해시테이블(Hashtable)
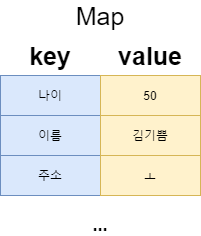
해시테이블은 해시맵(HashMap)과 함께 Map을 구현한 키와 값 쌍을 데이터로 저장한 컬렉션(Collection)입니다. 여기서 키는 유일해야만 합니다. 해시테이블은 이 키를 가지고 키에 해당하는 값을 찾습니다.
Hashtable과 HashMap의 차이
Hashtable과 HashMap과의 차이점은 Thread-Safe인지 아닌지가 그 차이점인데요. Hashtable은 동기화가 걸려있어서 Thread-Safe하다고 할 수 있으며 HashMap은 동기화가 없어 unsafe하다고 할 수 있습니다. 그래서 안전성을 추구한다면 Hashtable을 쓰시면 되고, 데이터의 빠른 처리를 위해서라면 HashMap을 사용하시면 됩니다.
여기서 Hastable의 Thread-Safe가 무슨 의미를 하는지 맨 아래의 예제를 통해서 알아보도록 하세요.
해시맵의 사용법을 알고싶으신 분은 아래의 링크를 참고해주세요.
[자바] 해시맵(HashMap)의 개념과 사용 예, 기본 메소드와 같은 키인지 판별하는 방법
해시맵(HashMap) 해시맵은 이름 그대로 해싱(Hashing)된 맵(Map)입니다. 여기서 맵(Map)부터 짚고 넘어가야겠죠? 맵이라는 것은 키(Key)와 값(Value) 두 쌍으로 데이터를 보관하는 자료구조입니다. 여기서
reakwon.tistory.com
인터페이스인 Map을 구현한 만큼 HashMap과 사용법이 거의 비슷합니다. put으로 키와 값을 저장하고 get으로 키에 해당하는 값을 읽어옵니다. Hashtable에서 table은 소문자라는 점! 유의해주시길 바라요.
예 ) put, get 메소드 사용방법
import java.util.Hashtable;
import java.util.HashMap;
import java.util.Map;
public class Main {
public static void main(String[] ar) {
Map<String,Integer> ht=new Hashtable();
ht.put("key1", 50);
ht.put("key2",100);
ht.put("key2",250); //같은 키가 들어갈 경우에는?
System.out.println(ht);
System.out.println(ht.get("key1"));
System.out.println(ht.get("key2"));
System.out.println(ht.get("key3")); //키가 없을 경우에는?
}
}
결과
{key2=250, key1=50}
50
250
null
만약 동일한 키를 가지고 데이터를 집어넣게 된다면 가장 마지막의 키와 값 요소로 저장이 됩니다. 그리고 키가 존재하지 않으면 null을 반환합니다.
예) 갖고 있는 모든 키를 순회(keySet)
만약 Hashtable이 갖고 있는 모든 키를 알고 싶다면 어떻게 할까요? 그럴때는 keySet()메소드로 모든 키를 가져올 수 있습니다. 이때 반환하는 자료형은 Set입니다. 아래의 코드같이 키와 값을 추출할 수 있습니다.
public static void main(String[] ar) {
Map<String,Integer> ht=new Hashtable();
ht.put("foo",100);
ht.put("bar",250);
for(String key:ht.keySet()) {
System.out.println("{"+key+","+ht.get(key)+"}");
}
}
결과
{bar,250}
{foo,100}
예) Hashtable에 Hashtable을 추가(putAll)
만약 두 Hashtable을 합치고 싶다면 putAll() 메소드를 사용하면 됩니다. 다만 putAll()의 인자로 전달한 Hashtable의 키, 값의 변화가 있다해도 합쳐진 Hastable에는 영향을 받지 않습니다.
public static void main(String[] ar) {
Map<String,Integer> ht1=new Hashtable();
ht1.put("key1",9999);
ht1.put("key2",2020);
Map<String,Integer> ht2=new Hashtable();
ht2.put("key3",3030);
ht2.put("key4",8888);
ht2.putAll(ht1);
System.out.println(ht2);
ht1.put("key5",5555); //ht1에 데이터 추가
System.out.println(ht2);
}
결과
{key4=8888, key3=3030, key2=2020, key1=9999}
{key4=8888, key3=3030, key2=2020, key1=9999}
예) ForEach() 메소드로 키와 값 순회하기
Hashtable에는 ForEach메소드가 존재하는데, 이것을 가지고 키와 값으로 동작을 정의할 수 있습니다. 람다식을 알긴해야하는데, 사용법만 알아도 상관은 없습니다.
public static void main(String[] ar) {
Map<String,Integer> ht=new Hashtable();
ht.put("application layer", 7);
ht.put("presentation layer", 6);
ht.put("session layer", 5);
ht.put("tranport layer", 4);
ht.put("network layer", 3);
ht.put("datalink layer", 2);
ht.put("physical layer", 1);
ht.forEach((key,value)->
{
System.out.println("{"+key+","+value+"}");
});
}
결과
{session layer,5}
{physical layer,1}
{datalink layer,2}
{presentation layer,6}
{tranport layer,4}
{network layer,3}
{application layer,7}
Hashtable의 Thread-Safe
이제 여기서 Hashtable이 왜 Thread-Safe한지 설명하도록 하겠습니다. 우선 쓰레드에 대한 개념에 대해서 알 필요가 있습니다. 자바 쓰레드의 사용법은 아래의 링크를 참고해주세요.
[JAVA/자바] 쓰레드(Thread) 다루기( Thread상속, Runnable 구현, join)
쓰레드(Thread) 쓰레드(Thread)는 간단히 정의하면 하나의 프로세스(실행중인 프로그램이라고 합니다.)에서 독립접으로 실행되는 하나의 일, 또는 작업의 단위를 말합니다. 뭐, 더 간단히 말해 쓰레
reakwon.tistory.com
우선 Thread-Safe하지 않은 HashMap의 코드로 아래의 코드를 작성해보고 결과를 봅시다.
public class Main {
static Map<String,Integer> hm=new HashMap(); //thread-unsafe
public static void main(String[] ar) throws InterruptedException {
Runnable runnable=new Thread() {
@Override
public void run(){
hm.put("http",80);
hm.put("ssh", 22);
hm.put("dns", 53);
hm.put("telnet",23);
hm.put("ftp", 21);
hm.forEach((key,value)->
{
try {
Thread.sleep(1000);
}catch(InterruptedException e) {
e.printStackTrace();
}
System.out.println("{"+key+","+value+"}");
});
}
};
Thread thread=new Thread(runnable);
thread.start();
Thread.sleep(1000);
hm.put("dhcp",67);
System.out.println("MainThread end");
}
}
보세요. 이 코드의 대한 저의 의도는 생성된 쓰레드(이하 thread라고 칭하도록 하겠습니다.)가 1초마다 run() 메소드의 저장된 키와 값을 순회하면서 출력하는 겁니다. 물론 예외없이 정상적으로요. 그러니 출력은 아래와 같아야하는 것이 이 코드의 의도입니다. 물론 MainThread가 끝나는 시점은 언제인지 예측 불가능하므로 어디서 나오든 상관없습니다. 중요한 것은 ftp~ssh까지만 출력되어야하는 것이 저의 의도입니다.
MainThread end
{ftp,21}
{telnet,23}
{dns,53}
{http,80}
{ssh,22}
하지만 우리의 예상과는 다르게 아래와 같이 출력됩니다. ConcurrentModificationException이라는 예외(Exception)가 발생하게 됩니다. 쓰레드들이 동시에 데이터를 변경할때 이 예외가 발생합니다.
MainThread end
{ftp,21}
{telnet,23}
{dns,53}
{http,80}
{ssh,22}
{dhcp,67}
Exception in thread "Thread-1" java.util.ConcurrentModificationException
at java.base/java.util.HashMap.forEach(HashMap.java:1428)
at aa.Main$1.run(Main.java:18)
at java.base/java.lang.Thread.run(Thread.java:831)
왜 이런 예외가 발생할까요? 코드를 하나씩 해석해보도록 합시다.
자, HashMap은 두 스레드가 공용으로 사용할 수 있도록 static으로 지정해놓았고, 생성된 쓰레드는 해시맵에 http~ftp까지의 키와 값을 put하고 있습니다(여기서 value는 그 프로토콜의 포트번호를 의미합니다. 뭐 여기서는 중요한게 아니지요.) thread는 put으로 키,값을 저장하고 난 후에 forEach() 메소드를 이용해서 1초마다 갖고 있는 키와 값을 출력합니다.
메인스레드에서는 thread가 forEach() 메소드를 수행할 시간을 벌어주기 위해서 1초간 잠재워줍니다. 그 후 thread는 자신의 루틴(routine) 중 forEach()메소드를 실행합니다.
이때 thread가 forEach() 메소드가 수행하는 중에 메인 쓰레드에서 put으로 데이터를 집어넣고 있는 상황이죠. 즉, HashMap에 동시에 접근해서 변경이 발생하게 되는 그런 코드입니다.
우리의 의도대로 동작하게 만드려면 어떻게 해야할까요? 이럴때 synchronized라는 키워드로 우리가 직접 동기화를 처리할 수도 있지만 더 간단한 방법으로는 바로 Hashtable을 사용하는 것입니다. 이 문제를 해결하려면 단 한줄만 바꾸면 됩니다.
static Map<String,Integer> hm=new Hashtable(); //thread-safe
물론 hm(HashMap)이라는 변수도 ht(Hashtable)로 바꾸면 더 일관성있겠죠. 그 후의 결과는 우리의 의도대로 아래와 같이 동작함을 알 수 있습니다.
{ftp,21}
{ssh,22}
{http,80}
{dns,53}
{telnet,23}
MainThread end
이처럼 스레드에 대해서 동시접근에 안전하려면 Hashtable을 쓰는 것이 좋고, 단일 쓰레드에서 사용한다면 HashMap을 쓰는 것이 좋습니다.
지금까지 Hashtable의 개념, 그리고 사용방법과 HashMap과의 차이점을 코드를 통해서 알아보았습니다.
'언어 > JAVA' 카테고리의 다른 글
| [자바] 이것만 알면 예외(Exception) 정복 - 예제를 통한 개념과 예외 처리 방법 (0) | 2021.04.03 |
|---|---|
| [Collection] Vector 완전 정복하기 - 특징과 깊이 있는 사용법 (0) | 2021.04.01 |
| [Collection] 이것만 알면 해시맵(HashMap) 정복 가능 - HashMap의 특징, 사용법 예제 (2) | 2021.03.29 |
| [JAVA] SimpleDateFormat과 Date로 간단하게 시간 표시하기 (3) | 2020.06.30 |
| [자바/JAVA] Collections와 ArrayList를 이용한 객체 정렬 (2) | 2020.03.02 |

REAKWON
와나진짜