 간격을 갖습니다.
창분할 - 2가지가 존재합니다.
: sp - 현재 창을 평행 분할합니다. 다음 창은 Ctrl+w,w (Ctrl 누른 상태에서 w를 두번 누름)로 이동할 수 있습니다.
: sp [filename] : 파일 이름을 지정해주면 그 파일이 열립니다.
: vs - 현재 창을 수직 분할 합니다. 마찬 가지로 다음 창은 Ctrl+w,w로 이동할 수 있습니다.
: vs [filename] : 마찬가지로 파일 이름을 지정해서 현재 파일이 아닌 다른 파일을 열 수 있습니다.
8. 단어 변경
:s/현재단어/바꿀단어
현재 단어와 일치하는 하나의 단어만을 변경합니다.
만약 문서 전체의 단어를 변경하고 싶으시면 앞에 %를 붙여주면 됩니다.
:%s/현재단어/바꿀단어
:%s/현재단어/바꿀단어/g
전체 문서에서 현재단어를 바꿉니다.
:시작 줄 번호, 끝 줄 번호s/현재단어/바꿀단어
혹은 줄번호를 주어 제약을 걸어서 시작 줄, 끝 줄에 있는 단어를 바꿀 수도 있습니다.
:%s/현재단어/바꿀단어/i
현재 단어의 대소문자를 무시하고 일치하면 단어를 치환합니다. i는 ignore를 의미하지요.
간혹가다가 위도우즈의 파일을 리눅스로 가져오면 ^M문자가 섞여 들어올때가 있습니다. 이때 ^M문자를 없애려면 아래와 같은 명령을 통해 깔끔하게 없앨 수 있습니다.
%s/^M$//g
9. 탭 추가
: tabnew [filename] - 현재 vi 창에 새로운 tab을 생성합니다. 기존의 파일을 열 수도 있고 아니면 새로운 파일을 열어서 편집할 수도 있습니다. 예를 들어 list.txt이라는 파일을 탭으로 생성하려면 아래의 명령을 통해서 가능합니다.
원래 열었던 파일(test)과 새로운 파일인 list.txt가 같이 열려있다는 것을 알 수 있고, 편집도 가능한 것을 알 수 있습니다.
gt : 다음 탭으로 이동합니다. 위의 경우에는 다음 탭이 없으므로 test 탭으로 이동합니다.
gT : 이전 탭으로 이동합니다. 위의 경우에서 이전 탭은 test이므로 test 탭으로 이동하지요.
탭 안에서 편집은 이제 vi 편집기의 명령어를 가지고 똑같이 편집하고 저장할 수가 있습니다.
10. 코딩에 도움이 되는 몇가지 명령어
헤더파일 열어 확인하기
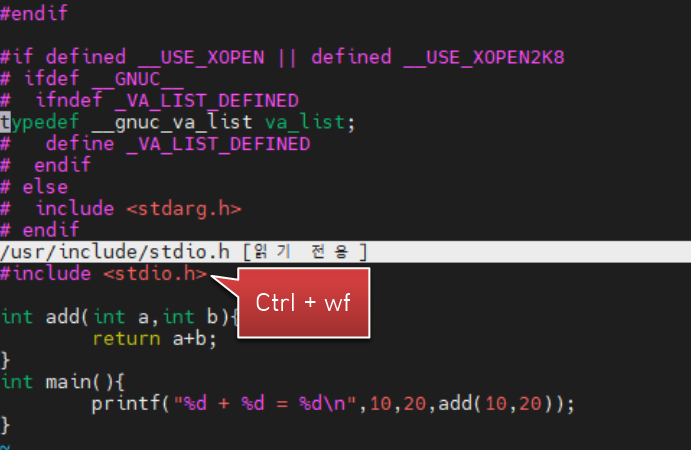
헤더파일에 ctrl+wf를 누르면 헤더파일의 내용을 창분할로 볼 수 있습니다. 아래와 같이 stdio.h의 내용을 보고 싶으면 커서를 헤더파일 이름에 위치시키고 ctrl 키와 w,f 를 차례대로 누르면 됩니다.
폴딩하기
코드가 너무 길어 보기좋게 내용을 접고싶다면 폴딩기능을 사용할 수 있습니다. 아래처럼 v로 함수 모두를 선택해봅시다. v를 누르고 화살표로 선택할 수 있지만 함수가 긴 경우에는 다음과 같이 한번에 선택할 수 있습니다.
우선 함수 가장 앞에 'v'를 눌러 선택 모드로 지정하시구요. '$'를 눌러 가장 맨 끝 줄로 이동합니다. 가장 맨 끝 줄에는 함수를 여는 중괄호가 있습니다. 이때 '%'를 누르면 함수 전체를 선택하게 됩니다.
함수 선택
zf : 폴딩하려면 함수가 모두 선택된 상황에서 zf를 누르면 됩니다.
zi : 폴딩된 상태에서 함수를 보고 싶어서 피거나, 아니면 핀것을 다시 접으려면 zi를 입력하면 됩니다. 이 명령어는 토글방식으로 접었다 폈다할 수 있습니다.
한번에 들여쓰기하기
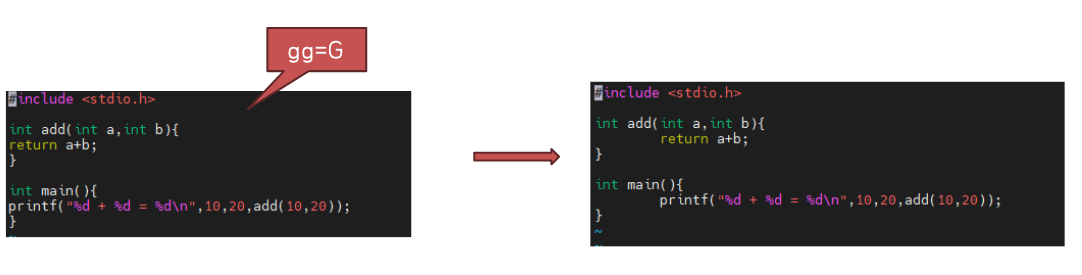
여러분이 코드를 복사하다가 보면 어쩌다가 들여쓰기가 안된 상태로 복사가 될 때도 있습니다. 이때 노가다로 탭을 눌러서 늘리면 시간이 꽤나 걸리겠죠. 이때 한번에 들여쓰기하는 방법이 "gg=G"입니다.
커서가 어디에 있건 상관없습니다. gg는 문서의 맨앞을 의미, G는 문서의 끝을 의미합니다. =은 tab의 간격으로 들여쓰기 하라는 명령이죠. 즉, 문서의 처음부터 끝까지 들여쓰기하는 명령어입니다.
문서 전체 들여쓰기
자동 완성
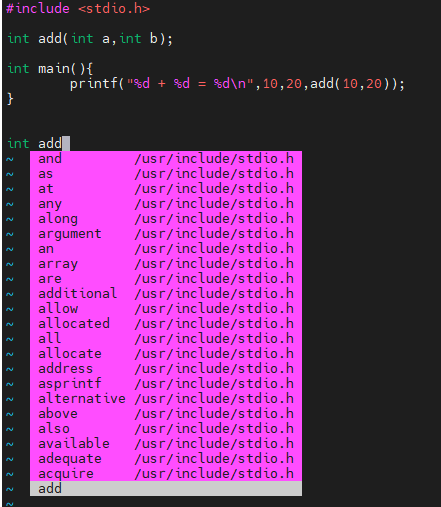
다른 IDE를 사용할때 자동완성 기능이 있죠? "vi 편집기는 왜 그런게 없는거야" 라고 하시지 마시고 구글에서 그런 기능을 하는 명령어가 무엇인지 찾아보세요. 답은 ctrl + p , ctrl + n입니다. 둘 다 자동완성 기능을 하지만 어느쪽으로 펼쳐지느냐만 다를 뿐입니다. 문자를 쓰는 편집 모드에서 ctrl + p, ctrl + n을 사용해야합니다. esc 누르고 사용하는게 아닙니다.
SED는 Stream Editor의 약자로 sed라는 명령어로 원본 텍스트 파일을 편집하는 유용한 명령어입니다. 리눅스의 editor라하면 생각나는 에디터가 있지 않나요? vi 편집기가 대표적인데, 여러분들이 vi편집기로 편집할때는 vi filename의 명령을 이용해서 파일을 열고 난 이후에 각종 vi 명령어를 통해서 이리 저리 움직여 추가, 삭제, 변경 등의 편집을 하게 되죠. 그리고 작업이 다 끝나게 되면 저장 후 나가게 됩니다. 이때 여러분은 원래의 파일을 변경하여 저장하기 때문에 원본은 변경됩니다. 그리고 vi는 실시간 저장할 수가 있습니다. 여기서 sed는 vi 편집기와는 다르게 이런 차이점이 있습니다.
1. sed와 vi가 다른 점은 sed는 명령어 형태로 편집이 되며 vi처럼 실시간 편집이 아닙니다.
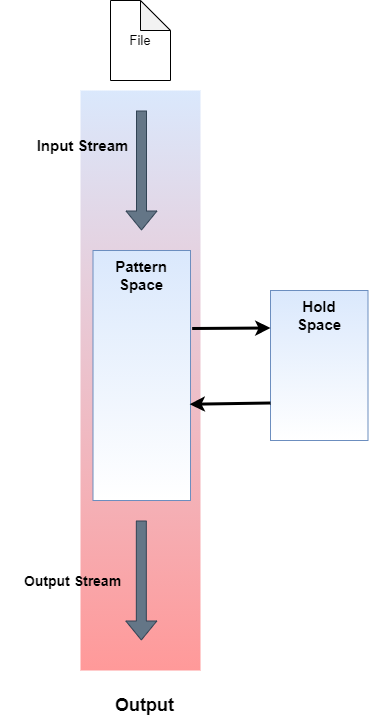
2. 원본을 건드리지 않고 편집하기 때문에 작업이 완료되었어도 기본적으로 원본에는 전혀 영향이 없다는 점입니다.(단, 여러분이 sed옵션에서 -i 옵션을 지정한다면 원본을 바꾸게 됩니다.) 그래서 내부적으로 특수한 저장 공간인 버퍼를 사용합니다. 두 가지 버퍼는 패턴 버퍼(패턴 스페이스라고도 합니다)와 홀드 버퍼(홀드 스페이스라고도 합니다)입니다.
아래의 그림을 보면 sed는 InputStream으로 파일의 내용을 가져옵니다. 그리고 난 후에 패턴 버퍼에 그 내용을 담고 있으며 데이터의 변형과 추가를 위해 다시 임시 버퍼를 사용하게 되는데, 그게 홀드 버퍼입니다. 그리고 작업이 전부 완료되었다면 패턴 버퍼에 그 내용이 담기는데, 그 내용을 OutputStream으로 보내주게 되면 비로소 우리가 원하는 결과가 출력되는겁니다. 기본적으로 OutputStream은 콜솔화면인 stdout입니다. 우리는 그냥 sed가 내부적으로 2개의 버퍼를 가지고 있다고 보시면 됩니다.
pattern space and hold space
이제 sed의 기본적인 개념을 알아보았으니 사용법에 대해서 알아보아야겠죠? 그 전에 sed에 대한 input 파일은 아래의 내용처럼 간단한 텍스트 파일로 하도록 하겠습니다. 필요에 따라 다른 text파일도 사용하도록 하겠습니다.
sed_test_file.txt
name phone birth sex score
reakwon 010-1234-1234 1981-01-01 M 100
sim 010-4321-4321 1999-09-09 F 88
nara 010-1010-2020 1993-12-12 M 20
yut 010-2323-2323 1988-10-10 F 59
kim 010-1234-4321 1977-07-17 M 69
nam 010-4321-7890 1996-06-20 M 75
sol 010-5911-1111 1976-10-12 F 60
lee 010-4949-4949 1988-09-30 F 80
feng 010-1111-9999 1979-03-20 M 90
기본적으로 sed는 아래와 같은 형태로 사용합니다.
sed -n -e 'command' [input file]
-n : sed는 pattern buffer의 내용을 자동적으로 출력해주는데, 이 옵션을 사용하게 되면 자동 출력을 하지 않습니다. -n옵션을 하지 않고 sed명령을 해보시면 눈에 띄게 많은 데이터가 출력되는것을 확인할 수 있습니다. 매우 지저분하지요. 그래서 -n옵션을 붙여 패턴 버퍼의 자동출력을 하지 않습니다. 여러분은 그래서 sed 명령의 기본 형태는 sed -n으로 생각하시면 됩니다.
-e : 이 옵션 다음으로는 우리가 사용할 command를 가지고 텍스트 파일을 가공해줍니다. -e의 command에는 어떤 종류가 있는지 확인해보도록 합시다.
그리고 맨 마지막에는 우리가 가공할 원본 파일을 지정해주면 됩니다.
1. 특정 행을 출력 - p (print)
1-1. 천재 내용을 출력 : 기본적으로 전체의 줄을 출력하려면 command에 /$/p 또는 1,$p로 출력해볼 수 있습니다.
sed -n -e '1,$p' sed_test_file.txt
sed -n -e '/$/p' sed_test_file.txt
1-2. 첫번째 줄 출력 : 여러분이 첫번째 줄만 출력해주기를 아래의 command를 사용할 수 있습니다.
sed -n -e '1p' ./sed_test_file.txt
name phone birth sex score
끝 p는 print의 p를 의미합니다.
1-3. start ~ end 줄까지 출력 : 그렇다면 첫째줄부터 4번째줄을 출력하기를 원한다면 쉼표로 구분된 출력하길 원하는 줄, 마지막 줄 p 의 형태를 사용하면 됩니다.
sed -n -e '1,4p' sed_test_file.txt
name phone birth sex score
reakwon 010-1234-1234 1981-01-01 M 100
sim 010-4321-4321 1999-09-09 F 88
nara 010-1010-2020 1993-12-12 M 20
1-4.특정줄에서 마지막 줄까지 출력 : 어떤 줄에서 마지막 줄까지 출력하려면 $문자를 사용하면 됩니다. $는 마지막줄을 의미합니다. 그래서 5번째 줄에서 마지막줄까지 출력하려면 아래와 같은 command를 사용할 수 있습니다.
sed -n -e '7,$p' sed_test_file.txt
nam 010-4321-7890 1996-06-20 M 75
sol 010-5911-1111 1976-10-12 F 60
lee 010-4949-4949 1988-09-30 F 80
feng 010-1111-9999 1979-03-20 M 90
1-5. 다중 command 사용 : 만약 command를 여러개 사용하고 싶다면 -e 옵션을 이용해서 여러개 사용하여 command를 줄 수 있습니다. 만약 1번째 줄을 출력해주고, 8번째 줄부터 끝까지 출력하기를 원한다면 아래의 명령을 사용하면 됩니다.
sed -n -e '1p' -e '8,$p' sed_test_file.txt
name phone birth sex score
sol 010-5911-1111 1976-10-12 F 60
lee 010-4949-4949 1988-09-30 F 80
feng 010-1111-9999 1979-03-20 M 90
1-6. 특정 문자열이 있는 줄 출력
만약 위의 파일에서 여자(F, Female)만 출력한다고 하다면 어떻게 command를 어떻게 사용할까요? 아래와 같은 형식대로 사용하면 됩니다.
/포함된 문자열/p
텍스트 파일에서 우리가 찾을 문자열이 포함된 줄을 출력(p, print)한다고 생각하시면 됩니다. 아래의 명령이 여성만 뽑아내는 command입니다.
sed -n -e '/F/p' sed_test_file.txt
2. 특정 행 삭제 - d (delete)
행삭제에 관한 명령어는 d를 사용하면 됩니다. d를 사용하는 것외에는 위의 줄 출력을 해주는 명령어 형태로 사용하면 됩니다.
2-1. 2~6번째 줄을 삭제하고 나머지 모든 내용을 출력
sed -n -e '2,6d' -e '1,$p' sed_test_file.txt
name phone birth sex score
nam 010-4321-7890 1996-06-20 M 75
sol 010-5911-1111 1976-10-12 F 60
lee 010-4949-4949 1988-09-30 F 80
feng 010-1111-9999 1979-03-20 M 90
3. 단어 치환(Substitute) - s (substitute)
이제부터는 출력결과는 생략하도록 하겠습니다. 특정 단어를 치환하려면 s명령을 이용하면 됩니다. 형식은 아래와 같습니다.
3.1 기본적인 특정 단어 치환
s/old/new/g
s/old/new/gi
단어 s는 substitute(치환)의 약자, 그리고 /로 구분하여 old는 단어를 치환할 문자열, new는 새롭게 치환한 문자열인데 비어있으면 그 문자열을 삭제한 효과를 가질 수 있습니다. g는 global의 약자로 전체에 적용됨을 의미합니다.
두번째의 i는 ignore case의 약자로 old의 단어를 검색할때 대소문자 구분하지 않겠다는 것을 의미합니다.
아래 명령의 결과를 보고 차이점을 확인해보세요.
sed -n -e 's/reakwon/reak/g' -e '2p' sed_test_file.txt
sed -n -e 's/reakwoN/reak/g' -e '2p' sed_test_file.txt
sed -n -e 's/reakwoN/reak/gi' -e '2p' sed_test_file.txt
3.2 특정 단어로 시작 혹은 끝나는 단어를 포함하는 라인의 문자열 치환
특정단어로 시작하는 단어로 문자열을 치환하는 것도 가능합니다. 특정 단어로 시작하는 줄을 선택하려면 앞에 '^'문자를 사용하면 되죠. 사실 정규표현식을 아신다면 앞에 ^가 붙는다면 ^이후에 나오는 문자열로 시작되는 문자열들을 추출한다는 것을 아실겁니다. 사실 몰라도 외워서 아시면 됩니다. 단 많이 실수하시는 부분이 특정 단어로 시작하거나 끝나는 문자열이 아닌 줄(line)입니다.
아래의 파일(let_it_go.txt)에서 Let으로 시작하는 줄의 첫 Let를 LET으로 바꿔보려면 다음 보이는 명령을 사용하면 됩니다.
Let it go, let it go.
Can't hold it back anymore.
Let it go, let it go.
Turn away and slam the door.
I don't care what they're going to say.
Let the storm rage on.
The cold never bothered me anyway.
sed -n -e 's/^let/LET/gi' -e '1,$p' let_it_go.txt
반대로 끝나는 문자열은 끝에 $를 붙여줘서 검색하면 됩니다. Anyway. 으로 끝나는 줄의 Anyway를 대문자로 바꾸려면 아래와 같은 command를 사용하면 됩니다.
sed -n -e 's/anyway.$/ANYWAY/gi' -e '1,$p' let_it_go.txt
4. 문자열 추가 - a, i (append, insert)
문자열을 추가하는 방법에는 두 가지 정도가 존재합니다. 해당 문자열 아래에 추가하느냐(Append) 아니면 이 전 줄에 삽입하느냐(Insert)가 있는데요. 기본적인 형식은 아래의 command처럼 사용합니다.
/찾을 문자열/a\다음 출에 추가할 문자열
/찾을 문자열/i\위에 삽입할 문자열
찾을 문자열 뒤에 추가할 문자열을 위의 형식대로 사용하면 됩니다. 위의 let_it_go.txt파일에서 bye로 끝나는 줄 다음에 end라는 줄을 넣고 싶다면 이렇게 사용하면 됩니다. 반대로 위에 추가하려면 a를 i로 바꾸면 되겠죠.
sed -n -e '/bye/a\end' -e '1,$p' let_it_go.txt
5. 특정 행의 내용을 전부 교체 - c (change)
c command를 이용해서 행의 내용을 바꿀 수 있습니다. command 형태는 이렇습니다.
/바꿀 행이 포함한 문자열/c\바꿀 행의 내용
예를 들어 Let으로 시작하는 줄의 내용을 바꾸고 싶다면 어떻게 할까요? 우선 ^를 사용하여 Let으로 시작하는 줄들을 찾고 c 커맨드로 바꿔질 줄 내용을 입력해주시면 됩니다.
sed -n -e '/^Let/c\Let it go X2' -e '1,$p' let_it_go.txt
6. 특정 행에 파일의 내용을 추가 - r (read)
혹은 파일의 내용을 줄에다가 추가할 수도 있습니다. 여기 우리가 내용을 추가할 파일이 존재합니다.
perfect.txt
PERFECT! EXCELLENT!
100으로 끝나는 줄에 저 텍스트 파일의 내용을 아랫줄에 첨가하려면 아래와 같은 명령을 사용하면 됩니다.
sed -n -e '/100$/r perfect.txt' -e '1,$p' sed_test_file.txt
name phone birth sex score
reakwon 010-1234-1234 1981-01-01 M 100
PERFECT! EXCELLENT!
sim 010-4321-4321 1999-09-09 F 88
nara 010-1010-2020 1993-12-12 M 20
yut 010-2323-2323 1988-10-10 F 59
kim 010-1234-4321 1977-07-17 M 69
nam 010-4321-7890 1996-06-20 M 75
sol 010-5911-1111 1976-10-12 F 60
lee 010-4949-4949 1988-09-30 F 80
feng 010-1111-9999 1979-03-20 M 90
이상으로 sed에 대한 기본 개념과 사용방법, 그리고 예제를 살펴보았습니다. 여러분이 정규표현식을 사용하여 깊게 사용할 수도 있지만, 저는 정규표현식을 거의 사용할 일이 없으니 여기까지 하도록 하겠습니다. 이정도만 알아도 sed 명령을 사용하는 것에는 불편함이 없을 겁니다.
리눅스의 어떤 다른 명령어보다 명령어 이름이 매우 직관적이지 않은 명령어입니다. 이 명령어를 개발한 사람들의 이름 약자(Aho Weinberger Kernighan)이기 때문에 mkdir(make directory), rm(remove) 같은 의미를 축약하여 만든 명령어와는 명령어 이름이 좀 그렇습니다. 이 명령어를 읽을때는 주로 오크라고 읽습니다. AWK는 유닉스에서 개발된 스크립트 언어로 텍스트가 저장되어 있는 파일을 원하는 대로 필터링하거나 추가해주거나 기타 가공을 통해서 나온 결과를 행과 열로 출력해주는 프로그램입니다. 엄청나게 막강하고 다양한 기능을 담고 있기 때문에 여기서는 어떻게 사용하는지에 대해서만 알아보도록 하겠습니다.
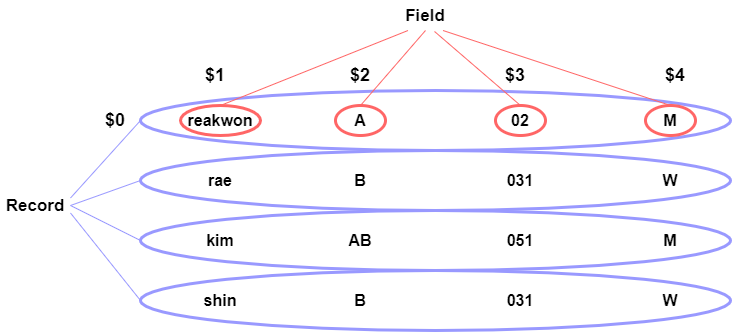
그 전에 간단하게 기본 용어만 짚고 넘어가도록 합시다. 아래는 하나의 텍스트 파일에 기록된 내용을 보여주고 있습니다. 여기서 각 단어들은 공백으로 구분되어 집니다. 각 줄(line)은 레코드(Record)라고 칭합니다. 그리고 그 안에 각각의 단어들이 필드(Field)가 되겠습니다.
AWK에서는 레코드가 $0, 그리고 $1, ..., $N 은 필드를 나타내는 열을 나타냅니다. 우리들이 사용할 파일은 위 내용은 아니고 아래의 내용을 담고 있습니다.
file : awk_test_file.txt
name phone birth sex score
reakwon 010-1234-1234 1981-01-01 M 100
sim 010-4321-4321 1999-09-09 F 88
nara 010-1010-2020 1993-12-12 M 20
yut 010-2323-2323 1988-10-10 F 59
kim 010-1234-4321 1977-07-17 M 69
nam 010-4321-7890 1996-06-20 M 75
awk의 기본 사용법은 패턴(pattern)과 액션(action)을 정의하여 입력으로 주어진 파일의 데이터를 가공하여 출력합니다. 이제부터 예를 볼 겁니다. 패턴과 액션 중 하나만 사용하여도 무관합니다.
awk pattern {action}
1. 열(Column)만 출력하기
각 $1, $2, $3 ... 은 열에 대응한다고 했었죠. 그리고 $0는 레코드에 대응한다고 했습니다. 여기서 이름만 모두 출력하겠다고 한다면 아래와 같이 awk 명령을 수행하면 됩니다.
awk '{ print $1 }' ./awk_test_file.txt
name
reakwon
sim
nara
yut
kim
nam
여러개의 열도 출력 가능합니다.
awk '{ print $1,$2 }' ./awk_test_file.txt
name phone
reakwon 010-1234-1234
sim 010-4321-4321
nara 010-1010-2020
yut 010-2323-2323
kim 010-1234-4321
nam 010-4321-7890
여기서 awk의 기본적인 action은 print이며 모든 열을 전부 출력합니다.
2. 특정 pattern이 포함된 레코드 출력
다음의 awk 명령은 rea라는 문자열이 포함된 레코드를 출력해주는 명령입니다.
awk '/rea/' ./awk_test_file.txt
reakwon 010-1234-1234 1981-01-01 M 100
3. 출력의 내용 첨가
awk는 print에 문자열을 추가하여 출력물의 내용에 문자열을 추가할 수 있습니다. 만약 이름을 명시적으로 나타내기 위해 "name : " , 그리고 휴대폰 번호를 명시적으로 나타내려고 "phone : " 를 추가해서 출력하고 싶다면 아래의 awk 명령을 사용하면 됩니다.
name : name , phone : phone
name : reakwon , phone : 010-1234-1234
name : sim , phone : 010-4321-4321
name : nara , phone : 010-1010-2020
name : yut , phone : 010-2323-2323
name : kim , phone : 010-1234-4321
name : nam , phone : 010-4321-7890
4. 특정 Record를 검색하기 - if 구문
4-1. ~이상 , ~ 이하의 레코드 출력
만약 위의 파일에서 점수가 80점 이상인 사람들의 레코드를 알고 싶다면 어떻게 하면 좋을까요? 이거는 pattern을 써야할까요, action을 써야할까요? action에서는 if 구문이 존재합니다. 그래서 이렇게 사용하면 80점 이상인 record를 출력할 수 있습니다.
name leng : 4 substr(0,3) : nam
name leng : 7 substr(0,3) : rea
name leng : 3 substr(0,3) : sim
name leng : 4 substr(0,3) : nar
name leng : 3 substr(0,3) : yut
name leng : 3 substr(0,3) : kim
name leng : 3 substr(0,3) : nam
이밖에도 모두 소문자로 출력하는 tolower함수, 모두 대문자로 출력하는 toupper 도 있습니다. 문자열을 쪼개는 split함수도 존재합니다. 여러 내장함수들이 있으니 필요시에 따라 사용하면 됩니다. 무엇이 있는지 어떻게 보냐구요? man 1 awk를 보시면 됩니다.
6. 반복문
반복문도 사용할 수 있습니다. C언어를 배우시는 분에게는 너무 익숙한 문법으로 사용할 수 있습니다. 아래는 단지 별의미 없이 for문의 사용법을 보여드리려 print를 2번까지 진행한 것입니다.
for loop :0 name phone birth
for loop :1 name phone birth
for loop :0 reakwon 010-1234-1234 1981-01-01
for loop :1 reakwon 010-1234-1234 1981-01-01
for loop :0 sim 010-4321-4321 1999-09-09
for loop :1 sim 010-4321-4321 1999-09-09
for loop :0 nara 010-1010-2020 1993-12-12
for loop :1 nara 010-1010-2020 1993-12-12
for loop :0 yut 010-2323-2323 1988-10-10
for loop :1 yut 010-2323-2323 1988-10-10
for loop :0 kim 010-1234-4321 1977-07-17
for loop :1 kim 010-1234-4321 1977-07-17
for loop :0 nam 010-4321-7890 1996-06-20
for loop :1 nam 010-4321-7890 1996-06-20
7. BEGIN, END pattern
BEGIN은 awk가 모든 레코드를 돌기 전에 한번 action을 수행하고 END는 모든 레코드를 다 돈 후에 마지막으로 정의한 action이 실행됩니다. 아래의 예에서 어떻게 사용되는지 살펴봅니다.
8. 변수 사용
awk 역시 언어이기 때문에 변수를 사용할 수 있습니다. 만약 우리가 위의 파일에서 총점과 평균을 구하고 싶다면 어떻게 하면 좋을까요? 레코드를 돌면서 각각의 점수를 더하면서 총점을 구하고, 총점을 사람의 수로 나누면 되지요. 그래서 구한 결과는 레코드가 끝난 마지막에 출력하면 되니 아까 이야기했던 END 패턴을 앞에 명시해줍니다. 아래의 awk가 그 명령입니다. 여기서 cnt가 -1부터 시작인 이유는 실제 레코드가 아닌 헤더가 존재하기 때문입니다. 이건 인원으로 볼 수 없죠. (name phone birth sex score)
awk '
> BEGIN {
> sum = 0
> cnt = -1
> }
>
> {
> sum += $5
> cnt++
> }
>
> END {
> avg = sum/cnt
> print ("sum :" sum ", average :" avg)
> }' ./awk_test_file.txt
BEGIN에서는 초기화가 이루어지고, END에서는 결과를 출력해줍니다. 프로그래밍 언어를 배우셨다면 cnt++이나 sum +=$5의 구문이 무엇인지 아실겁니다. 모르시는 분은 구글 서치해보세요. 어렵지 않습니다.
이상으로 awk에 대한 사용법과 내용을 추출하는 여러가지 예제를 보았습니다. 깊이 알면 좋지만 저는 그렇게 깊이 알아서 사용할 일은 없어 여기까지만 설명하도록 하겠습니다.
여러분들이 usb포트를 통해서 펜으로 그림을 그리거나, 무선 마우스를 이용해서 마우스를 조정할때 윈도우즈에서 usb드라이버를 설치해달라고 하지 않던가요? 물론 이미 드라이버가 설치되어있으면 상관없겠지만 처음 사용할 경우에는 usb드라이버를 설치해달라고 컴퓨터가 요청을 할겁니다. 윈도우즈는 그 장치가 무선 마우스인지, 키보드인지 구분할 수가 없으며 어떻게 조정을 해야하는지도 모르기 때문입니다. 그래서 컴퓨터가 이 장치를 동작시킬때 어떻게 동작되어야하는지에 대한 프로그램을 따로 설치해야합니다. 여러분들이 알게 모르게 설치했던 것이 바로 디바이스 드라이버입니다. 구경이나 한번 해볼까요? 시작 프로그램에서 장치관리자를 검색해서 들어가보세요.
장치 관리자
이후 사운드쪽에서 디바이스 하나의 속성을 보도록 합시다.
사운드 디바이스
드라이버 탭을 보면 정보와 업데이트, 사용안함 이런 버튼이 존재하는지 알 수 있습니다. 여러분들이 간혹가다가 멀쩡한 스피커에서 소리가 안들릴때 있지 않나요? 그때 한 방법은 컴퓨터를 reboot하는 방법이 있겠지만 아래의 디바이스 드라이버를 다시 구동시켜주면 됩니다. 어떻게 하냐구요? 간단합니다.
'디바이스 사용 안함' 을 눌러서 해제시키고, 다시 '디바이스 사용'을 눌러서 다시 장치를 구동시켜주면 어떨때는 해결되기도 합니다.
디바이스 속성
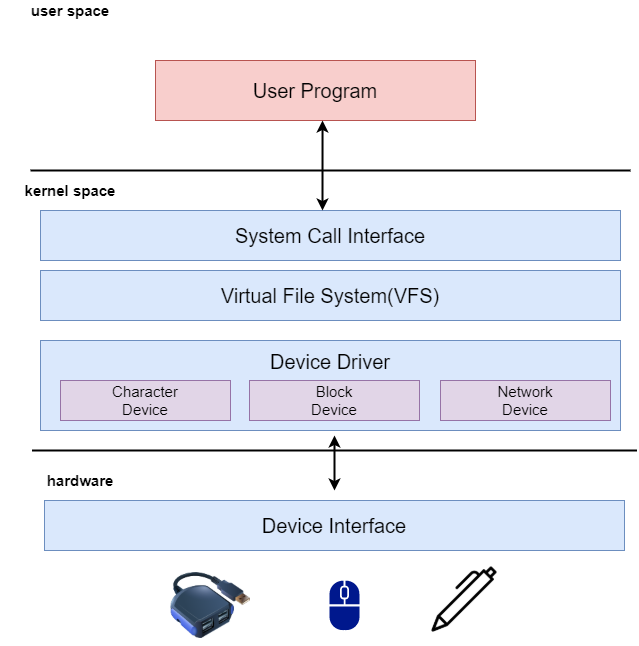
지금까지 간단하게 윈도우즈에서 디바이스를 살펴보았는데 자세히 그 내부를 들여다보면 아래의 도식과 같습니다. 사용자와 가장 접점에 있는 사용자 응용 프로그램 혹은 어플리케이션이 동작을 수행할때 내부적으로 System call을 사용합니다. open(), read(), write() 그런것들 있죠? 여러분들이 사용하는 printf()함수는 시스템 콜이 아니라 write를 잘 포장해서 만든 표준 입출력 라이브러리라고 합니다. 시스템 콜은 사용자 영역(kernel space)에서 호출이 가능합니다.
여기서 사용자 영역이라고 하는 것은 실제 앱을 이용하는 사용자가 아니고 여러분들이 코딩할때 실행 프로그램을 만드는 그 영역을 말하는 겁니다. gcc로 실행 파일을 만들고 실행하죠. 여기서 printf나 메모리 할당(malloc), 그리고 포인터를 이용해서 데이터를 바꾸는데 심한 제약이 있었나요? 정말 알수없는 프로그램을 짜지 않는 이상 그런 경우는 없지요. 간단히 말해서 '내가 마음대로 프로그램을 짜고 실행할 수 있는 공간이구나' 라고 생각하시면 됩니다.
device driver
시스템 콜이 호출이 되면 이제 커널 영역(kernel space) 내부로 호출이 전달됩니다. 커널 내부에 있는 가상 파일 시스템으로 전달, 그리고 아까 이야기했던 디바이스 드라이버가 인터페이스를 통해서 하드웨어를 제어합니다.
여기서 또 커널 영역이라함은 무엇일까요? 일반 사용자가 접근할 수 없는 커널만의 영역을 이야기합니다. 여러분들이 커널 영역 메모리를 참조하거나 데이터를 변경할 수 없습니다. 디바이스 드라이버가 커널 쪽에 위치해있으므로 커널 영역의 프로그램이라고 보시면 되는데, 커널의 메모리를 손대는 곳이기 때문에 항상 안전성에 주의해야합니다. 혹시나 여러분들이 블루 스크린을 경험해본적 있죠? 디바이스 드라이버나 커널에 의해 시스템이 사용할 수 없는 상태가 됐기 때문입니다.
리눅스 디바이스는 세가지가 존재합니다. 캐릭터 디바이스, 블록 디바이스, 네트워크 디바이스가 있지요.
모듈(Module)
커널의 일부분인 프로그램으로 커널에 추가 기능이 모듈로 관리가 됩니다. 여러분들이 다바이스 드라이버를 만들고 추가할때 커널의 모듈로 끼워넣으면 됩니다. 모듈은 커널의 일부분입니다. 디바이스 드라이버가 하드웨어를 동작해야하기 때문에 커널의 일부분으로 동작해야합니다. 그래서 커널 모듈로 동작되어지는데, 이때 착각하지 말아야할 점은 모듈은 커널의 일부, 그리고 그 모듈에서 디바이스 드라이버가 동작됩니다. 즉, 모듈은 디바이스 드라이버가 아닙니다. 디바이스 드라이버가 모듈로 커널의 일부분으로 추가되어 동작하는 것이지요.
모듈이라는 개념이 없을때 디바이스 드라이버를 만들었다면 커널이 바뀌었기 때문에 다시 커널 컴파일을 해야하는 과정이 있었죠. 커널 컴파일 과정은 오래 걸리는 작업이라서 시간을 많이 소비하는 작업이기도 합니다. 모듈의 개념이 도입된 이후 위의 과정없이 모듈을 설치하고 해제할 수 있습니다. 바로 이 모듈에서 장치를 등록하거나 해제할 수 있습니다. 예를 들어 문자형 장치를 등록할때는 아래의 함수를 이용하죠.
int register_chrdev(unsigned int major, const char *name, struct file_operations *fops);
아직까지는 이 함수가 어떤 역할을 하는지 몰라도 됩니다. 우선 모듈이 어떻게 등록이 되는지부터 보도록 하겠습니다. 아주 간단한 모듈 하나를 만들어보도록 하겠습니다. 우선 여러분들이 C 프로그래밍을 하듯이 아래의 코드를 작성해줍니다.
커널 모듈 빌드 디렉토리를 이용해야 하기 때문에 그 경로를 지정해줘야합니다. 이 디렉토리는 /lib/modules/커널 릴리즈 버전/build인데요. 여기서 커널 릴리즈 버전은 uname -r을 보면 알 수 있습니다. KERNDIR이 바로 그것이죠. 저의 경우는 아래와 같네요. 여기의 Makefile을 이용해야하기 때문에 기재해줘야하는 겁니다.
uname -r
또 우리가 만든 모듈은 현재 디렉토리에 있죠? pwd의 결과를 넣어주면 됩니다.
make를 하여 빌드합니다. 혹시 make 실행할 수 없다면 apt-get install make 해서 설치해주세요.
kernel object
make하고 빌드를 하면 산출물 중에서 .ko 파일이 보이실건데요. Kernel Object의 약자를 확장자로 갖고 있는 이것이 우리들이 설치할 모듈입니다. 설치해볼까요?
insmod
모듈을 설치하는 명령어는 insmod입니다. install module이죠. 자 이것을 이용해서 설치해봅시다. 사용법은 insmod [모듈명]으로 insmod mymodule.ko명령을 쳐보세요.
insmod
무소식이 희소식인 리눅스 세상에서 아무런 응답이 없으니 잘 설치된것 같은데요. 우리가 코드에서 init_module에서 printk로 문자열을 출력해주었죠? 모듈이 등록되었으니 분명 메시지가 나올테니 확인해보세요. dmesg | tail -1로 가장 마지막 줄을 확인해보도록 합시다.
hello, kernel!
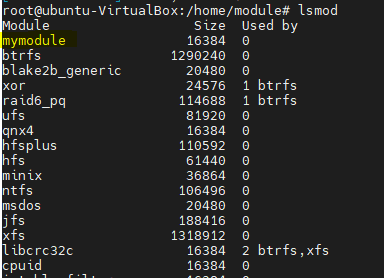
lsmod
우리가 설치한 모듈뿐만 아니라 설치된 다른 모듈도 보고싶다면 lsmod 명령을 사용하여 확인할 수 있습니다. 저의 머신에서는 아래와 같은 모듈들이 있습니다. 저의 모듈도 보이는군요.
lsmod
rmmod
마지막으로 모듈을 제거할때는 rmmod명령을 치면 됩니다. 사용법은 rmmod [제거할 모듈명] 으로 끝 확장자 .ko는 기재하지 않아도 상관없습니다.
rmmod
제거되었을까요? 우리가 코드에서 exit_module에서 전달한 함수가 있었죠? 그때도 우리는 printk로 메시지를 출력하게 만들었습니다. dmesg로 가장 마지막 메시지를 확인해보도록 합시다.
goodbye
커널 영역에서의 프로그래밍은 어려운 작업이고, 그것에 따른 세세한 조작을 할 수 있게 만들어줍니다. 예를 들어 커널 모듈을 통해서 우리는 시스템 콜을 후킹할 수도 있습니다. 아까 말씀드렸다시피 모듈은 커널의 일부분이며 반드시 디바이스 드라이버로 동작하지 않을 수 있지요.
이상으로 가장 간단한 리눅스 모듈을 만들어보았습니다. 최대한 쉽게 쓰려고 했는데 이해가 가셨나요?
파일은 서로 참조하고 참조 받을 수 있습니다. 그러니까 어떤 파일이 어떤 파일을 삿대질해서 가리킬 수도 있고(무척 평화적이죠? 현실세계에서는 참교육 시전받을 수 있습니다.) 같은 내용을 바라볼 수도 있다는 뜻입니다. 이러한 성질을 링크라고 합니다. 링크를 본격적으로 설명하기 전에 I-node라는 개념을 먼저 알아야 할 팔요가 있습니다.
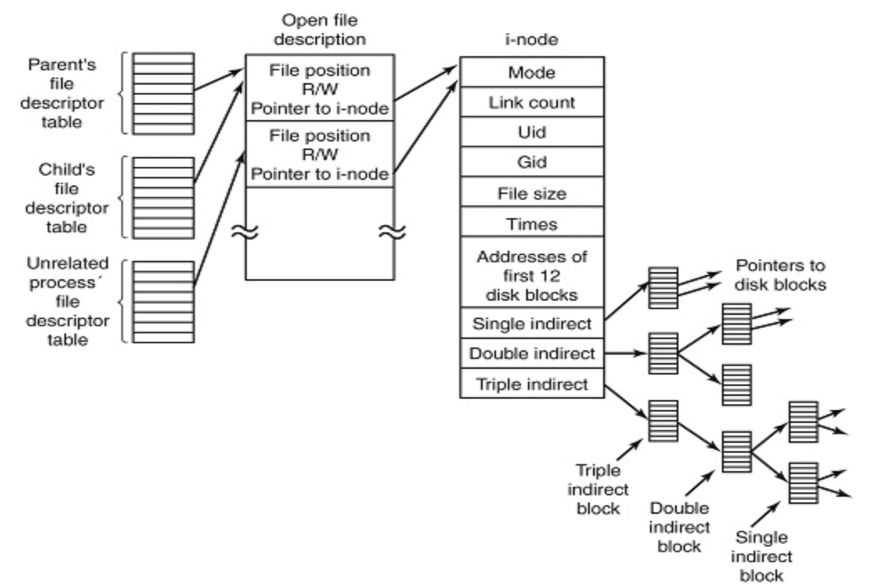
1. Inode
Inode는 아래에 보는바와 같이 i-node라는 구조체를 가리키게 됩니다. 이 i-node에는 파일에 대한 거의 모든 정보(파일 모드, 링크개수, UID, GID, 파일 크기, 파일 관련 시간 등)가 담겨 있는데, 내용은 담겨있지 않습니다. 파일의 메타정보라고 생각하시면 됩니다. i-node는 파일의 내용을 가리키는 일종의 포인터를 갖고 있을 뿐이죠. Single indirect, Double indirect, Triple indirect 등이 보이죠? 이게 다 파일에 대한 내용을 가리키는 블록들이며, 마치 C언어에서 포인터, 더블 포인터 등과 같이 내용을 가리키게 됩니다.
16비트의 플래그로 파일의 실행 권한입니다. 소유자의 권한, 소유자 그룹의 권한, 기타 사용자의 권한, 파일 형식, 실행 플래그 등을 나타냅니다.
링크 수
이 아이노드에 대한 참조 수를 나타냅니다.
소유자 아이디
파일의 소유자 아이디를 나타냅니다.
그룹 아이디
파일 소유자의 그룹 아아디를 나타냅니다.
파일 크기
파일의 크기(bytes)를 나타냅니다.
파일 주소
실 데이터가 나오는 파일 주소를 나타냅니다.
마지막 접근
마지막으로 파일에 접근한 시간을 나타냅니다.
마지막 수정
마지막으로 파일을 수정한 시간을 나타냅니다.
아이노드 수정
마지막으로 아이노드를 수정한 시간을 의미합니다.
I-node는 각자 자신들의 고유한 번호를 가지고 있는데, 이 고유한 번호를 i-node 번호라고 합니다. ls 명령어에서 -i 옵션은 i-node번호를 같이 보여줍니다. 그래서 i-node번호와 같이 자세한 출력은 원하면 ls -li 을 입력하면 됩니다. 왼쪽에 나오는 숫자가 바로 i-node 번호입니다.
# ls -il /usr/lib
total 2952
6291630 drwxr-xr-x 105 root root 86016 Jun 8 06:17 aarch64-linux-gnu
6441489 drwxr-xr-x 2 root root 4096 Apr 18 00:48 apg
6291631 drwxr-xr-x 2 root root 4096 Feb 17 17:30 apparmor
6291632 drwxr-xr-x 5 root root 4096 Feb 17 17:30 apt
6442507 drwxr-xr-x 3 root root 12288 Apr 18 00:48 aspell
실제 inode의 내용을 확인해보고 싶다면 stat 명령을 사용해서 확인해보시기 바랍니다. stat명령도 내부적으로 inode에서 정보를 얻는 구현이 있기 때문입니다. 아래는 단순 빈 파일의 정보입니다.
같은 I-node를 가리키느냐, 아니면 데이터 블록이 원본 파일을 가리키느냐에 따라서 하드링크(Hard link)와 심볼릭(Symbolic link)로 나뉘어집니다. 파일에 링크를 걸어주는 명령이 ln 명령어입니다. ln 명령어를 통해서 하드링크와 심볼릭 링크가 무엇인지 확인해봅시다.
하드링크는 파일이 같은 i-node를 가리켜 파일의 내용을 공유하는 링크 방식을 의미합니다. 하드 링크는 같은 i-node를 가리키기 때문에 i-node 번호가 같습니다. ln 명령어로 하드링크를 걸어봅시다. 하드 링크를 거는 방법은 아래와 같은 명령어 형식을 사용하면 됩니다.
ln 원본파일 링크파일
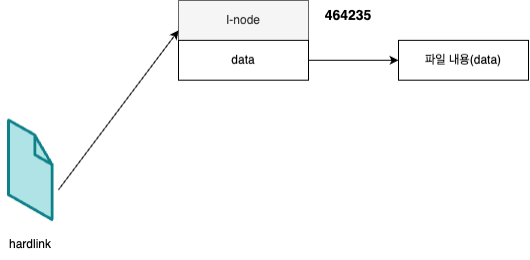
우선 아래와 같이 문자열을 담고 있는 origin이라는 파일을 하나 생성하고, i-node 번호(1열)를 확인하면 464235라는 것을 확인할 수 있네요. 파일을 최초로 만들었을 땐 링크수(3열)가 1이라는 점!
# echo "hard link test" > origin
# ls -il
total 4
464235 -----w--w- 1 root ubuntu 15 Jun 14 01:35 origin
이후 ln 명령어를 통해서 하드링크를 걸어줍니다. I-node와 링크수를 확인해보니, i-node는 464235로 같고 링크수가 2로 하나 증가함을 알 수 있습니다. 그 외의 파일의 권한, 소유자, 시간 모두 정확히 같습니다. 그렇죠?
# ln origin hardlink
# ls -il
total 8
464235 -----w--w- 2 root ubuntu 15 Jun 14 01:35 hardlink
464235 -----w--w- 2 root ubuntu 15 Jun 14 01:35 origin
그렇다면 우리는 이런 그림을 그려볼 수 있습니다. 링크수는 i-node를 가리키는 화살표의 갯수를 의미하며, 두 파일은 i-node를 같이 공유하고 있음을 알 수 있습니다.
2.1 하드링크의 원본 파일 삭제 시
그렇다면 만약 어느 하나의 파일을 삭제하게 된다면 어떻게 될까요? 여기서는 원본의 파일을 삭제해보도록 하겠습니다.
# rm origin
# ls -il
total 4
464235 -----w--w- 1 root ubuntu 15 Jun 14 01:35 hardlink
# cat hardlink
hard link test
결과에서 알 수 있듯이 i-node의 번호는 변하지 않고, 링크의 갯수가 하나 줄었습니다. 내용을 보면 심지어 내용도 보존이 됩니다. 원본 파일을 삭제했는데도 말이죠. 이런 상황입니다.
그래서 파일을 삭제한다는 뜻은 링크를 제거한다는 것과 유사합니다.
3. 심볼릭 링크(Symbolic Link)
심볼릭 링크는 ln 명령어에 -s 옵션을 추가하여 링크를 걸 수 있습니다. 위와 같은 과정으로 테스트를 해보면 하드링크와 다른점을 확인할 수 있습니다.
# echo "symbolic link test" > origin
# ls -il
total 4
464235 -----w--w- 1 root ubuntu 19 Jun 14 01:54 origin
# ln -s origin symlink
# ls -il
total 4
464235 -----w--w- 1 root ubuntu 19 Jun 14 01:54 origin
464240 lrwxrwxrwx 1 root ubuntu 6 Jun 14 01:55 symlink -> origin
하드링크와의 차이점을 정리해보면 이렇습니다.
origin의 i-node 번호(1열)와 symlink 파일의 i-node번호가 다르다.
링크의 갯수(3열)가 변하지 않는다.
다른 기타 정보(권한, 크기, 시간 정보 등)이 다르다.
파일의 유형을 보면 정규 파일('-')이 아니라 링크('l')이다.
이 상태에서 원본 파일과 심볼릭 링크 파일의 관계를 그리면요. 아래와 같습니다.
이 그림이 성립이 된다는 것을 확인시켜드리고자 이 상태에서 원본 파일을 과감하게 지우겠습니다.
# rm origin
# ls -il
total 0
464240 lrwxrwxrwx 1 root ubuntu 6 Jun 14 01:55 symlink -> origin
# cat symlink
cat: symlink: No such file or directory
원본 파일인 origin을 삭제하고 심볼릭 링크를 읽으려해보면 그러한 파일을 찾을 수 없다는 에러 메시지를 볼 수 있습니다. 만약 다시 origin을 생성해보면 어떨까요?
# echo "new origin" > origin
# ls -il
total 4
464235 -----w--w- 1 root ubuntu 11 Jun 14 06:59 origin
464240 lrwxrwxrwx 1 root ubuntu 6 Jun 14 01:55 symlink -> origin
# cat symlink
new origin
이러한 경우에는 다시 symlink로 파일을 읽을 수 있습니다. 다만 그 내용은 원래 이전의 origin의 내용이 아니라 다시 생성한 origin 파일의 내용인 것을 알 수 있습니다. 결국은 심볼릭 링크의 경우에 파일을 가리킨다는 것을 확인할 수 있습니다.
4. ln 명령어 구현
간단한 ln 명령어를 구현해보도록 하겠습니다. 그전에 우리가 알아야할 관현 함수들은 symlink와 linkat 함수입니다.
symlink
#include <unistd.h>
int symlink(const char *target, const char *linkpath);
심볼릭 링크를 거는 시스템 콜입니다. target은 현재 프로세스 위치의 파일 이름입니다. 상대 경로일 수 있습니다. linkpath는 링크 파일의 이름입니다. 이때 이 파일이 존재하면 에러 -1이 발생합니다.
linkat
#include <unistd.h>
int linkat(int olddirfd, const char *oldpath,
int newdirfd, const char *newpath, int flags);
하드 링크, 심볼릭 링크 둘 다 걸 수 있는 시스템 콜입니다. linkat 함수는 조금 까다로울 수 있는데, newpath가 oldpath를 가리키도록 링크를 걸게 됩니다.
olddirfd와 oldpath, newdirfd와 newpath가 한 쌍으로 파일을 나타냅니다. oldpath가 절대 경로일 경우 olddirfd는 무시가 되고, oldpath가 상대 경로일 경우 olddirfd 기준의 상대경로가 됩니다. newdirfd와 newpath와의 관계도 마찬가지입니다. 함수를 호출한 프로세스를 기준으로 상대위치로 만들고 싶다면 fd인자에 AT_FDCWD 상수를 사용해야합니다.
flag는 AT_SYMLINK_FOLLOW를 사용할 수 있습니다. 만약 이 flag를 쓰게 되면 원본 파일이 심볼릭 링크라면 링크를 따라가서 하드 링크를 겁니다. 원본 파일이라니까 헷갈리실거 같은데 ln 명령어에서 첫번째 인수를 말해요. 이 flag를 쓰지 않으면 원본 파일인 심볼릭 링크를 따라가 심볼릭 링크를 겁니다.
ln 원본파일 링크파일
즉, 정리하면
AT_SYMLINK_FOLLOW 를 사용할 경우 : symlink를 계속 따라가서 harlink
AT_SYMLINK_FOLLOW를 사용하지 않은 경우 : symlink를 계속 따라가서 symlink
4.1 소스코드
이제 간단히 구현한 myln.c 코드를 보겠습니다.
//myln.c
#include <unistd.h>
#include <stdbool.h>
#include <stdio.h>
#include <unistd.h>
#include <fcntl.h>
// -s 옵션
bool symbolic = false;
// -L 옵션
bool logical = false;
int main(int argc, char *argv[]){
int c;
char **files_name;
char *src, *dst;
//옵션 파싱
while((c = getopt(argc, argv, "sL")) != -1 ){
switch(c){
case 's':
symbolic = true;
break;
case 'L':
logical = true;
break;
}
}
files_name = argv + optind;
//원본 파일
src = files_name[0];
//링크 파일
dst = files_name[1];
//심볼릭 링크시에 symlink 사용
if(symbolic){
return symlink(src, dst);
}
//심볼릭 링크가 아니면 -L 옵션 여부에 따라 AT_SYMLINK_FOLLOW 플래그 설정
return linkat(AT_FDCWD, src, AT_FDCWD, dst, logical ? AT_SYMLINK_FOLLOW : 0);
}
linkat에 AT_FDCWD를 사용한 것을 보시기 바랍니다. AT_FDCWD는 현재 싱행되는 프로그램의 위치를 기준삼아 src를 찾고, dst링크 파일을 만듭니다. 위 코드는 실제 ln의 코드를 풀어 쓴 코드입니다. 아래는 실제 ln의 소스 코드 일부분입니다.
# gcc myln.c
# echo "this is origin" > origin
# ./a.out -s origin symlink1
# ./a.out origin hardlink1
# ls -il
total 24
464557 -rwxr-xr-x 1 root root 9088 Aug 15 05:59 a.out
464558 -rw-r--r-- 2 root root 15 Aug 15 05:59 hardlink1
464648 -rw-r--r-- 1 root root 1121 Aug 15 05:52 myln.c
464558 -rw-r--r-- 2 root root 15 Aug 15 05:59 origin
464646 lrwxrwxrwx 1 root root 6 Aug 15 05:59 symlink1 -> origin
우선 원본 파일인 origin을 생성하고 심볼릭 링크와 하드링크를 하나씩 걸었습니다. symlink1은 심볼릭 링크로 잘 링크되어있고, hardlink1도 inode를 보니 origin과 같아서 하드링크가 잘 걸려있네요!
-L옵션도 확인해볼까요?
# ./a.out -L symlink1 hardlink2
# ./a.out symlink1 symlink2
# ls -il
total 28
464557 -rwxr-xr-x 1 root root 9088 Aug 15 05:59 a.out
464558 -rw-r--r-- 3 root root 15 Aug 15 05:59 hardlink1
464558 -rw-r--r-- 3 root root 15 Aug 15 05:59 hardlink2
464648 -rw-r--r-- 1 root root 1121 Aug 15 05:52 myln.c
464558 -rw-r--r-- 3 root root 15 Aug 15 05:59 origin
464646 lrwxrwxrwx 2 root root 6 Aug 15 05:59 symlink1 -> origin
464646 lrwxrwxrwx 2 root root 6 Aug 15 05:59 symlink2 -> origin
-L옵션은 linkat 콜 인자 중 flag에 AT_SYMLINK_FOLLOW를 전달한 것과 같습니다. 그러니까 -L 옵션을 줄 경우 원본 파일은 symlink1을 따라가서 최종 원본 파일을 찾고 거기에 하드링크를 걸게 됩니다. -L 옵션을 뺀 경우, 그러니까 AT_SYMLINK_FOLLOW옵션을 주지 않았을 경우 링크를 계속 따라가서 최종 원본 파일에 심볼릭 링크를 걸게 되지요.
여기까지 리눅스의 i-node가 대한 간단한 소개와 link의 방식인 hard link, symbolic link의 개념과 차이점을 확인해보았으며 직접 ln 명령어를 맛보기로 구현해보았습니다.