구초제(Structure)
우리는 같은 자료형을 여러개 쓸 때는 배열이라는 것을 썼었죠. 아주 유용합니다. 배열과 반복문을 통해서 조금 더 쉽게 프로그래밍을 할 수 있었습니다.
하지만 같은 자료형이 아닌, 다른 자료형을 하나로 통합해서 관리해야할때는 어떻게 할까요??
통합적이게 데이터를 묶고 쉽게 접근할 수 있는 기법이 바로 구조체라고 합니다.
만약 구조체가 없이 사람들의 데이터를 관리한다고 칩시다.
char name[MAX_N][30];
int age[MAX_N];
char phone[MAX_N][30];
자료형이 서로 다르니, 서로 같아도 쓰임새가 다르니, 여러개의 변수를 관리할 수 밖에 없습니다. 프로그래밍의 가독성과 효율성을 떨어뜨리게 되는 것이죠.
하지만 구조체는 우리의 작은 소원을 들어줍니다. 하나로 묶는 것이죠.
구조체를 정의하는 방법은 상당히 간단합니다. 이렇게요.
struct User{
char name[30];
int age;
char phone[30];
}
User가 바로 구조체의 이름이며, 그 안의 변수들은 멤버변수라고 합니다.
이렇게 데이터를 묶어서 배열로 정의하게 되면 저 위의 코드를 조금 더 편하게 관리하고 접근할 수 있습니다.
struct User user[MAX_N];
대충 이런 느낌입니다. 쉽죠?
그럼 오늘 포스팅을 이걸로 마치겠습니다.
이제 본격적으로 구조체를 어떻게 사용하는 지 알아보도록 하겠습니다.
구조체 정의는 위에서 본것과 같이 함수밖에서(전역) 구조체 안의 멤버 변수들을 선언해줍니다.
struct 구조체이름{
...
변수
...
};
그리고 함수안에서는 다음과 같이 사용할 수 있습니다.
struct 구조체이름 구조체변수명={ ..., 멤버 변수 값, ...};
이렇게 한꺼번에 구조체에 선언된 변수 순서대로 값을 초기화 할 수도 있고
또는
struct 구조체이름 구조체변수명;
구조체변수명.멤버변수명=변수값
...
하나하나 명시적으로 변수에 값을 할당할 수 있습니다.
변수에 접근하려면 어떻게 할까요??
그것도 역시 간단합니다. 구조체변수에 .(dot)을 찍어서 멤버변수명을 입력해서 접근할 수 있습니다.
구조체변수명.멤버변수명
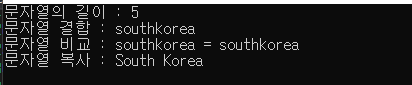
이제까지 설명했던 내용을 코드로 간단하게 사용해보도록 합시다.
#include <stdio.h>
struct User {
char name[30];
int age;
char phone[30];
};
int main() {
struct User user = { "REAKWON",2018,"010-????-????" };
printf("이름:%s\n", user.name);
printf("나이:%d\n", user.age);
printf("전화번호:%s\n", user.phone);
}
원하는 대로 결과가 나오죠?
그런데 우리는 구조체를 typedef로 조금 더 간단하게 선언할 수 있습니다.
typedef은 자료형을 조금 더 편하게 관리하기 위해서 쓰입니다.
typedef 원래의 자료형 내가 정의한 자료형;
이렇게 하면 변수를 원하는 대로 정의해줄 수 있습니다.아래와 같이요.
typedef unsigned int u_int;u_int val=30;
typedef struct 구조체명{
구조체 정의부
} 정의할 구조체명;
그러면 선언에서 struct를 빼고
정의한 구조체명 구조체변수
이렇게 조금 더 편하게 쓸 수도 있습니다.
아래의 코드는 바로 위의 코드를 typedef를 사용해서 바꾼 코드랍니다.
#include <stdio.h>
typedef struct User {
char name[30];
int age;
char phone[30];
} _User;
int main() {
_User user = { "REAKWON",2018,"010-????-????" };
printf("이름:%s\n", user.name);
printf("나이:%d\n", user.age);
printf("전화번호:%s\n", user.phone);
}
구조체 크기
구조체의 크기를 한번 알아보도록 할까요?
아까와 같은 구조체를 한번 변경해서 보도록하겠습니다.
struct User {
char name[10];
int age;
char phone[10];
}char자료형은 1바이트이고 10개의 배열을 가졌으니, 10바이트
int자료형은 4바이트입니다.
또 char배열 10개로 10바이트해서 구조체의 크기는 총 24바이트겠네요.
코드로 확인해보도록 하지요.
#include <stdio.h>
struct User {
char name[10];
int age;
char phone[10];
};
int main() {
printf("User 구조체 사이즈:%d\n",sizeof(struct User));
}

??????
제가 틀렸군요. 28바이트가 나오네요.
왜일까요??
구조체의 사이즈는 그 구조체 멤버중에서 가장 큰 자료형에 따라 결정이 됩니다. 가장 큰 자료형은 int로 4바이트가 되죠? 그래서 4의 배수로 크기가 결정됩니다.
이해를 돕기 위해 그림을 첨부합니다.

사각형 한 칸의 크기는 1바이트를 나타냅니다. name과 phone은 10바이트를 차지할 것 같지만, char형은 1바이트이고, int형인 age는 4바이트니까 큰 자료형에 의해서 4의 배수로 메모리가 할당이 됩니다.
name과 같이 12바이트를 맞추기 위해 여분의 바이트를 붙여주는 것을 우리는 패딩(padding)이라고 합니다.
아~ 그래서 28바이트가 나오는 구나.
그렇다면 메모리가 낭비될텐데 조금 더 아낄수 있는 방법은 없을까요?
우리는 변수명을 단지 바꾸어 주어 이런 메모리 낭비를 막을 수 있습니다. 이렇게요.
#include <stdio.h>
struct User {
char name[10];
char phone[10];
int age;
};
int main() {
printf("User 구조체 사이즈:%d\n",sizeof(struct User));
}
이때의 메모리를 보면 아래의 그림과 같습니다.

이렇게 4바이트를 아낄 수 있지요.
왜 이렇게 메모리를 큰 자료형에 맞출까요?? 네트워크 통신에서 관련이 있습니다. 우리는 아직 그 크기에 그렇게 신경써도 되지 않아도 됩니다.
이렇게 구조체가 무엇인지, 어떻게 정의하는지 알아보았는데요. 다음 시간에는 구조체에 대해서 조금 더 세세하게 알아보고 구조체 포인터에 대해서도 이야기해보도록 하겠습니다.
'언어 > C언어' 카테고리의 다른 글
| [C언어] 파일 입출력 - 텍스트와 이진 파일 열기, 읽기 ,쓰기, 닫기 (0) | 2018.10.14 |
|---|---|
| [C언어] C언어 그림으로 쉽게 보는 구조체와 구조체 포인터, 코드 예제 (1) | 2018.10.01 |
| [C언어] 동적 메모리 할당의 세가지 방법 malloc, calloc, realloc (0) | 2018.09.28 |
| [C언어] void 포인터(void pointer)개념과 자유로운 형변환, malloc 반환형 (2) | 2018.09.27 |
| [C언어] 함수포인터 기본 개념과 쓰는 이유 (1) | 2018.09.27 |

REAKWON
와나진짜