프로그램에서 시간은 거의 필수로 다루어질 만큼 중요한 요소입니다. 그래서 우리는 시간을 잘 다루어야 할 필요가 있습니다. 그래서 이번에는 C언어에서 시간과 관련된 함수 몇가지를 살표보도록 하지요. 지금부터 다룰 함수는 모두 시간과 관련된 함수이므로 time.h 헤더파일을 포함시켜야한다는 것을 잊지 마세요.
time
가장 기본적인 시간 관련 함수입니다. 함수의 원형은 다음과 같죠.
#include <time.h>
time_t time(time_t *timeptr);
이 함수는 1970년 1월 1일 0시 (UTC)부터 인자값(timeptr)까지 흐른 시간을 반환합니다. 그 단위가 초단위지요. 이 함수의 사용방법은 주로 2가지 입니다.
timeptr이라는 매개변수에 인자를 전달하여 현재까지 흐른 시간을 초단위로 구하거나, time함수에 NULL을 전달하여 반환값을 받거나 입니다.
그래서 현재시간까지 구한다면 time(NULL)을 호출해서 반환값을 받으면 되는 것이죠. 아래의 예처럼요.
time_t t; t = time(NULL); printf("%ld\n", t);
그 결과는 아래처럼 큰 정수를 반환하게 되지요. 1970년 1월 1일 0시(UTC)부터 지금까지 초단위의 시간을 구하기 때문이지요.
1548588718
localtime
이 함수는 지역시간을 구해냅니다. 반환하는 형식은 구조체인데 tm이라는 구조체입니다. 다음 함수의 원형처럼 말이죠.
우리는 위의 time함수에서 UTC기준으로 흐른 시간을 초단위로 구했지요. 초단위로 구하니 보기도 어렵고 지금이 몇월인지 몇년도인지 구분하기가 어렵습니다. 그래서 이것을 사람이 잘 알아보게끔 구조체로 변환할 수 있는 함수가 바로 localtime함수입니다.
우리는 반환값인 tm구조체를 다는 아니어도 필요한 몇가지 멤버는 알아야할 필요가 있습니다.
struct tm {
int tm_sec; //초
int tm_min; //분
int tm_hour; //시
int tm_mday; //일
int tm_mon; //월(0부터 시작)
int tm_year; //1900년부터 흐른 년
int tm_wday; //요일(0부터 일요일)
int tm_yday; //현재 년부터 흐른 일수
int tm_isdst;
};
필드명은 꽤 직관적입니다. 이 필드명만 보아도 무엇을 의미하는 것인지 잘 알것이라고 생각합니다.
자세한 것은 코드로 살펴보도록 합시다.
#include <stdio.h>
#include <time.h>
int main() {
time_t current;
time(¤t);
struct tm *t = localtime(¤t);
printf("%d년 %d월 %d일 ",
1900 + t->tm_year, t->tm_mon + 1, t->tm_mday);
switch (t->tm_wday) {
case 0:printf("일요일 ");
break;
case 1:printf("월요일 ");
break;
case 2:printf("화요일 ");
break;
case 3:printf("수요일 ");
break;
case 4:printf("목요일 ");
break;
case 5:printf("금요일 ");
break;
case 6:printf("토요일 ");
break;
}
printf("%d:%d:%d\n", t->tm_hour, t->tm_min, t->tm_sec);
printf("1년 365일 중 %d일째\n", t->tm_yday + 1);
}
그 결과는 다음과 같습니다.
2019년 1월 27일 일요일 20:55:9
1년 365일 중 27일째
각각 년, 월, 일 , 시, 분, 초, 요일을 각각 구할때, 또는 날짜계산, 시간계산을 할때 편리하겠군요.
컴퓨터가 사용하는 모든 데이터들은 전부 1과 0으로 이루어진 비트열이라는 것을 다들 잘 알겁니다.
C언어에서도 역시 그렇습니다. 우리는 정수형 변수 a에 16이라는 데이터를 집어넣는 것은 사실 코딩할때만 그렇습니다. 하지만 실행이 될때는 이진수로 메모리에 저장이 되어있죠.
만약
int a=16
이라고 정수를 메모리에 넣어준다면 이렇게 메모리에 잡히게 됩니다.
int는 4바이트의 메모리를 갖고 있으므로
0000 0000 0000 0000 0000 0000 0001 0000
이렇게 저장이 되지요.
우리는 이러한 비트로 연산을 수행할 수 있습니다. 오늘은 이런 비트 연산에 대해서 알아보도록 하겠습니다.
NOT ( ~ )
NOT연산자는 비트열을 반전시키는 연산자입니다. 직관적으로 이해하기도 쉽습니다.
만약 비트가 1이면 0으로 반전하고, 0이면 1로 바꾸기만 하면 되니까요. 연산자 기호는 ~를 씁니다.
그래서 만약
~1000 0110 는 0111 1001로 바뀌게 됩니다.
OR( | )
OR 연산자는 | 입니다. 엔터 위쪽 \가 보이시나요? 이것을 쉬프트기로 눌러 입력한게 바로 OR연산자 | 입니다. A OR B는 A 또는 B가 1이라면 답은 1이 되는 겁니다.
0 | 0 = 0
0 | 1 = 1
1 | 0 = 1
1 | 1 = 1
두 비트가 모두 0일때 0이라는 것을 알 수 있네요.
다음의 계산 예를 봅시다.
0111 1001
OR 1000 1010
---------------------
1111 1011
AND( & )
AND 연산자는 두 비트열 모두 1일때 1이 됩니다.
0 & 0 = 0
0 & 1 = 0
1 & 0 = 0
1 & 1 = 1
둘 다 1일때만 1인것을 알 수 있습니다.
다음의 예를 보고 AND연산에 대해서 보도록 합시다.
0001 1001
AND 0111 1000
----------------------
0001 1000
OR연산과 AND 연산은 정말 쉽습니다.
XOR( ^ )
XOR 연산자는 두 비트열 중 1이 하나만 있을때 답이 1이 됩니다. 또는 1이 홀수개 일때 답이 1이 된다고 기억하면 됩니다.
0 ^ 0 = 0
0 ^ 1 = 1
1 ^ 0 = 1
1 ^ 1 = 0
1이 홀수개일때만 1이 됩니다.
1001 1010
XOR 0110 1111
---------------------
1111 0101
SHIFT( <<, >>)
쉬프트 연산은 비트를 옮기는 연산을 수행합니다. 옮기는 방향에 따라 두 종류가 있습니다. 바로 left shift와 right shift가 그것이죠.
비트를 왼쪽으로 옮기려면 << 연산을 사용하고, 오른쪽으로 옮기려면 >>연산을 사용합니다.
옮길 기준이 되는 비트열은 항상 연산자의 왼쪽, 얼만큼 옮길 건지를 결정하는 건 연산자의 오른쪽에 위치합니다.
만약 Left Shift 연산으로 왼쪽으로 비트열을 옮긴다면 가장 오른쪽에서부터 옮긴 비트열 길이까지 0으로 채워집니다.
하지만 Right Shift 연산으로 비트열을 오른쪽으로 옮기면 가장 상위비트(MSB:Most Significant Bit 라고 합니다.)를 왼쪽에서부터 채웁니다.
아래 예를 보면서 이해합시다.
0011 0110 << 3 = 1011 0000
왼쪽으로 3비트를 이동시키니 001은 삭제되었습니다. 그리고 10110이라는 비트열이 왼쪽으로 3비트 이동이 되지요. 그렇다면 자리가 3개가 남겠군요. 그건0으로 채웁니다. 이것을 패딩(padding)이라고 하지요.
0011 1100 >> 3 = 0000 0111
이제 오른쪽 비트이동입니다. 우선 이 비트를 오른쪽으로 3비트를 옮기니 100이 삭제가 됩니다. 그후 나머지 4비트는 오른쪽으로 3비트를 이동하면 왼쪽에 3비트를 추가로 채워야하지요. 옮기기전 가장 상위비트(MSB)는 빨간색으로 표시된 0입니다. 그러니 오른쪽으로 이동할때는 이 MSB를 가지고 왼쪽비트를 채우니 000으로 채워지는 겁니다.
1001 1011 >> 4 = 1111 1001
자, 이제 MSB는1입니다. 이 비트를 오른쪽으로 4비트를 이동하니 1001은 없어지겠죠? 그후 나머지 4비트를 오른쪽으로 이동하고 비워진 4비트는 MSB로 채우니 1로 채워지는 것입니다.
아! 여기서 2의 보수법을 모르시는 분을 위해서 잠시 간략하게 설명하겠습니다.
자료형에는 음수를 나타낼 수 있는 signed 타입와 unsigned 타입이 있습니다. 우리가 int, char와 같이 그냥 사용하게 된다면 default로 signed 자료형입니다. 하지만 음수를 표현할 필요가 없다면 unsigned라는 키워드를 붙여 unsigned int와 같이 표현합니다.
이제 음수를 나타낼 수 있는 signed 자료형에 대해서 음수를 표현하는 방법을 설명하겠습니다.
signed자료형에서 컴퓨터는 MSB에 따라 음수인지 양수인지 구별하는데요.
0이면 양수, 1이면 음수를 나타냅니다.
만약 위의 예에서 0011 1100은 MSB가 0이므로 양수입니다.
그러니 정수로 표현하면 MSB를 제외하고 32+16+8+4로 70이 됩니다.
하지만 위의 예처럼 1111 1001은 MSB가 1이므로 음수입니다. 이때 2의 보수를 사용하는데요. 방법은 이렇습니다.
우리는 난수를 사용하고 싶을 때가 있습니다. 하지만 이런 기능을 만드는 것은 좀처럼 쉬운 일은 아니지요. 귀찮기도 하구요.
C언어에서는 그러한 프로그래머를 위해서 난수생성함수를 제공하고 있습니다. 바로 rand라는 함수이지요. 외우기도 쉽네요. rand(om)으로 기억하면 되니까요.
rand
rand함수를 사용하기 위해서는 stdlib.h 헤더파일을 include해야합니다. rand함수는 0부터 RAND_MAX까지 범위까지 난수를 생성합니다. 함수 원형을 같이보시죠.
#include <stdlib.h>
int rand(void);
보시는 바와 같이 rand함수는 int형을 반환하게 됩니다. 아하, 그러면 rand함수를 쓰게 되면 랜덤인 정수형이 나오겠구나. 알 수 있죠?
이제 이 함수를 이용해서 1부터 100까지 정수 중 10개의 수를 랜덤하게 뽑아내는 프로그램을 짜보도록 하지요.
#include <stdio.h>
#include <stdlib.h>
int main() {
int i;
for (i = 1; i <= 10; i++)
printf("%d ", (rand() % 100) + 1);
printf("\n");
}
이제 결과를 보도록 할까요??
42 68 35 1 70 25 79 59 63 65
오 랜덤하게 실행이 되는 군요. 100가지의 숫자 중 랜덤한 10개의 숫자를 뽑아냈습니다.
저는 신기해서 한번 더 실행해보겠습니다.
42 68 35 1 70 25 79 59 63 65
????
프로그램을 실행할때마다 바뀌지 않는데요? 우리는 이런 랜덤한 값을 원한게 아닙니다. 우리는 프로그램을 실행할때마다 랜덤하게 10개의 수를 출력하는 프로그램을 원하는 건데요. 지금 출력된 것은 단지 일정한 숫자 배열을 출력한 것과 같다고 느껴집니다.
왜 C언어는 우리에게 이런 사기를 치는 것일까요?
srand
사실 rand함수는 srand함수에 의존적입니다. srand의 s는 seed라는 뜻으로 이 seed값에 따라 rand의 값이 바뀌게 됩니다. srand는 rand함수와 같이 stdlib.h 헤더파일에 존재합니다.
만일 이 함수를 호출하지 않고 rand함수를 호출한다면 srand(1)을 호출하고 rand함수를 호출한 효과와 같습니다.
함수의 원형은 다음과 같은데요.
#include <stdlib.h>
void srand(unsigned int seed);
양의 정수만 seed로 사용할 수 있습니다. 그렇다면 우리가 srand의 seed값을 2로 주면 위의 결과와 다를까요?
위의 코드에서 for로프 위에 srand(2)를 추가해보세요.
46 17 99 96 85 51 91 32 6 17
아까와는 다른 결과를 볼 수 있군요. srand에서 seed를 바꿔서 실행시켜보세요. 나오는 값이 계속 달라짐을 알 수 있습니다. seed값만 바꿔주면 그 seed값에 따라 값을 랜덤하게 뽑아 올 수 있군요.
하지만 이것 마저도 아직 우리를 만족시킬 수가 없습니다. 이렇게 되면 프로그램을 실행시킬때마다 seed값을 바꾸고 다시 컴파일하는 과정을 거쳐야하기 때문이죠. 우리는 이런 허접한 코드는 쓰지 말도록 합시다.
우리는 이것보다 더 잘할 수 있습니다. 잘 할 수 있고 말고요. 한번 생각해봅시다. 프로그램 실행시 계속 바뀌는 값은 뭐가 있을까요?
주소값? (사실 제가 랜덤함수를 구현한다고 생각해볼때 고려해봤던 것 중 하나입니다.)
바로 시간입니다. 시간은 지금 이 순간에도 항상 바뀌고 있지요. 그래서 소개할 다음 함수가 time이라는 함수입니다.
time
time함수는 이름 그대로 시간에 대한 정보를 얻어오는 함수랍니다. 우선 time함수를 사용하기 위해서는 time.h라는 헤더파일을 include해야하지요.
함수의 원형을 한번 살펴볼까요?
#include <time.h>
time_t time(time_t *tloc);
이 함수는 1970년 1월 1일 0시 (UTC)부터 현재까지 흐른 시간을 반환합니다. 반환은 하지만 그 시간이 초단위입니다. 만일 우리가 현재까지 흐른 시간을 구하려면 만약 timeptr에 NULL을 전달하고 반환값을 받거나, 아니면 timeptr에 인자를 전달해서 현재까지 흐른 시간을 초단위로 받을 수 있습니다.
이제 아주 기본적인 사용법을 알게 됐으니 코드로 구현하도록 해봅시다.
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
int main() {
int i;
srand(time(NULL));
for (i = 1; i <= 10; i++)
printf("%d ", (rand() % 100) + 1);
printf("\n");
}
단지 srand의 인자를 time(NULL)로 바꾼거 밖에 없습니다. time(NULL)을 호출하면 1970/1/1 0시부터 현재(프로그램 실행 시)까지 흐른 시간을 return한다고 했지요? 그러니 이 프로그램을 실행할때마다 srand의 seed값이 바뀌게 되는 겁니다.
이제 확인을 해봅시다.
첫번째 실행
79 61 20 69 3 67 82 24 63 35
두번째 실행
44 53 56 15 86 98 95 14 15 46
어떻습니까? 이제 이 프로그램을 여러번 실행해도 값이 다르게 나온다는 것을 알 수 있습니다.
그렇다면 우리가 랜덤한 값을 얻고자 할때는 rand, srand, time함수를 전부 다 써야하나요?
Visual Studio에서 우리는 실행할때 F5(또는 Ctrl+F5)를 눌러서 우리가 만든 소스코드를 실행시켜봤죠? 우리는 너무 쉽게 프로그램을 실행시킨다고 생각할 수 있지만 의외로 몇몇 단계를 거치고 있습니다.
이번 시간에는 컴퓨터 실행파일이 어떻게 생겨나는지에 대해서 알아보도록 합시다.
우리가 실행파일을 생성하는데까지는 아래와 같은 과정을 거치게 됩니다. 어? program.c와 program.exe는 알겠는데 나머지 파일들은 무엇일까요?
이 파일들의 정체를 알아내기 위해서 잠시 리눅스를 사용하도록 하겠습니다. 여러분들은 어떤 파일에 어떤 내용들이 기록되는지에 대해서 눈여겨 보면 될 것 같네요.
다음의 소스코드가 어떻게 실행파일로 변하는지 알아보지요.
#include <stdio.h>
#define A 10
#define B 20
int main(){
int a=A;
int b=B;
int c=a+b;
printf("%d + %d = %d\n",a,b,c);
}
전처리기(Preprocessor)
전처리기 구문(#으로 시작하는 구문)을 처리하는 것이 바로 전처리기라고 하는데요. 일반적으로 #으로 시작하는 부분을 거의 항상 사용합니다. 그것이 언제냐면 바로 #include지요. 너무나도 소중한 printf를 사용하기 위해서는 항상 #include <stdio.h>를 항상 명시해주어야 하죠.
#include를 통해서 stdio.h의 내용이 그대로 들어오게 됩니다!
또한 위의 코드에서 우리는 #define A 10 과 같은 줄을 볼 수 있는데요. 여기서 전처리기는 A라는 부분을 단순히 10으로 치환합니다.
자. 그렇다면 전처리 과정을 끝낸 program.i는 어떻게 변할까요?
gcc -E program.c -o program.i
위의 명령어로 program.i의 내용을 살펴봅시다.
program.i
# 1 "program.c"
# 1 "<built-in>"
# 1 "<command-line>"
# 1 "/usr/include/stdc-predef.h" 1 3 4
# 1 "<command-line>" 2
# 1 "program.c"
....
extern int printf (const char *__restrict __format, ...);
...
int main(){
int a=10;
int b=20;
int c=a+b;
printf("%d + %d = %d\n",a,b,c);
}
보세요. stdio.h의 내용이 main위의 그대로 들어오지요? 또한 #define A 10과 같은 내용은 없어지고 A가 10으로 치환된것을 알 수 있습니다.
전처리기는 너무나도 단순한 역할을 하는 군요.
중요한것은 전처리기가 컴파일 단계 맨 처음 단계라는 것을 기억하셔야합니다. 그래야지 전처리를 통한 조건부 컴파일을 이해하게 됩니다.
컴파일러(Compiler)
이제 전처리기를 거쳤으니 컴파일러로 컴파일해줍니다. 컴파일러는 고수준언어를 저수준언어로 나타내는 역할을 수행합니다. 저수준언어라는 것은 기계어와 가장 가까운 언어입니다.
이제 program.i로부터 어떻게 program.s가 생겨나는지 보도록 합시다.
gcc -S program.i -o program.s
program.s
.file "program.c"
.section .rodata
.LC0:
.string "%d + %d = %d\n"
.text
.globl main
.type main, @function
main:
.LFB0:
.cfi_startproc
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
movq %rsp, %rbp
.cfi_def_cfa_register 6
subq $16, %rsp
movl $10, -4(%rbp)
movl $20, -8(%rbp)
movl -8(%rbp), %eax
movl -4(%rbp), %edx
addl %edx, %eax
movl %eax, -12(%rbp)
movl -12(%rbp), %ecx
movl -8(%rbp), %edx
movl -4(%rbp), %eax
movl %eax, %esi
movl $.LC0, %edi
movl $0, %eax
call printf
leave
.cfi_def_cfa 7, 8
ret
.cfi_endproc
.LFE0:
.size main, .-main
.ident "GCC: (GNU) 4.8.5 20150623 (Red Hat 4.8.5-16)"
.section .note.GNU-stack,"",@progbits
뭐 저도 잘 모르겠습니다. 그냥 저수준언어로 변한것 밖에는 모르겠네요.
근데 "%d + %d = %d\n" 는 우리가 printf에 썼던 문자열이라는 것을 알 수 있네요.
이것이 컴파일러가 하는 역할입니다. 이제 파일을 오브젝트파일로 변환하는 어셈블러를 보도록 합니다.
어셈블러(Assembler)
이제 완전히 기계어로 바꾸어 주는 역할을 합니다. 우리가 읽을 수 없거든요. 다음의 명령어를 통해서 기계어 파일을 만들고 확인해보도록 하죠.
함수를 중학생때부터 배우죠? 그렇기 때문에 저는 중학교 시절 수학을 포기했습니다. 여러분들은 저보다 뛰어나시니 그렇지는 않았겠죠?
C언어에서 함수는 아주 필수적이라고 할 수 있습니다. 함수에 대해서 간단히 말씀을 드리면 반복되는 코드를 하나로 묶어 필요할때 가져다가 쓴다는 것입니다.
다음의 코드는 어떻게 생각하시나요?
단순히 세 입력의 펙토리얼(!)을 구하여 곱하는 프로그램이지요.
#include <stdio.h>
int main() {
int fact_a = 1, fact_b = 1, fact_c = 1;
int a, b, c;
int i;
scanf("%d %d %d", &a, &b, &c);
for (i = 1; i <= a; i++)
fact_a*=i;
for (i = 1; i <= b; i++)
fact_b *= i;
for (i = 1; i <= c; i++)
fact_c *= i;
printf("%d! * %d! * %d!= %d\n", a, b, c, fact_a*fact_b*fact_c);
return 0;
}
프로그램이 잘 동작하는지 실행해보세요!
잘 돌아가지요? 문제 없습니다.
하지만 저는 조금 불만인데요. 펙토리얼을 세번 불러오는데, 세번 다 for루프를 돌려야하기 때문에 손가락이 아픈게 그 이유인데요.
만약 10개의 입력으로 들어오고 10개의 펙토리얼의 곱을 구하게 되면 위의 코드에서 for루프를 7개 더 추가해야한다는 것이 매우 불만이지요.
우리가 팩토리얼의 기능을 하는 하나의 코드를 두고 그 코드를 원할때 마다 불러온다면 어떨까요? 그런 역할을 하는 것이 바로 함수입니다.
함수 구현 방식
함수는 어떻게 생겨먹었을까요? 꽤나 간단하게 이해할 수 있을겁니다.
함수의 형태는 이렇습니다.
반환형 함수이름(매개변수1, 매개변수2, ... ){
//몸체
//return 반환값
}
o반환형 : 반환되는 값의 자료형을 의미합니다. 함수에서는 반환되는 값이 없을 수 있는데요. 그 경우 void를 사용합니다. 만약 반환값이 있다면 return에서 값을 반환시켜 주면 됩니다. 그러니 반환값의 자료형과 반환형이 일치해야됩니다.
o 함수이름 : 함수를 불러올때 사용되는 이름입니다. 여러분이 지어주기 나름인데, 이 이름을 보고 사용하는 사람이 "아~ 이런 기능을 하는 함수겠구나!" 라고 알 수 있도록 잘 지어주어야 합니다.
o 매개변수 : 함수에 대한 input이라고 생각하면 됩니다. 이 매개변수를 토대로 함수의 반환값이 달라질 수 있습니다.
기본적인 매개변수의 동작은 전달받은 인자의 값을 복사하는 것입니다. (단, 포인터와 같은 매개변수는 값의 복사가 아닌 참조를 하게 됩니다.)
o 몸체 : 함수가 어떻게 기능을 할지 로직을 구현하는 부분입니다.
o return : 반환값을 반환하는 명령입니다. return은 제어문으로 여러개 올 수 있습니다. 단, return은 한번만 진행하므로 만약 if 조건에서 return 문을 썼는데, if 조건에 걸리게 된다면 이 후의 코드를 실행시키지 않고 반환합니다.
혹은 반환형이 void이지만 그 함수를 어떤 조건에서 끝내고 싶다면 반환값없이 그냥 return을 사용해주면 그 즉시 함수를 끝냅니다.
우리는 위의 허접한 코드를 factorial이라는 함수를 만들어 조금 더 간편하게 바꿔볼 생각입니다.
위의 형식 그대로 사용해서 factorial을 구현한다면 이렇게 생겼겠죠?
int factorial(int n) {
int ret = 1;
int i;
for (i = 1; i <= n; i++)
ret *= i;
return ret;
}
반환형태는 int형이면서 매개변수는 정수형 n입니다. 비교해보세요. 반환형과 반환값(ret)의 자료형이 일치하는 것을 알 수 있죠?
그 후 메인에서는 이 함수를 호출해서 쓰기만 하면 된답니다.
#include <stdio.h>
int factorial(int n) {
int ret = 1;
int i;
for (i = 1; i <= n; i++)
ret *= i;
return ret;
}
int main() {
int fact_a = 1, fact_b = 1, fact_c = 1;
int a, b, c;
int i;
scanf("%d %d %d", &a, &b, &c);
fact_a = factorial(a);
fact_b = factorial(b);
fact_c = factorial(c);
printf("%d! * %d! * %d!= %d\n", a, b, c, fact_a*fact_b*fact_c);
return 0;
}
어때요? 메인이 훨씬 간결해졌음을 알 수 있습니다.
호출 과정은 다음과 같습니다.
메인 함수를 실행하다가 factorial함수를 만났습니다. 그러면 factorial 함수를 실행시키고 함수가 끝나면 다시 메인함수로 돌아와서 그 전에 실행했던 것을 계속 진행하게 됩니다.
fact_a는 factorial 함수의 반환값이 저장됩니다. 나머지 fact_b, fact_c도 역시 마찬가지구요.
만약 10개의 입력이 주어진다하더라도 factorial만 10번 호출하면 되지요.
(아 물론 이 경우에는 배열과 반복문을 써야하겠지만)
함수 선언
근데 꼭 위에서만 함수를 정의하고 몸체를 구현해야할까요? 그럴필요는 없습니다.
함수를 메인 아래에서 정의할 수도 있습니다.
하지만 꼭 위에서 함수 선언을 해주어야만 합니다. 왜 그러냐구요?
C언어는 절차지향언어이기 때문에 위에서 아래로 실행하기 때문이지요. 그래서 함수가 밑에 정의되어있는데 메인함수에서 그 함수를 호출한다고 하면 컴파일러는 그 함수를 본적이 없으니까 컴파일 에러를 토하게 됩니다.
위의 코드를 함수의 선언 방식으로 코딩해보도록 하면 다음과 같이 간단하게 바뀝니다.
#include <stdio.h>
int factorial(int); //함수선언
int main() {
int fact_a = 1, fact_b = 1, fact_c = 1;
int a, b, c;
int i;
scanf("%d %d %d", &a, &b, &c);
fact_a = factorial(a);
fact_b = factorial(b);
fact_c = factorial(c);
printf("%d! * %d! * %d!= %d\n", a, b, c, fact_a*fact_b*fact_c);
return 0;
}
int factorial(int n) {
int ret = 1;
int i;
for (i = 1; i <= n; i++)
ret *= i;
return ret;
}
함수에 밑에 있군요. 메인함수 위의 선언이 있죠?
선언에서는 매개변수의 자료형만 적어주어도 상관없습니다.
재귀함수
함수에서 자신의 함수를 불러오는 것을 바로 재귀함수라고 합니다. factorial함수는 재귀함수로도 구현할 수 있습니다.
int factorial(int n) {
if (n <= 1) return 1;
return n*factorial(n - 1);
}
factorial함수에서 factorial함수를 호출하는 것을 볼 수 있지요? 매개변수 n과 다음 factorial(n-1)의 반환값을 곱하는 과정을 반복하고 있습니다. factorial의 매개변수 n은 하나씩 줄어들어 결국에는 1 이하가 될겁니다. 그때 1을 반환하지요.
결국 n * (n-1) * (n-2) * ... * 1이 되어 n!을 구현하는 함수죠.
그림으로 보면 더 이해가 쉽게 될겁니다.
3!을 구하는 과정을 보여줍니다. factorial(3)은 factorial(2)를 호출하고 factorial(2)는 factorial(1)을 호출하는 과정을 보여주고 있습니다.
이때 factorial(1)은 if조건문에 걸려 1을 반환하여 더이상 자신을 호출하지 않습니다.
*** 이를 기저 사례라고 합니다.
재귀함수는 시스템의 스택을 사용하고 계속 사용할 경우 stack overflow가 발생할 수 있으므로 되도록이면 반복문을 사용하는 것이 좋습니다.
포인터라는 것은 조금 알겠는데 포인터배열은 무엇일까요... 포인터도 힘들게 배우는데 말이죠. 정말 산넘어 산입니다.
포인터배열이란 포인터를 원소로 갖는 배열을 의미합니다. 포인터 각각을 배열로 표현한 것이지요.
느낌이 오시나요?
코드와 그림으로 알아보도록 합시다.
#include <stdio.h>
int main() {
int a = 10;
int b = 20;
int c = 30;
int *pArr[3] = { &a,&b,&c };
printf("%d\n", *pArr[0]);
printf("%d\n", *pArr[1]);
printf("%d\n", *pArr[2]);
}
여기, 포인터배열을 간단하게 알아볼 수 있는 코드입니다. pArr은 평소에 보던 배열과는 다르게 앞에 *(pointer)를 볼 수 있지요?
연산자 우선순위에 의하면 배열첨자([])가 포인터(*)연산보다 먼저입니다. 그렇기 때문에 배열 3개가 있고, 그 배열의 원소는 포인터라는 의미가 됩니다.
따라서 배열의 원소인 pArr[0]은 a의 주소를 갖고있고, pArr[1]은 b의 주소를 갖고 있고, pArr[2]는 c의 주소를 갖고 있습니다.
이 코드의 상황을 그림으로 나타냈습니다.
만약 pArr[0]을 찍어보면 a의 주소가 나오게 됩니다. a의 값에 접근하고 싶다면 포인터 연산을 해주면 됩니다. 바로 *pArr[0], 이렇게요.
그렇게 포인터 원소를 배열로 나열했기 때문에 포인터배열이라 부릅니다.
포인터배열로 배열 가리키기
포인터가 배열의 시작주소를 가리킬 수 있다는 것은 이제 잘 알겁니다. 아닌가? 그렇다면 어떤 배열들을 포인터 배열로 가리킬 수도 있다는 느낌이 오시나요?
코드를 통해 느껴봅시다.
#include <stdio.h>
int main() {
int i, j;
int a[5] = { 1,2,3,4,5 };
int b[6] = { 10,20,30,40,50,60 };
int c[7] = { 100,200,300,400,500,600,700 };
int *pArr[3] = { a,b,c };
int sub_len[3] =
{ sizeof(a) / sizeof(int), sizeof(b) / sizeof(int), sizeof(c) / sizeof(int) };
int len = sizeof(pArr) / sizeof(int*);
for (i = 0; i < len; i++) {
for (int j = 0; j < sub_len[i]; j++)
printf("%d ", pArr[i][j]);
printf("\n");
}
}
a,b,c 배열의 길이는 전부 다릅니다. 하지만 문제없지요. 왜냐면 포인터는 배열의 시작주소만 알면 되기 때문입니다.
각각의 포인터들(pArr[0], pArr[1], pArr[2])은 배열의 시작주소 a, b, c를 가리키고 있습니다.
포인터 역시 배열처럼 첨자를 쓸수도 있다는 것을 다들 아실겁니다.
배열포인터
배열포인터는 무엇일까요? 아까 포인터배열은 포인터를 배열로 나열한 것이라고 설명했으니, 배열포인터는 배열을 가리키는 포인터가 아닐까요?
배열포인터는 다음과 같이 정의합니다.
int (*pArr)[3]
앞서 본 포인터배열과는 다르게 괄호가 추가 되었죠. 이 한 끗 차이에 의미가 변하게 됩니다. 우선 포인터이긴한데, 길이 3을 갖는 int형 배열만을 가리킬 수 있다는 점입니다. 우선 다음 기본적인 코드를 봅시다. 우리가 아는 내용입니다.
#include <stdio.h>
int main() {
int i = 0;
int arr[5] = { 1,2,3,4,5 };
int *pArr = arr;
for (i = 0; i < sizeof(arr)/sizeof(int); i++)
printf("%d ", pArr[i]);
printf("\n");
}
r
pArr은 일차원배열 arr의 시작주소를 가리키고 있다는 내용입니다. 그래서 배열처럼 인덱싱을 통하여 각 원소를 출력하고 있지요. arr의 길이 5는 신경쓰지 않습니다. 단지 가리키기만 하고 있습니다.
이제 위의 정의를 다시 봅시다.
int arr[행][열] ={ {...}, {...}, {...}};
int (*pArr)[열]= arr;
(*pArr)은 arr의 가장 높은 차원의 길이 3(행)은 신경쓰지 않습니다. 단지 그 시작주소만 가리키기만 하면 되거든요. 하지만 그 보다 낮은 차원의 길이4(열)는 알아야만 합니다. 그래야만 다음 행을 구해낼 수 있기 때문이죠.
어떻게??
pArr[0]은 4개의 int배열을 가리키고 있는 포인터입니다. 따라서 sizeof(pArr[0])을 찍어보면 그 길이가 16이라는 것을 알 수 있습니다. 그래서 주소를 계산할때 지금 행의 주소에 16을 더해야 다음 행을 구할 수 있습니다. 위 코드에서는 1차원 배열이고 각 원소의 길이는 단순히 1이니까 쓰지 않는 것입니다.
이제 2차원 배열을 배열포인터로 구현해봅시다.
#include <stdio.h>
int main() {
int i,j;
int arr[3][4] = { {1,2,3,4}, {5,6,7,8}, {9,10,11,12} };
int(*pArr)[4] = arr;
int row = sizeof(arr) / sizeof(arr[0]);
int col = sizeof(arr[0]) / sizeof(arr[0][0]);
for (i = 0; i < row; i++) {
for (j = 0; j < col; j++)
printf("%d ", pArr[i][j]);
printf("\n");
}
}
arr의 각 행 길이와 pArr의 행의 길이를 맞추고 있다는 것을 보세요. 그리고 pArr[0:2]는 각각 사이즈가 16이며 마치 배열처럼 동작이 가능합니다.
이것을 어디다가 활용할 수 있을까요??
함수에 전달인자로 배열을 받을때 주로 사용합니다.
#include <stdio.h>
void printArr(int(*pArr)[4],int row,int col) {
int i, j;
for (i = 0; i < row; i++) {
for (j = 0; j < col; j++)
printf("%d ", pArr[i][j]);
printf("\n");
}
}
int main() {
int arr[3][4] = { {1,2,3,4}, {5,6,7,8}, {9,10,11,12}};
int row = sizeof(arr) / sizeof(arr[0]);
int col = sizeof(arr[0]) / sizeof(arr[0][0]);
printArr(arr,row,col);
}
매개변수를 받으려면 위와 같이 전달받고, 배열처럼 인덱싱을 편하게 사용할 수 있습니다.
더 간편한 방법으로는 int (*pArr)[4]를 int pArr[][4]로 바꿔줘도 실행이 가능합니다. 왜냐면 *pArr은 pArr[]과 거의 같은 의미이기 때문입니다.
void printArr(int pArr[][4],int row,int col) {
int i, j;
for (i = 0; i < row; i++) {
for (j = 0; j < col; j++)
printf("%d ", pArr[i][j]);
printf("\n");
}
}
C언어에서 scanf와 printf 함수를 통해서 키보드로 입력을 받고 모니터로 출력해주는 그런 프로그램들을 많이 보았을 겁니다. 이런 키보드나 모니터같은 입출력 장비를 콘솔이라고 합니다. 그래서 콘솔 입출력을 해왔던 것이죠.
여기서는 파일 입출력에 대해서 설명합니다. 사실 콘솔 입출력과는 별로 다를바가 없습니다. 단지 그 대상이 모니터나 키보드가 아닌 파일이기 때문이죠. 본격적으로 파일 입출력을 설명하기 전에 우리는 스트림에 대한 개념을 먼저 알아야합니다.
> 그전에 왜 C 표준입출력을 사용하나요?
리눅스를 배우셨던 분들은 open, read, write, close를 이용해서 파일을 다뤄보셨을 겁니다. 그때는 open에 필요에 따라 여러 플래그들을 줄 수가 있는데요. 예를 들어 O_RDONLY, O_CREAT 등 말이죠. 이거 구차하게 일일히 헤더 추가한 다음에 파일 디스크립터를 가져와서 write, read하는 것을 C 표준입출력 라이브러리에서는 stdio.h만 포함해서 사용할 수 있습니다. 아주 개꿀이라는 얘기죠. 그리고 변태같은 플래그들을 포함하지 않아도 사용하기에 적합한 플래그들을 미리 조합해놨기 때문에 상큼하게 그걸 사용하면 됩니다. 또한 내부적으로 버퍼를 사용하기 때문에 read, write 함수들을 최적으로 사용하게 됩니다.
스트림(Stream)
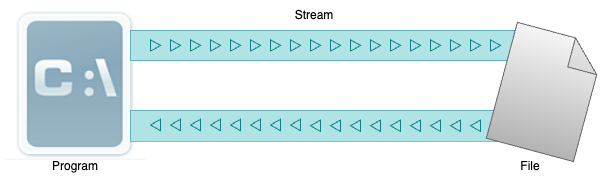
영어를 그대로 직영하게 되면 흐름이라는 건데요. 비슷하게 생각하시면 됩니다. 프로그램에서 파일이 열리면 C표준입출력은 스트림(stream)이라는 파일과 프로그램 사이의 추상적인 흐름이 일어나는 파이프를 생성합니다. 그래서 파일이 열리게 되면 개념적으로 스트림을 통해서 파일에 기록하거나 읽을 수 있습니다. 만약 파일을 읽기만 하겠다하면 읽기 전용의 스트림을 여는 것이고, 파일을 쓰기만 할 것이라면 쓰기 전용의 스트림을 열어서 거기에 기록을 하면 됩니다.
그래서 아래와 같이 어떤 프로그램에서 File이라는 이름의 파일을 읽고 쓰기 위해서 스트림을 열면 아래와 같은 상황이 발생하게 됩니다. 그래서 바이트 단위던, 줄 단위던 입력이 흐름이 가능한 상태가 됩니다.
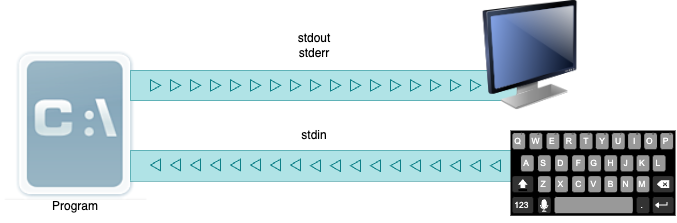
기본적으로 보통 프로그램에서는 3개의 스트림이 열려있습니다. 바로 표준 입력 스트림(stdin), 표준 출력 스트림(stdout), 표준 에러 스트림(stderr)입니다. 이 3개는 콘솔에 대해서 열려있는 스트림들입니다.
stdin, stdout, stderr
키보드로 입력받고, 모니터로 출력하는 것도 C표준 입출력에서는 스트림으로 간주하게 됩니다. 그래서 우리가 stdin을 통해서 입력을 받는다면 키보드를 통해서 입력을 받는 것이고, 표준 출력 스트림으로 출력한다면 모니터 화면에다가 출력이 되는 겁니다. 그래서 파일 대신 모니터와 키보드가 스트림 끝에 놓여있는 것을 보세요.
파일의 종류 ( 텍스트 파일 , 이진 파일)
파일을 사람이 쓰고 읽냐, 컴퓨터가 쓰고 읽냐에 따라서 텍스트 파일(text-file), 이진 파일(binary-file)로 나누게 됩니다. 이와 같은 구분은 문자열로 입출력을 하느냐, 아니면 바이너리로 입출력을 하느냐를 위해서 구분합니다. 맨 처음 파일에 대해서 스트림을 생성할 때 결정이 됩니다.
1. 파일 열기 fopen
파일 함수는 표준입출력(stdio.h) 헤더파일에 존재합니다. 파일에 어떤 데이터를 읽고, 쓰고, 추가하려면 일단 파일을 열어야겠지요. 함수를 한번 보시죠.
filename : 파일명을 말합니다. 절대 경로나 상대 경로로 줄 수 있습니다. 상대 경로는 그 프로젝트 위치를 기준으로 합니다.
mode : 파일을 어떤 방식으로 열건지 정합니다. 스트림 방식을 정하는 겁니다. 입력 스트림인지, 출력 스트림인지.
-동작 모드
모드
설명
flag 조합
r(read)
1. 파일을 읽기 전용으로 엽니다. 2. 파일이 있어야합니다.
O_RDONLY
w(write)
1. 파일을 쓰기 전용으로 엽니다. 2. 주의해야합니다. 파일이 존재한다면 기존의 내용을 지우고 쓰기 때문이죠. 3. 파일이 없으면 새로 생성합니다.
O_WRONLY | O_CREAT | O_TRUNC
a(append)
1. 파일이 있으면 파일의 끝에 내용을 추가합니다. 2. 파일이 없으면 생성해서 내용을 추가합니다.
O_WRONLY | O_CREAT | O_APPEND
r+
1. 파일을 읽고 쓰기 위해 엽니다. 2. 파일이 반드시 있어야 합니다.
O_RDWR
w+
1. 파일을 읽고 쓰려고 엽니다. 2. r+와 다르게 파일이 있는 경우 내용을 덮어쓰고 없으면 생성해서 데이터를 씁니다.
O_RDWR | O_CREAT | O_TRUNC
a+
1. 파일을 읽고 갱신하기 위해 엽니다. 2. 파일이 없으면 생성해서 데이터를 추가합니다.
O_RDWR | O_CREAT | O_APPEND
- 이진 또는 텍스트 모드(t, b)
텍스트모드가 기본(default)입니다. 이진 모드로 파일을 열려면 b를 추가합니다.
ex) 이진모드로 읽기 위해 파일을 open -> rb
파일을 여는 데 성공했다면 그 파일에 대한 포인터를 return합니다.
하지만 파일을 여는 데 실패했으면 NULL을 반환하죠.
2. 파일 닫기 fclose
무엇이든 열었으면 닫는 것이 원칙이죠. 파일 스트림을 닫으려면 fclose를 사용하시면 됩니다.
int fclose(FILE *stream);
그냥 열었던 파일 포인터를 집어넣으면 됩니다. 성공하면 0을 반환하고 실패하면 EOF(-1)를 반환합니다.
3. 텍스트 파일 읽기 함수
파일은 두 종류의 파일이 있다고 했죠? 사람이 읽을 수 있는 텍스트 형식의 파일과 컴퓨터가 읽고 처리하는 바이너리 파일, 즉 이진 파일이 있습니다. 우선 텍스트 파일을 읽는 함수는 쓰임새에 따라 여러가지가 있습니다.
3.1 한문자 읽기 : fgetc, getc, getchar
#include <stdio.h>
int fgetc(FILE *stream);
int getc(FILE *stream);
int getchar(void);
fgetc와 getc는 같은 기능을 하는 함수입니다. getchar() 함수는 키보드용 한문자 입력을 받는 함수와 같아서 getc(stdin)과 같습니다.
getc = getc , getc(stdin) = getchar()
stream에서 한 글자를 읽어오는 함수이며, 일반적으로 반환형은 한 글자의 ASCII값인 정수형 값입니다. 파일의 끝에 도달할 시에 EOF를 return합니다. EOF는 End-Of-File로 -1입니다. 이렇게 반환형이 (signed) int인 이유는 이 EOF를 반환받기 위해서입니다.
3.2 한 줄 읽기 : fgets
#include <stdio.h>
char *fgets(char *s, int size, FILE *stream);
stream에서 문자 한줄을 읽어올때 사용하는 함수이며 size 이하의 문자 한줄을 s로 읽어옵니다. 이때 개행문자까지 읽어옵니다. 그래서 개행문자('\n') 다음 문자의 끝을 나타내는 문자인 NULL('\0')이 붙습니다. 간단히 사용법을 확인해볼까요? 다음은 stdin으로 콘솔(키보드)로부터 입력을 받는 단순한 예제입니다.
buffer에 담긴 내용을 기록하는데 size만큼의 count 만큼 버퍼로부터 stream쪽으로 씁니다. 성공하면 count를 return하고 실패한다면 count가 아닐 수 있습니다.
예제 - 이진데이터 구조체 저장, 읽어오기
이진 파일을 사용할 수 있는 가장 큰 장점은 모든 자료를 이진데이터로 쓸 수 있다는 점입니다. 객체(구조체)도 그냉 냅다 쓸 수 있습니다. 모든 것을 이진 데이터로 쓰기 때문이지요. 다음은 구조체를 파일에 쓰고, 그 파일로부터 읽어오는 예제를 보여줍니다.
//info_writer.c
#include <stdio.h>
#define NUM 3
typedef struct _student{
char name[16]; //이름
unsigned int age; //나이
unsigned int id; //학번
} student;
int main(){
FILE *fp;
student s[NUM] = {
{"kim", 16, 1234},
{"lee", 16, 1235},
{"lim", 17, 1111}
};
//이진(b)으로 쓰기용, 없으면 만들고 있으면 덮어쓴다(w+)
fp = fopen("info.bin", "wb+");
if(fp == NULL){
printf("fopen error\n");
return 1;
}
if(fwrite(s, sizeof(student), NUM, fp) != NUM){
printf("fwrite erorr\n");
fclose(fp);
return 1;
}
printf("Student Information Saved OK \n");
fclose(fp);
}
//info_reader.c
#include <stdio.h>
#define NUM 3
typedef struct _student{
char name[16]; //이름
unsigned int age; //나이
unsigned int id; //학번
} student;
int main(){
int i;
FILE *fp;
student s[NUM];
fp = fopen("info.bin", "rb"); //읽기 전용
if(fp == NULL){
printf("fopen error\n");
return 1;
}
if(fread(s, sizeof(student), NUM, fp) != NUM){
printf("fread erorr\n");
fclose(fp);
return 1;
}
for(i = 0; i < NUM; i++){
printf("[%d]\n", i);
printf("name : %s, age : %u, id : %u\n",
s[i].name, s[i].age, s[i].id);
}
fclose(fp);
}
# gcc info_writer.c -o writer
# gcc info_reader.c -o reader
# ./writer
Student Information Saved OK
# ./reader
[0]
name : kim, age : 16, id : 1234
[1]
name : lee, age : 16, id : 1235
[2]
name : lim, age : 17, id : 1111
7. 버퍼
버퍼는 C표준입출력에서 입력과 출력을 효율적으로 처리하기 위한 일종의 저장공간입니다. 내부적으로 write, read를 적시에 한번만 호출하기 위한 것이 목적입니다. 그런데 이러한 버퍼의 처리 방식을 잘 모르면 낭패를 볼 수 있는데요. 아래의 코드를 봅시다.
//buffer.c
#include <stdio.h>
int main(){
char c;
printf("아무 글자나 하나 입력:");
scanf("%c", &c);
printf("입력받은 글자 : %c\n", c);
printf("다시 입력 : ");
scanf("%c", &c);
printf("입력받은 글자 : %c\n", c);
}
실행하게 되면 두 번재 scanf에 입력을 주기도 전에 프로그램이 끝나게 됩니다. 분명 scanf를 통해서 한글자 입력을 받는 코드를 작성했으에도 말이죠.
# ./a.out
아무 글자나 하나 입력:H
입력받은 글자 : H
다시 입력 : 입력받은 글자 :
#
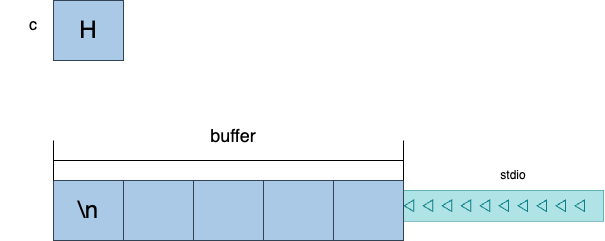
이 프로그램은 내부적으로 이렇게 동작하게 됩니다. 'H'라는 문자를 입력하면 내부적으로 엔터에 해당하는 개행 문자 '\n'도 입력이 됩니다.
결국 버퍼에는 H와 '\n'이 입력이 되게 되며 변수 c에는 'H'가 담기게 되겠죠. 버퍼에 남아있는 건 개행문자 '\n'입니다. 그래서 다음 scanf는 이 개행문자를 입력받아 입력이 끝나게 되는 겁니다.
위는 줄 단위 버퍼링의 사례로 결국에는 남아있는 버퍼를 비워줘야합니다. 버퍼를 비워주는 방법에는 여러 가지 방법이 있는데요.
7.1 버퍼를 비우는 방법들
- 간단한 방법은 단순히 문자 하나 입력받는 거죠. 아래와 같이말이죠.
printf("아무 글자나 하나 입력:");
scanf("%c", &c);
getchar();
printf("입력받은 글자 : %c\n", c);
printf("다시 입력 : ");
scanf("%c", &c);
getchar();
printf("입력받은 글자 : %c\n", c);
- fflush 함수 사용
#include <stdio.h>
int fflush(FILE *stream);
fflush 함수를 사용할 수가 있는데, 이 방법은 표준이 아니므로 권장되지 않습니다. 실제 제 ubuntu시스템에서는 동작하지 않습니다.
- scanf에서 공백 사용
scanf("%c", &c) -> scanf(" %c", &c)
앞에 공백 문자 하나를 넣어주세요.
- 개행문자가 나올때까지 제거
while(getchar() != '\n');
어떤 시스템에는 \r\n으로 개행합니다. 그게 윈도우즈인데, 이럴 때는 getchar()만 사용하게 되면 \r만 제거 됩니다. 그래서 아예 \n까지 제거 할 수 있도록 while문을 도는 방식을 사용할 수 있습니다. 약간 고급진 말로 '\r'은 커서를 맨 앞으로 돌리는 CR(Carriage return)이라 하며 '\n'은 커서는 그자리이며 라인만 바꾸는 LF(Line Feed)라고 합니다.