헨리 하워드 홈즈는 본명이 아니라 가명입니다. 이 가명으로 유명한 이유는 가명을 쓰면서 대량학살이 이뤄지기 때문이죠. 본명은 허만 웹스터 마젯(Herman Webster Mudgett)인데요. 미국에서 기록된 최초 연쇄 살인마입니다. 오늘날의 연쇄살인마와는 클라스가 조금 다릅니다. 아예 호텔까지 지어버리거든요.
H.H.Holmes
출생
홈즈는 1861년 5월 16일, 미국 뉴햄프셔(New hampshire) 길맨턴에서 태어났습니다. 어렸을 적 홈즈는 매우 똘똘하고 예의바르며 어른 들에게 무척이나 예쁨받는 아이였습니다. 게다가 똘똘한 머리까지 가졌습니다. 하지만 어렸을 적 홈즈는 행복하다고 할 수 없었습니다. 아니, 매우 불행한 삶을 살았습니다. 아버지는 독실한 신자였었는데, 특히 잠언 13장 24절의 구문을 그렇게 가슴속에 새겼다고 합니다. 홈즈를 이유없이 폭행하게 됩니다. 왜냐면 아버지는 홈즈를 무척이나 사랑했거든요.
잠언 13장 24절 매를 아끼는 자는 그의 자식을 미워함이라 자식을 사랑하는 자는 근실히 징계하느니라
홈즈의 대학 졸업 사진
살인 호텔
1886년, 그는 시카고로 이사를 가는데요. 거기에서 헨리 하워드 홈즈라는 이름을 사용하기 시작합니다. 시카고 어떤 약국에서 조수 역할을 하면서 약국일을 했고, 약국을 인수하게 됩니다. 약국이 잘되자 홈즈는 그 앞에 호텔을 하나 짓는데요. 홈즈는 그 호텔을 성이라고 부릅니다. 이 호텔이 보통 호텔이 아닙니다. 살인을 목적으로 만들어진 호텔이었는데요.
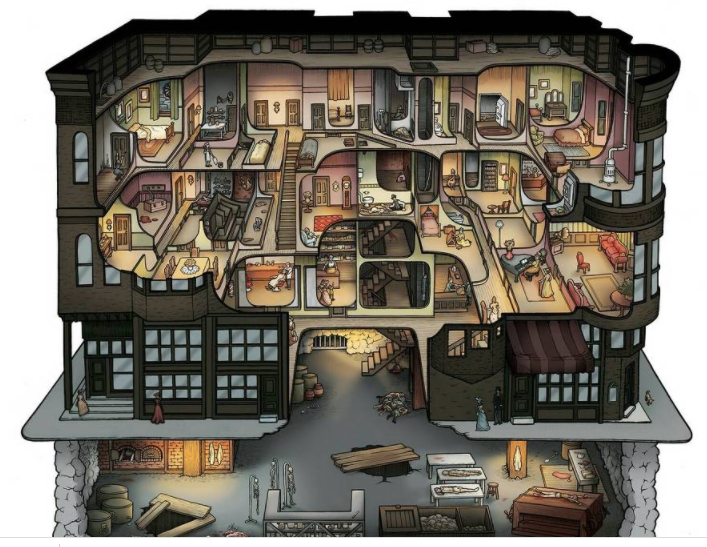
홈즈의 성
성의 내부
100개가 넘는 방과 비밀 통로, 그리고 시체를 단숨에 지하실로 옮길 수 있게 만든 낙하장, 각 방들은 파이프가 연결되어있어 이곳에서 독가스를 살포할 수 있었습니다. 벽은 석면으로 이루어져있어 내부의 소리가 밖으로 세어나가지 않았습니다. 지하실은 홈즈가 시체를 해체하고 소각할 수 있는 홈즈의 작업장이었습니다.
이러한 호텔을 짓는데 일조했던 사람은 그의 동료 밴자민 피첼. 그의 기술이 이 성에 접목이 되었습니다.
1893년 시카고 만국 박람회에서 엄청난 관광객들이 몰려오게 되며 숙박 시설이 부족해지게 됩니다. 홈즈는 이런 상황이 떼돈을 벌 수 있는 엄청난 기회였던 셈이죠. 홈즈는 객실에 있는 손님을 티나지 않게 몇몇 죽이게 됩니다. 이렇게 죽인 시체는 의과 대학에 가져다가 팔게 되죠.
체포
살인을 3년간 지속하면서 이제 꼬리를 밟히게 되는데요. 실종자의 대다수가 이 호텔에 머물렀다는 사실을 알게된 경찰은 홈즈를 유력 용의자로 지목하게 감시하게 됩니다.
물론 공범인 벤자민 피첼도 같이 감시하게 되는데, 홈즈는 돈독이 제대로 올라서 자신의 동료 피첼마저 죽입니다. 당시 피첼을 감시하고 있었던 경찰에 의해 드디어 홈즈는 붙잡히게 되면서 살인 호텔에서의 살인은 끝나게 됩니다.
H.H.Holmes는 미국에 기록된 최초의 연쇄살인범으로 매우 유명한 인물입니다. 어떻게 호감형인 외모와 명석한 지성으로 그런 짓을 저질렀을까요? 그 능력을 조금 더 좋은 곳에 썼더라면 어땠을까요? 홈즈는 차트를 달리는 남자에서 소개된바가 있습니다.
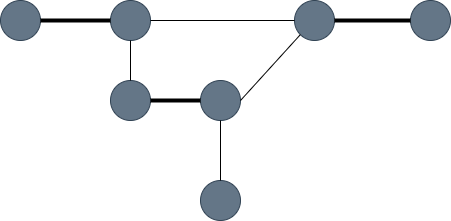
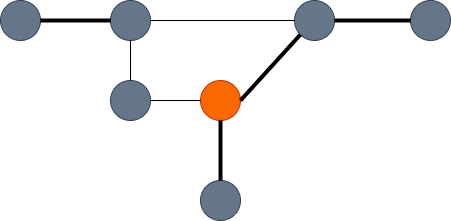
그래프에서 정점의 짝을 이루게 해볼까요? 정점은 다른 정점과 짝이 될 수 있는데, 단 여기서 한 정점은 최대 한 정점과 짝을 이룰 수 있는 조건으로 말이죠. 정점이 모두 선택될 필요는 없습니다. 아래의 그래프가 그 예를 보여줍니다. 왼쪽은 1:1 매칭이 된 간선을 선택한 것이고 오른쪽은 1:1 매칭이 되지 않은 그래프입니다. 왼쪽의 그래프는 간선을 3개 갖는데 각 정점은 1:1로 짝을 이루고 있네요. 하지만 오른쪽 그래프에서 주황색 정점은 위, 아래 정점 2개와 짝을 이루고 있으니 1:1 매칭이 되었다고 볼 수 없습니다.
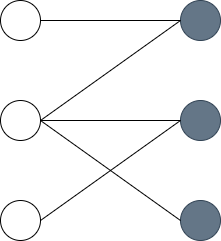
정점을 보기좋게 두 그룹으로 나누면 어떨까요? 왼쪽에 정점이 오른쪽에 정점과 연결될 수 있도록 보면 더 보기 편할 거 같습니다.
이처럼 그래프의 정점을 두 그룹으로 나눈 후 모든 간선이 서로 다른 그룹의 정점들을 연결할 수 있는 그래프를 이분 그래프라고 합니다. 여기서 가장 큰 매칭을 찾아내는 문제를 최대 매칭 문제(Maximum Matching)라고합니다. 간단하게 이분 매칭이라고 부릅니다.
이분 매칭을 네트워크 유량을 이용하여 풀게 됩니다. 그보다는 아주 간단하게 dfs를 이용해서 풀 수 있습니다. 이분 매칭을 구현한 코드가 아래에 있습니다. (이 코드는 구종만 님의 알고리즘 문제해결 전략의 코드입니다.)
#include<iostream>
#include<algorithm>
#include<vector>
#include<string.h>
using namespace std;
const int MAX_N = 201;
int adj[MAX_N][MAX_N];
vector<bool> visited;
vector<int> partner;
int N, M;
bool dfs(int here) {
if (visited[here]) return false;
visited[here] = true;
for (int there = 1; there <= M; there++) {
if (adj[here][there]) {
//there의 짝이 정해지지 않았거나
//there의 짝이 다른짝과 매칭된다면 true반환
if (partner[there] == -1 || dfs(partner[there])) {
partner[there] = here;
return true;
}
}
}
return false;
}
int bipartiteMatch() {
int ret = 0;
for (int i = 1; i <= N; i++) {
visited = vector<bool>(N + 1, false);
if (dfs(i)) ret++;
}
return ret;
}
왼쪽의 정점은 A, 오른쪽의 정점은 B라고 칭한다면 partner라는 배열은 B와 짝이된 A정점을 뜻합니다. 초기화는 아래와 같이 -1로 초기화시킵니다. partner[b]가 -1이면 아직 짝이 정해지지 않은 정점을 의미합니다.
partner = vector<int>(M + 1, -1);
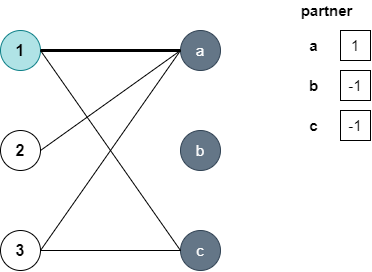
전체적으로 보면 왼쪽(here)에서 하나 씩 dfs를 탐색하는데요. dfs를 통해 짝을 찾을 수 있다면 매칭된 수를 하나 증가시킵니다. 코드와 글로는 이해가 어렵습니다. 그림이 있어야겠네요. 처음에 파란색 정점이 dfs를 수행합니다. 이때 조건문을 잘보세요. 설명을 편하게 하기 위해서 왼쪽 정점은 숫자, 오른쪽 정점은 알파벳으로 가정하도록 하겠습니다.
정점 1은 정점 a와 연결이 되고 있고(adj[1][a]), partner[a]의 짝은 아직 정해지지 않았으니, partner[a]=1이 되고 dfs는 true를 반환합니다. 그러니 짝을 하나 찾았네요.
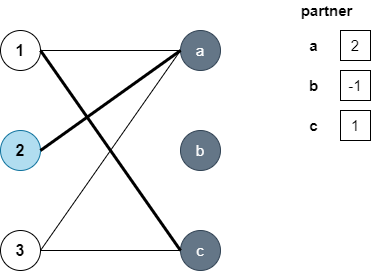
이제 2번에서 dfs를 수행합니다. 연결된 간선의 정점이 a인데, a는 이미 짝이 있으나, a의 파트너인 1이 다른 짝과 매칭될 수 있는지(dfs(1))을 보는데요. 1은 다시 a로 가려고 하지만 이미 방문된 정점(visited[a]=true)이기 때문에 다른 연결된 c쪽으로 탐색합니다. c는 아직 짝이 정해지지 않았기 때문에 c의 파트너를 1로 정합니다. 그 결과 a의 파트너는 3이 될 수 있네요.
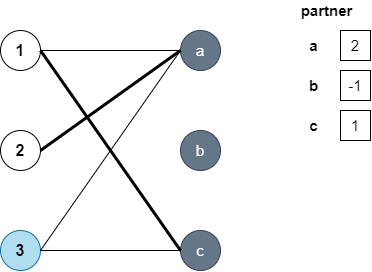
이제 다음 정점인 3에서 dfs를 시작합니다. 연결된 정점은 a와 c인데요. a는 이미 짝이 정해져있으나, partner[a]에서 dfs를 수행하면 다른 짝을 구할 수도 있으니 dfs(partner[a]) = dfs(1)를 수행합니다. dfs(1)은 dfs를 수행하지 않은 c로 탐색을 수행할텐데, 이때 c와 유일하게 연결된 정점 3은 이미 방문된 상태이므로 결국 다른 짝을 찾지 못했습니다.
이제 3의 다른 정점 c도 역시 같은 방법으로 경로를 찾는데 c는 이전에 방문되었던 상태라서 종료합니다. 결국 3에서 dfs를 수행한 결과 다른 짝을 찾지 못했네요.
이 문제는 위의 코드를 그대로 구현하여 풀 수 있습니다. N마리의 소와 M개의 축사가 있는데, 각 소들은 들어가길 희망하는 축사가 있어 그 외의 축사는 들여보낼 수 없습니다. 소가 희망하는 축사는 여러개가 될 수 있는데요. 이때 소를 최대한으로 들여보낼 수 있는 수를 구하는 것입니다. (1<= N,M <= 200)
첫줄에는 N,M을 입력으로 받고 그 다음부터 차례대로 N 줄까지 1번 소가 원하는 축사의 수, 축사의 번호를 차례대로 입력받습니다. 그때 입출력의 예는 아래와 같습니다.
입력
출력
5 5 2 2 5 3 2 3 4 2 1 5 3 1 2 5 1 2
4
이 문제를 해결할 수 있는 전체 코드는 아래와 같습니다.
#include<iostream>
#include<algorithm>
#include<vector>
#include<string.h>
using namespace std;
/*이분매칭
소와 방을 1:1로 짝을 지을 수 있는 최대수를 반환
*/
const int MAX_N = 201;
int adj[MAX_N][MAX_N];
vector<bool> visited;
vector<int> partner;
int N, M;
bool dfs(int here) {
if (visited[here]) return false;
visited[here] = true;
for (int there = 1; there <= M; there++) {
if (adj[here][there]) {
//there의 짝이 정해지지 않았거나
//there의 짝이 다른짝과 매칭된다면 true반환
if (partner[there] == -1 || dfs(partner[there])) {
partner[there] = here;
return true;
}
}
}
return false;
}
int bipartiteMatch() {
int ret = 0;
for (int i = 1; i <= N; i++) {
visited = vector<bool>(N + 1, false);
if (dfs(i)) ret++;
}
return ret;
}
int main() {
cin >> N >> M;
partner = vector<int>(M + 1, -1);
for (int from = 1; from <= N; from++) {
int n;
cin >> n;
for (int i = 0; i < n; i++) {
int to;
cin >> to;
adj[from][to] = 1;
}
}
cout << bipartiteMatch() << endl;
return 0;
}