벡터(Vector)
벡터는 ArrayList와 같이 선형적으로 자료를 담을 수 있는 List 컬렉션입니다. ArrayList와는 다르게 동기화 처리를 하기 때문에 ArrayList보다는 속도가 느리다는 단점이 있습니다. 하지만 여러 쓰레드에서 같은 List를 써야할 필요가 있다면 Vector를 사용하시는 것이 동기화 오류를 만들지 않는 방법이겠죠.
동기화에 대한 예는 맨 아래에 설명하도록 하겠습니다. 지금부터 사용법에 대해서 알아보도록 합시다.
사용법
벡터는 Generic을 사용합니다. 꺽쇠 '<', '>' 에 자료 타입을 지정해주고 수행합니다. 꺽쇠 안에는 원소로 사용할 객체의 클래스를 명시해주면 됩니다. 아래는 Integer 형의 자료를 Vector에서 다룬다는 선언을 보여줍니다.
Vector<Integer> v=new Vector();1 - 원소 추가와 삭제, 읽기(add, remove, get)
선형으로 자료를 담고 있습니다. 그래서 데이터를 넣으면 차례차례 뒤에 데이터들이 붙어서 쌓이게 됩니다. 특정 위치의 데이터도 삭제할 수 있습니다. 그리고 정수형 index로 원소를 가져올 수 있습니다. 아래가 그 예제를 보여줍니다.
import java.util.Vector; //클래스 import
public class Main {
public static void main(String[] ar){
Vector<Integer> v=new Vector();
v.add(20); //0
v.add(50); //1
v.add(70); //2
v.add(100); //3
for(int i=0;i<v.size();i++) {
System.out.println(i+"번째 원소:"+v.get(i));
}
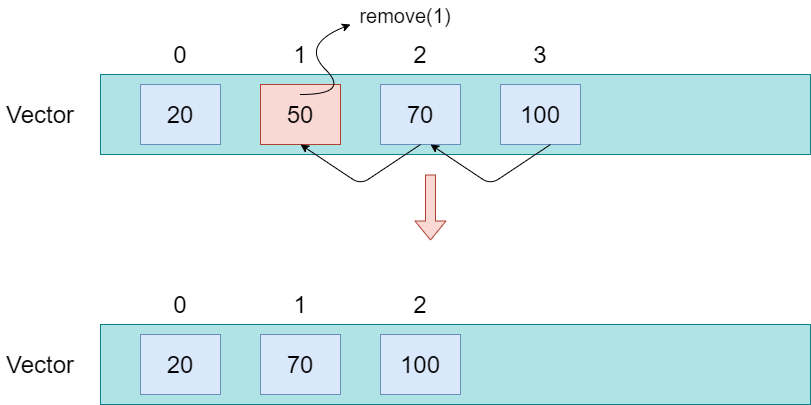
System.out.println("\n index 1 원소 삭제");
v.remove(1);
for(int i=0;i<v.size();i++) {
System.out.println(i+"번째 원소:"+v.get(i));
}
}
}
결과
0번째 원소:20
1번째 원소:50
2번째 원소:70
3번째 원소:100
index 1 원소 삭제
0번째 원소:20
1번째 원소:70
2번째 원소:100
예제를 보면 차례차례 20, 50, 70, 100의 데이터를 넣어주고 있습니다. 그리고 for문을 돌면서 출력해주고 있습니다. 차례대로 출력이 되는 것을 확인할 수 있죠? 그런데 index가 1인 50을 삭제하게 되면 삭제된 뒤의 원소들이 전부 앞으로 당겨지게 됩니다.
만약 size()보다 큰 index를 갖는 원소를 삭제하거나 get()으로 읽어온다면 ArrayIndexOutOfBoundsException이 발생하게 되므로 size() 체크를 항상 해주셔야합니다. 맨 아래 라인에 v.remove(10); 코드를 추가해서 확인해보도록 하세요.
Exception in thread "main" java.lang.ArrayIndexOutOfBoundsException: Array index out of range: 10
at java.base/java.util.Vector.remove(Vector.java:844)
at aa.Main.main(Main.java:23)
원소를 모두 삭제하고 싶다면 clear(), removeAllElements()를 사용하면 모두 지워집니다.
2. Vector를 반복할 수 있는 여러 방법
위의 예제는 단순 for문으로 i를 인덱스 삼아서 get()으로 원소를 읽어왔습니다. 이밖에도 여러 방법이 있는데, 그 방법을 소개합니다.
2-1 forEach 메소드 사용
Vector<String> v=new Vector();
v.add("korea");
v.add("england");
v.add("rusia");
v.forEach((item)->{
System.out.println(item);
});람다식을 이용해서 순회할 수 있습니다. 함수 안 괄호에는 원소가 들어갑니다. 그 변수명이 item이지요. 그리고 중괄호('{}')에는 동작부를 구현하면 됩니다. 람다식을 몰라도 사용하는 데에는 문제가 없습니다.
2-2 Iterator객체로 순회
Iterator<String> it=v.iterator();
while(it.hasNext()) {
String item=it.next();
System.out.println(item);
}
사이즈를 체크하지 않으면서 순회하고 싶다면 Iterator클래스로 객체를 만들어 사용하는 방법이 있습니다. Iterator클래스는 Java.util 패키지에 존재하니 import하여 사용해보세요. 순회에 필요한 메소드는 hasNext()와 원소를 가져오는 next()메소드만 알고 있으면 됩니다.
| 메소드 | 설명 |
| hasNext() | 이 다음에 원소가 있는지 확인합니다. 있으면 true, 없으면 false를 반환하지요. 대체로 while안의 조건문에 사용합니다. |
| next() | 다음 원소를 가져옵니다. 반환되는 객체는 Generic으로 넘겨준 원소의 자료형입니다. |
위 코드의 결과는 그 이전의 결과와 같습니다.
3. Vector와 Vector를 합치기
public static void main(String[] ar){
Vector<String> v1=new Vector();
v1.add("r");
v1.add("e");
v1.add("a");
v1.add("k");
Vector<String> v2=new Vector();
v2.add("w");
v2.add("o");
v2.add("n");
v1.addAll(v2);
v1.forEach((item)->{
System.out.print(item);
});
System.out.println();
}
결과
reakwon
addAll() 메소드로 벡터와 벡터를 합칠 수 있습니다. 단, 두 벡터는 같은 Generic 형식을 사용해야하고 합칠 벡터 뒤에 그 벡터가 붙습니다. 또는 생성자를 이용해서 객체 생성시에 벡터를 합칠 수 있습니다. 아래와 같은 형식으로 사용할 수 있습니다. 아래 예는 v2에 v1을 객체 생성시에 합칩니다.
Vector<String> v2=new Vector(v1);
4. 원소가 존재하는 지 확인
public static void main(String[] ar){
Vector<String> v=new Vector();
v.add("r"); v.add("e");
v.add("a"); v.add("kwon");
System.out.println(v.contains("r"));
System.out.println(v.contains("z"));
}
결과
true
false
contains() 메소드로 Vector에 원소가 있는지 확인할 수 있습니다. 있으면 true, 없으면 false를 반환합니다.
5. Vector 정렬
public static void main(String[] ar){
Vector<String> strV=new Vector();
strV.add("reakwon");
strV.add("hello");
strV.add("world");
//알파벳 순으로 정렬
Collections.sort(strV);
strV.forEach((item)->{
System.out.println(item);
});
System.out.println();
Vector<Integer> intV=new Vector();
intV.add(5);
intV.add(1);
intV.add(3);
//오름차순 정렬
Collections.sort(intV);
intV.forEach((item)->{
System.out.println(item);
});
}Collections.sort() 메소드를 이용해서 Vector의 데이터를 정렬할 수 있습니다. 기본적으로 숫자는 오름차순, 문자열은 사전순으로 정렬됩니다.
결과
hello
reakwon
world
1
3
5혹은 내가 만든 객체를 정렬하려면 어떻게할까요? 사람 객체를 키순으로 정렬하고 싶다면, 또는 이름 순으로 정렬, 나이순으로 정렬하고 싶다면 어떻게할까요? 우리가 직접 비교해서 Collections에게 알려줘야합니다. 그것에 대한 설명은 아래의 링크를 참고해주세요. 사용법은 동일합니다.
[자바/JAVA] Collections와 ArrayList를 이용한 객체 정렬
정렬 우리는 정렬에 관해서 배우기도 하였고 구현도 해보았습니다. 그래서 어떻게 정렬이 되는지 알고 있죠. 하지만 실제 프로그래밍하는 상황에서 이 정렬을 직접구현해서 프로그램을 만들지
reakwon.tistory.com
6. Thread-Safe 예
아까 이야기했던 동기화에 대한 부분을 확인해보도록 합시다. 우선 ArrayList로 아래의 코드를 짜면서 관찰해보죠.
public class Main {
static ArrayList<String> list=new ArrayList();
public static void main(String[] ar){
list.add("reakwon");
list.add("hello");
list.add("world");
Thread thread=new Thread(new Runnable() {
@Override
public void run() {
list.forEach((item)->{
//1초마다 원소를 출력
try {
Thread.sleep(1000);
}catch(InterruptedException e) {
e.printStackTrace();
}
System.out.println(item);
});
}
});
thread.start(); //thread 시작
//thread가 forEach문을 먼저 수행할 여유를 주기 위해 1초 기다림
try {
Thread.sleep(1000);
}catch(InterruptedException e) {
e.printStackTrace();
}
//thread가 forEach() 하는 중에 원소추가
list.add("thread-unsafe");
}
}
결과
reakwon
Exception in thread "Thread-0" java.util.ConcurrentModificationException
at java.base/java.util.ArrayList.forEach(ArrayList.java:1513)
at aa.Main$1.run(Main.java:19)
at java.base/java.lang.Thread.run(Thread.java:831)
위의 코드는 아주 간단한 코드입니다. thread라는 쓰레드와 메인 스레드는 list라는 ArrayList객체를 공유합니다. thread는 그 list를 forEach()로 1초마다 그 원소를 출력하는 역할을 하고, 메인 스레드는 스레드 생성하고 1초가 지난 다음 list에 원소를 추가하는 상황입니다. 이때 메인스레드가 thread가 forEach()를 수행하는 중에 list에 원소를 집어넣는 접근을 하게 되는데, 이때 두 스레드 동시에 list에 접근하게 됩니다. 그렇게 되면 위처럼 ConcurrentModificationException이 발생하게 되는 상황이 되죠. 어떻게 고칠까요?
ArrayList를 Vector로만 바꿔주면 이 문제는 해결됩니다.
static Vector<String> list=new Vector();MainThread는 thread가 forEach()를 종료할때까지 Vector객체에 접근할 수 없고, 반대로 메인스레드의 add()가 끝날때까지 thread는 Vector객체에 접근할 수 없습니다.
Vector는 동작마다 동기화를 걸어줍니다. 이런 일은 속도롤 떨어지게 만드는 작업이지만 멀티 스레드 환경에서는 안전한 작업이죠. 그래서 여러 스레드가 있는 환경에서 개발한다면 Vector를 사용하고 단일 스레드 환경에서는 ArrayList를 활용하시면 되겠습니다.
이상으로 Vector에 대한 포스팅을 마칩니다.
'언어 > JAVA' 카테고리의 다른 글
| [JAVA] 10진수 형식 클래스(DecimalFormat) - 세자리마다 쉼표, 소수점, 지수 나타내기 (0) | 2021.04.05 |
|---|---|
| [자바] 이것만 알면 예외(Exception) 정복 - 예제를 통한 개념과 예외 처리 방법 (1) | 2021.04.03 |
| [Collection] 이것만 알면 해시테이블(Hashtable, Thread-Safe) 정복 가능, 사용법과 자세한 예제 (0) | 2021.03.31 |
| [Collection] 이것만 알면 해시맵(HashMap) 정복 가능 - HashMap의 특징, 사용법 예제 (2) | 2021.03.29 |
| [JAVA] SimpleDateFormat과 Date로 간단하게 시간 표시하기 (3) | 2020.06.30 |

REAKWON
와나진짜