포인터라는 것은 조금 알겠는데 포인터배열은 무엇일까요... 포인터도 힘들게 배우는데 말이죠. 정말 산넘어 산입니다.
포인터배열이란 포인터를 원소로 갖는 배열을 의미합니다. 포인터 각각을 배열로 표현한 것이지요.
느낌이 오시나요?
코드와 그림으로 알아보도록 합시다.
#include <stdio.h>
int main() {
int a = 10;
int b = 20;
int c = 30;
int *pArr[3] = { &a,&b,&c };
printf("%d\n", *pArr[0]);
printf("%d\n", *pArr[1]);
printf("%d\n", *pArr[2]);
}
여기, 포인터배열을 간단하게 알아볼 수 있는 코드입니다. pArr은 평소에 보던 배열과는 다르게 앞에 *(pointer)를 볼 수 있지요?
연산자 우선순위에 의하면 배열첨자([])가 포인터(*)연산보다 먼저입니다. 그렇기 때문에 배열 3개가 있고, 그 배열의 원소는 포인터라는 의미가 됩니다.
따라서 배열의 원소인 pArr[0]은 a의 주소를 갖고있고, pArr[1]은 b의 주소를 갖고 있고, pArr[2]는 c의 주소를 갖고 있습니다.
이 코드의 상황을 그림으로 나타냈습니다.
만약 pArr[0]을 찍어보면 a의 주소가 나오게 됩니다. a의 값에 접근하고 싶다면 포인터 연산을 해주면 됩니다. 바로 *pArr[0], 이렇게요.
그렇게 포인터 원소를 배열로 나열했기 때문에 포인터배열이라 부릅니다.
포인터배열로 배열 가리키기
포인터가 배열의 시작주소를 가리킬 수 있다는 것은 이제 잘 알겁니다. 아닌가? 그렇다면 어떤 배열들을 포인터 배열로 가리킬 수도 있다는 느낌이 오시나요?
코드를 통해 느껴봅시다.
#include <stdio.h>
int main() {
int i, j;
int a[5] = { 1,2,3,4,5 };
int b[6] = { 10,20,30,40,50,60 };
int c[7] = { 100,200,300,400,500,600,700 };
int *pArr[3] = { a,b,c };
int sub_len[3] =
{ sizeof(a) / sizeof(int), sizeof(b) / sizeof(int), sizeof(c) / sizeof(int) };
int len = sizeof(pArr) / sizeof(int*);
for (i = 0; i < len; i++) {
for (int j = 0; j < sub_len[i]; j++)
printf("%d ", pArr[i][j]);
printf("\n");
}
}
a,b,c 배열의 길이는 전부 다릅니다. 하지만 문제없지요. 왜냐면 포인터는 배열의 시작주소만 알면 되기 때문입니다.
각각의 포인터들(pArr[0], pArr[1], pArr[2])은 배열의 시작주소 a, b, c를 가리키고 있습니다.
포인터 역시 배열처럼 첨자를 쓸수도 있다는 것을 다들 아실겁니다.
배열포인터
배열포인터는 무엇일까요? 아까 포인터배열은 포인터를 배열로 나열한 것이라고 설명했으니, 배열포인터는 배열을 가리키는 포인터가 아닐까요?
배열포인터는 다음과 같이 정의합니다.
int (*pArr)[3]
앞서 본 포인터배열과는 다르게 괄호가 추가 되었죠. 이 한 끗 차이에 의미가 변하게 됩니다. 우선 포인터이긴한데, 길이 3을 갖는 int형 배열만을 가리킬 수 있다는 점입니다. 우선 다음 기본적인 코드를 봅시다. 우리가 아는 내용입니다.
#include <stdio.h>
int main() {
int i = 0;
int arr[5] = { 1,2,3,4,5 };
int *pArr = arr;
for (i = 0; i < sizeof(arr)/sizeof(int); i++)
printf("%d ", pArr[i]);
printf("\n");
}
r
pArr은 일차원배열 arr의 시작주소를 가리키고 있다는 내용입니다. 그래서 배열처럼 인덱싱을 통하여 각 원소를 출력하고 있지요. arr의 길이 5는 신경쓰지 않습니다. 단지 가리키기만 하고 있습니다.
이제 위의 정의를 다시 봅시다.
int arr[행][열] ={ {...}, {...}, {...}};
int (*pArr)[열]= arr;
(*pArr)은 arr의 가장 높은 차원의 길이 3(행)은 신경쓰지 않습니다. 단지 그 시작주소만 가리키기만 하면 되거든요. 하지만 그 보다 낮은 차원의 길이4(열)는 알아야만 합니다. 그래야만 다음 행을 구해낼 수 있기 때문이죠.
어떻게??
pArr[0]은 4개의 int배열을 가리키고 있는 포인터입니다. 따라서 sizeof(pArr[0])을 찍어보면 그 길이가 16이라는 것을 알 수 있습니다. 그래서 주소를 계산할때 지금 행의 주소에 16을 더해야 다음 행을 구할 수 있습니다. 위 코드에서는 1차원 배열이고 각 원소의 길이는 단순히 1이니까 쓰지 않는 것입니다.
이제 2차원 배열을 배열포인터로 구현해봅시다.
#include <stdio.h>
int main() {
int i,j;
int arr[3][4] = { {1,2,3,4}, {5,6,7,8}, {9,10,11,12} };
int(*pArr)[4] = arr;
int row = sizeof(arr) / sizeof(arr[0]);
int col = sizeof(arr[0]) / sizeof(arr[0][0]);
for (i = 0; i < row; i++) {
for (j = 0; j < col; j++)
printf("%d ", pArr[i][j]);
printf("\n");
}
}
arr의 각 행 길이와 pArr의 행의 길이를 맞추고 있다는 것을 보세요. 그리고 pArr[0:2]는 각각 사이즈가 16이며 마치 배열처럼 동작이 가능합니다.
이것을 어디다가 활용할 수 있을까요??
함수에 전달인자로 배열을 받을때 주로 사용합니다.
#include <stdio.h>
void printArr(int(*pArr)[4],int row,int col) {
int i, j;
for (i = 0; i < row; i++) {
for (j = 0; j < col; j++)
printf("%d ", pArr[i][j]);
printf("\n");
}
}
int main() {
int arr[3][4] = { {1,2,3,4}, {5,6,7,8}, {9,10,11,12}};
int row = sizeof(arr) / sizeof(arr[0]);
int col = sizeof(arr[0]) / sizeof(arr[0][0]);
printArr(arr,row,col);
}
매개변수를 받으려면 위와 같이 전달받고, 배열처럼 인덱싱을 편하게 사용할 수 있습니다.
더 간편한 방법으로는 int (*pArr)[4]를 int pArr[][4]로 바꿔줘도 실행이 가능합니다. 왜냐면 *pArr은 pArr[]과 거의 같은 의미이기 때문입니다.
void printArr(int pArr[][4],int row,int col) {
int i, j;
for (i = 0; i < row; i++) {
for (j = 0; j < col; j++)
printf("%d ", pArr[i][j]);
printf("\n");
}
}
C언어에서 scanf와 printf 함수를 통해서 키보드로 입력을 받고 모니터로 출력해주는 그런 프로그램들을 많이 보았을 겁니다. 이런 키보드나 모니터같은 입출력 장비를 콘솔이라고 합니다. 그래서 콘솔 입출력을 해왔던 것이죠.
여기서는 파일 입출력에 대해서 설명합니다. 사실 콘솔 입출력과는 별로 다를바가 없습니다. 단지 그 대상이 모니터나 키보드가 아닌 파일이기 때문이죠. 본격적으로 파일 입출력을 설명하기 전에 우리는 스트림에 대한 개념을 먼저 알아야합니다.
> 그전에 왜 C 표준입출력을 사용하나요?
리눅스를 배우셨던 분들은 open, read, write, close를 이용해서 파일을 다뤄보셨을 겁니다. 그때는 open에 필요에 따라 여러 플래그들을 줄 수가 있는데요. 예를 들어 O_RDONLY, O_CREAT 등 말이죠. 이거 구차하게 일일히 헤더 추가한 다음에 파일 디스크립터를 가져와서 write, read하는 것을 C 표준입출력 라이브러리에서는 stdio.h만 포함해서 사용할 수 있습니다. 아주 개꿀이라는 얘기죠. 그리고 변태같은 플래그들을 포함하지 않아도 사용하기에 적합한 플래그들을 미리 조합해놨기 때문에 상큼하게 그걸 사용하면 됩니다. 또한 내부적으로 버퍼를 사용하기 때문에 read, write 함수들을 최적으로 사용하게 됩니다.
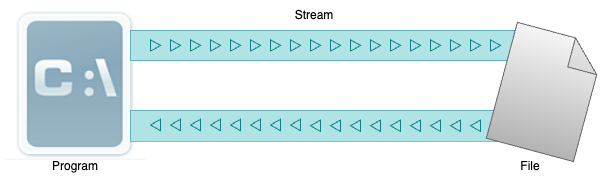
스트림(Stream)
영어를 그대로 직영하게 되면 흐름이라는 건데요. 비슷하게 생각하시면 됩니다. 프로그램에서 파일이 열리면 C표준입출력은 스트림(stream)이라는 파일과 프로그램 사이의 추상적인 흐름이 일어나는 파이프를 생성합니다. 그래서 파일이 열리게 되면 개념적으로 스트림을 통해서 파일에 기록하거나 읽을 수 있습니다. 만약 파일을 읽기만 하겠다하면 읽기 전용의 스트림을 여는 것이고, 파일을 쓰기만 할 것이라면 쓰기 전용의 스트림을 열어서 거기에 기록을 하면 됩니다.
그래서 아래와 같이 어떤 프로그램에서 File이라는 이름의 파일을 읽고 쓰기 위해서 스트림을 열면 아래와 같은 상황이 발생하게 됩니다. 그래서 바이트 단위던, 줄 단위던 입력이 흐름이 가능한 상태가 됩니다.
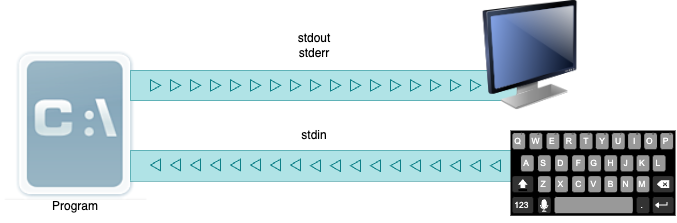
기본적으로 보통 프로그램에서는 3개의 스트림이 열려있습니다. 바로 표준 입력 스트림(stdin), 표준 출력 스트림(stdout), 표준 에러 스트림(stderr)입니다. 이 3개는 콘솔에 대해서 열려있는 스트림들입니다.
stdin, stdout, stderr
키보드로 입력받고, 모니터로 출력하는 것도 C표준 입출력에서는 스트림으로 간주하게 됩니다. 그래서 우리가 stdin을 통해서 입력을 받는다면 키보드를 통해서 입력을 받는 것이고, 표준 출력 스트림으로 출력한다면 모니터 화면에다가 출력이 되는 겁니다. 그래서 파일 대신 모니터와 키보드가 스트림 끝에 놓여있는 것을 보세요.
파일의 종류 ( 텍스트 파일 , 이진 파일)
파일을 사람이 쓰고 읽냐, 컴퓨터가 쓰고 읽냐에 따라서 텍스트 파일(text-file), 이진 파일(binary-file)로 나누게 됩니다. 이와 같은 구분은 문자열로 입출력을 하느냐, 아니면 바이너리로 입출력을 하느냐를 위해서 구분합니다. 맨 처음 파일에 대해서 스트림을 생성할 때 결정이 됩니다.
1. 파일 열기 fopen
파일 함수는 표준입출력(stdio.h) 헤더파일에 존재합니다. 파일에 어떤 데이터를 읽고, 쓰고, 추가하려면 일단 파일을 열어야겠지요. 함수를 한번 보시죠.
filename : 파일명을 말합니다. 절대 경로나 상대 경로로 줄 수 있습니다. 상대 경로는 그 프로젝트 위치를 기준으로 합니다.
mode : 파일을 어떤 방식으로 열건지 정합니다. 스트림 방식을 정하는 겁니다. 입력 스트림인지, 출력 스트림인지.
-동작 모드
모드
설명
flag 조합
r(read)
1. 파일을 읽기 전용으로 엽니다. 2. 파일이 있어야합니다.
O_RDONLY
w(write)
1. 파일을 쓰기 전용으로 엽니다. 2. 주의해야합니다. 파일이 존재한다면 기존의 내용을 지우고 쓰기 때문이죠. 3. 파일이 없으면 새로 생성합니다.
O_WRONLY | O_CREAT | O_TRUNC
a(append)
1. 파일이 있으면 파일의 끝에 내용을 추가합니다. 2. 파일이 없으면 생성해서 내용을 추가합니다.
O_WRONLY | O_CREAT | O_APPEND
r+
1. 파일을 읽고 쓰기 위해 엽니다. 2. 파일이 반드시 있어야 합니다.
O_RDWR
w+
1. 파일을 읽고 쓰려고 엽니다. 2. r+와 다르게 파일이 있는 경우 내용을 덮어쓰고 없으면 생성해서 데이터를 씁니다.
O_RDWR | O_CREAT | O_TRUNC
a+
1. 파일을 읽고 갱신하기 위해 엽니다. 2. 파일이 없으면 생성해서 데이터를 추가합니다.
O_RDWR | O_CREAT | O_APPEND
- 이진 또는 텍스트 모드(t, b)
텍스트모드가 기본(default)입니다. 이진 모드로 파일을 열려면 b를 추가합니다.
ex) 이진모드로 읽기 위해 파일을 open -> rb
파일을 여는 데 성공했다면 그 파일에 대한 포인터를 return합니다.
하지만 파일을 여는 데 실패했으면 NULL을 반환하죠.
2. 파일 닫기 fclose
무엇이든 열었으면 닫는 것이 원칙이죠. 파일 스트림을 닫으려면 fclose를 사용하시면 됩니다.
int fclose(FILE *stream);
그냥 열었던 파일 포인터를 집어넣으면 됩니다. 성공하면 0을 반환하고 실패하면 EOF(-1)를 반환합니다.
3. 텍스트 파일 읽기 함수
파일은 두 종류의 파일이 있다고 했죠? 사람이 읽을 수 있는 텍스트 형식의 파일과 컴퓨터가 읽고 처리하는 바이너리 파일, 즉 이진 파일이 있습니다. 우선 텍스트 파일을 읽는 함수는 쓰임새에 따라 여러가지가 있습니다.
3.1 한문자 읽기 : fgetc, getc, getchar
#include <stdio.h>
int fgetc(FILE *stream);
int getc(FILE *stream);
int getchar(void);
fgetc와 getc는 같은 기능을 하는 함수입니다. getchar() 함수는 키보드용 한문자 입력을 받는 함수와 같아서 getc(stdin)과 같습니다.
getc = getc , getc(stdin) = getchar()
stream에서 한 글자를 읽어오는 함수이며, 일반적으로 반환형은 한 글자의 ASCII값인 정수형 값입니다. 파일의 끝에 도달할 시에 EOF를 return합니다. EOF는 End-Of-File로 -1입니다. 이렇게 반환형이 (signed) int인 이유는 이 EOF를 반환받기 위해서입니다.
3.2 한 줄 읽기 : fgets
#include <stdio.h>
char *fgets(char *s, int size, FILE *stream);
stream에서 문자 한줄을 읽어올때 사용하는 함수이며 size 이하의 문자 한줄을 s로 읽어옵니다. 이때 개행문자까지 읽어옵니다. 그래서 개행문자('\n') 다음 문자의 끝을 나타내는 문자인 NULL('\0')이 붙습니다. 간단히 사용법을 확인해볼까요? 다음은 stdin으로 콘솔(키보드)로부터 입력을 받는 단순한 예제입니다.
buffer에 담긴 내용을 기록하는데 size만큼의 count 만큼 버퍼로부터 stream쪽으로 씁니다. 성공하면 count를 return하고 실패한다면 count가 아닐 수 있습니다.
예제 - 이진데이터 구조체 저장, 읽어오기
이진 파일을 사용할 수 있는 가장 큰 장점은 모든 자료를 이진데이터로 쓸 수 있다는 점입니다. 객체(구조체)도 그냉 냅다 쓸 수 있습니다. 모든 것을 이진 데이터로 쓰기 때문이지요. 다음은 구조체를 파일에 쓰고, 그 파일로부터 읽어오는 예제를 보여줍니다.
//info_writer.c
#include <stdio.h>
#define NUM 3
typedef struct _student{
char name[16]; //이름
unsigned int age; //나이
unsigned int id; //학번
} student;
int main(){
FILE *fp;
student s[NUM] = {
{"kim", 16, 1234},
{"lee", 16, 1235},
{"lim", 17, 1111}
};
//이진(b)으로 쓰기용, 없으면 만들고 있으면 덮어쓴다(w+)
fp = fopen("info.bin", "wb+");
if(fp == NULL){
printf("fopen error\n");
return 1;
}
if(fwrite(s, sizeof(student), NUM, fp) != NUM){
printf("fwrite erorr\n");
fclose(fp);
return 1;
}
printf("Student Information Saved OK \n");
fclose(fp);
}
//info_reader.c
#include <stdio.h>
#define NUM 3
typedef struct _student{
char name[16]; //이름
unsigned int age; //나이
unsigned int id; //학번
} student;
int main(){
int i;
FILE *fp;
student s[NUM];
fp = fopen("info.bin", "rb"); //읽기 전용
if(fp == NULL){
printf("fopen error\n");
return 1;
}
if(fread(s, sizeof(student), NUM, fp) != NUM){
printf("fread erorr\n");
fclose(fp);
return 1;
}
for(i = 0; i < NUM; i++){
printf("[%d]\n", i);
printf("name : %s, age : %u, id : %u\n",
s[i].name, s[i].age, s[i].id);
}
fclose(fp);
}
# gcc info_writer.c -o writer
# gcc info_reader.c -o reader
# ./writer
Student Information Saved OK
# ./reader
[0]
name : kim, age : 16, id : 1234
[1]
name : lee, age : 16, id : 1235
[2]
name : lim, age : 17, id : 1111
7. 버퍼
버퍼는 C표준입출력에서 입력과 출력을 효율적으로 처리하기 위한 일종의 저장공간입니다. 내부적으로 write, read를 적시에 한번만 호출하기 위한 것이 목적입니다. 그런데 이러한 버퍼의 처리 방식을 잘 모르면 낭패를 볼 수 있는데요. 아래의 코드를 봅시다.
//buffer.c
#include <stdio.h>
int main(){
char c;
printf("아무 글자나 하나 입력:");
scanf("%c", &c);
printf("입력받은 글자 : %c\n", c);
printf("다시 입력 : ");
scanf("%c", &c);
printf("입력받은 글자 : %c\n", c);
}
실행하게 되면 두 번재 scanf에 입력을 주기도 전에 프로그램이 끝나게 됩니다. 분명 scanf를 통해서 한글자 입력을 받는 코드를 작성했으에도 말이죠.
# ./a.out
아무 글자나 하나 입력:H
입력받은 글자 : H
다시 입력 : 입력받은 글자 :
#
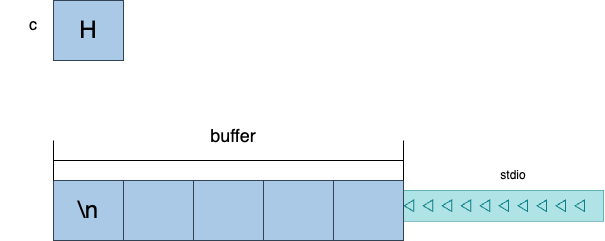
이 프로그램은 내부적으로 이렇게 동작하게 됩니다. 'H'라는 문자를 입력하면 내부적으로 엔터에 해당하는 개행 문자 '\n'도 입력이 됩니다.
결국 버퍼에는 H와 '\n'이 입력이 되게 되며 변수 c에는 'H'가 담기게 되겠죠. 버퍼에 남아있는 건 개행문자 '\n'입니다. 그래서 다음 scanf는 이 개행문자를 입력받아 입력이 끝나게 되는 겁니다.
위는 줄 단위 버퍼링의 사례로 결국에는 남아있는 버퍼를 비워줘야합니다. 버퍼를 비워주는 방법에는 여러 가지 방법이 있는데요.
7.1 버퍼를 비우는 방법들
- 간단한 방법은 단순히 문자 하나 입력받는 거죠. 아래와 같이말이죠.
printf("아무 글자나 하나 입력:");
scanf("%c", &c);
getchar();
printf("입력받은 글자 : %c\n", c);
printf("다시 입력 : ");
scanf("%c", &c);
getchar();
printf("입력받은 글자 : %c\n", c);
- fflush 함수 사용
#include <stdio.h>
int fflush(FILE *stream);
fflush 함수를 사용할 수가 있는데, 이 방법은 표준이 아니므로 권장되지 않습니다. 실제 제 ubuntu시스템에서는 동작하지 않습니다.
- scanf에서 공백 사용
scanf("%c", &c) -> scanf(" %c", &c)
앞에 공백 문자 하나를 넣어주세요.
- 개행문자가 나올때까지 제거
while(getchar() != '\n');
어떤 시스템에는 \r\n으로 개행합니다. 그게 윈도우즈인데, 이럴 때는 getchar()만 사용하게 되면 \r만 제거 됩니다. 그래서 아예 \n까지 제거 할 수 있도록 while문을 도는 방식을 사용할 수 있습니다. 약간 고급진 말로 '\r'은 커서를 맨 앞으로 돌리는 CR(Carriage return)이라 하며 '\n'은 커서는 그자리이며 라인만 바꾸는 LF(Line Feed)라고 합니다.
큐에서 하나 꺼내는 연산인데요. 어디서 꺼내느냐. front가 가리키는 노드를 꺼내면 됩니다. 아참, 그전에 큐가 비어있는지 확인하는게 먼저겠죠. 큐에 내용이 있다면 front노드의 데이터를 하나 꺼내고, 임의로 node라는 포인터를 써 front가 가리키는 노드를 같이 가리키게 합니다. 그 이후 front->next로 front를 다음 노드로 가리킵니다. 그리고 메모리를 해제하면 됩니다.
큐에서 데이터가 삭제됐으니 길이는 줄겠죠?
int dequeue() {
if (isEmpty()) {
cout << "Q is empty" << endl;
return INF;
}
Node *delNode = front;
int ret = delNode->data;
front = delNode->next;
free(delNode);
len--;
return ret;
}
전체코드
이제 전체코드를 보도록 해요. 메인에서는 큐에 1부터 5까지 삽입하고 다시 10을 삽입합니다. 결과는 어떻게 될까요?
#include <iostream>
#define INF 987654321
using namespace std;
struct Node {
int data;
Node *next;
};
struct LinkedQueue {
Node *front, *rear;
int len = 0;
LinkedQueue() {
front = rear = NULL;
}
int size() {
return len;
}
bool isEmpty() {
return len ==0;
}
void enqueue(int data) {
Node *node = (Node*)malloc(sizeof(Node));
node->data = data;
node->next = NULL;
if (isEmpty()) {
front = rear = node;
}
else {
rear->next = node;
rear = rear->next;
}
len++;
}
int dequeue() {
if (isEmpty()) {
cout << "Q is empty" << endl;
return INF;
}
Node *delNode = front;
int ret = delNode->data;
front = delNode->next;
free(delNode);
len--;
return ret;
}
};
int main() {
LinkedQueue q;
for (int i = 1; i <= 5; i++)
q.enqueue(i);
q.enqueue(10);
while (!q.isEmpty())
cout << q.dequeue() << endl;
}
원하는 대로 결과가 나왔나요?
여기까지 큐를 링크드리스트로 구현하는 방법을 알아보았습니다. 링크드리스트로 구현한 큐이든, 선형큐이든 항상 무슨 프로그램을 구현할 것인지 고려하여 쓰기 바랍니다.
스택과 양대산맥인 큐는 스택과 반대의 성격을 지닌 녀석입니다. 스택이 후입선출(Last In First Out)방식이었다면 큐는 선입선출(First In First Out)방식이 되지요. 스택과 큐는 컴퓨터 과학에서 아주 중요한 도구들입니다. 스택의 개념과 사용처는 지난 포스팅에서 했으니, 큐에 대해서만 설명해보도록 하겠습니다.
큐는 개념은 정말 쉽습니다. 첫번째로 들어오는 녀석을 가장 먼저 내보내는 것이 큐입니다. 현실 세계에서도 역시 큐에 개념이 사용됩니다. 버스 기다릴때나 은행 업무를 기다릴때, 가장 먼저 도착한 사람이 버스를 타거나 은행업무를 보게 되지요. 새치기하지마라 진짜
'
위의 그림 처럼 말이죠. 그냥 쭉 줄서있죠? 이런 큐를 선형큐라고 합니다.
그림에서는 보이진 않지만 가장 앞에 있는 원소를 Front, 그리고 가장 뒤에 있는 원소를 Rear라고 합니다.
큐에는 기본적으로 두 가지의 연산이 있습니다. 바로 enqueue와 dequeue입니다.
enqueue 큐에 데이터를 삽입합니다.
dequeue 큐에서 데이터를 꺼내옵니다.
선형큐는 구현하는 게 매우 간단하지만( 단지 배열로 일직선으로 구현) 치명적인 약점이 있는데요.
1) 큐에 데이터가 꽉 찼다면 데이터를 더 추가할 수 없습니다(물론 큐 사이즈를 늘리고 원소를 다시 복사하면 됩니다. 근데 시간이 안습이죠.).
2)공간의 효율성을 고려해야합니다. 배열로 단순히 구현하면 front가 뒤로 계속 밀려 앞의 공간이 남게 되죠. 그러니까 하나의 원소가 빠져나가면 그 다음부터 모든 녀석들을 앞으로 당겨와야하니까 속도 측면에서 상당히 느립니다. 작은 데이터들이라면 물론 상관없지만, 요즘처럼 사이즈가 크고 많은 데이터를 처리하기에는 무리죠.
사용하기에는 단점이 좀 아프니까 선형큐는 개념 정도만 알고 가겠습니다.
원형큐(Circular Queue)
선형큐의 단점을 보완할 수 있는 큐로는 바로 원형큐가 있습니다. 큐를 직선 형태로 놓는 것 보다 원형으로 생각해서 큐를 구현하는 것이죠. 큐를 원형으로 생각해야되기 때문에 모듈러 연산(나머지 연산)을 해야합니다.
그림으로 설명해보도록 하지요.
우선 큐의 시작점은 어느 점이라도 됩니다. 그냥 단순히 보기 위해서 가장 아래에 있는 점을 시작 점이라고 정의해보겠습니다.
그리고 색이 칠해져있는 부분이 노드가 삽입된 상태입니다.
또한, front가 노드를 가리키고 있지 않고 그 전의 점을 가리키고 있는 이유는 우선 증가 연산 후에 데이터를 꺼내오기 때문입니다.
우리는 아래 구조체를 코딩을 통해서 큐를 구현할 겁니다. SIZE는 원형큐의 SIZE를 의미합니다. 그리고 front와 rear가 배열의 마지막 원소로 지정한 것은 배열 인덱스 0부터 시작하려고 하기 때문입니다(선증가 후 원소를 삽입한다는 사실만 지금은 기억하기 바랍니다.). 뭐 front와 rear를 0으로 하건 1로하건 상관없습니다.
struct cirQueue {
int arr[SIZE];
int front, rear;
cirQueue() {
front = SIZE-1;
rear = SIZE-1;
}
};
cirQueue()는 front와 rear의 초기값을 지정합니다. 이렇게 하고 싶지 않다면 변수를 선언할때 일반적인 구조체를 다루듯이
cirQueue q;
q.front=q.rear=SIZE-1;
이런식으로 코딩하면 됩니다.
우리는 이제 4가지의 연산을 정의할 건데요. 잘 따라오세요.
1. isEmpty
큐가 비어있냐 아니냐를 질의하는 연산입니다. 처음 큐의 rear와 front는 같은 자리에 위치하게 됩니다. 그러니 rear와 front는 당연히 같은 값이 되지요. 그리고 큐가 삽입되고 꺼내어지고 할 때 역시 큐가 비어있게 된다면 rear와 front는 역시 같은 값이 됩니다. front를 하나 증가하고 난 이후에 데이터를 꺼내오니까요.
코드도 역시 간단하게 구현이 되는 군요.
bool isEmpty() {
return rear == front;
}
2. isFull
큐에 데이터가 꽉차있는 상태인지 알아보는 연산입니다. rear를 하나 증가시키고 데이터를 넣으려보니까 그 자리에는 front라는 것이 자리잡고 있는 겁니다.
여기서 중요한 사실은 큐에서 1개는 쓸 수 없다는 사실입니다. rear+1자리에 front가 있는 지 알아보기 위해서지요.
여기서 큐의 SIZE로 나누는 이유는 계속 rear+1이 큐의 SIZE보다 클 수 있다는 겁니다. rear가 SIZE-1의 원소(배열의 마지막 원소)를 가리키고 있고 다음 rear+1은 SIZE가 아니라 0이 되어야합니다. 그래야 원형큐가 되니까요.
아참! 간간히 눈에 보이지 않는 오류가 있는데 수식을 잘 보셔야됩니다. 덧셈보다 모듈러 연산의 우선순위가 더 높기 때문에 (rear +1 % SIZE) == font 를 하게 되면 1%SIZE 부터 계산하게 됩니다. 우리가 원하는 것은 rear를 먼저 1증가시킨 후 SIZE로 나눈 나머지를 구하는 것이니 괄호를 처리해야 합니다.
( (rear + 1) % SIZE ) == front 로요.
3. enqueue
큐에 원소를 삽입하는 연산입니다. 우선 큐가 꽉차있는 상태인지 아닌지 부터 알아봅니다. 삽입하기 충분한 공간이 있다면 현재 rear에서 1을 증가시킵니다 다음 원소에 추가시키기 위해서요. 그자리에 원소를 삽입하면 됩니다.
여기서도 역시 나머지 연산이 들어갑니다. 원형큐이기 때문에 SIZE보다 크면 다시 처음부터 원소가 삽입되어야 하기 때문입니다.
우리는 이제까지 객체나 클래스의 변수나 메소드를 직접 접근하는 프로그래밍을 해왔습니다. 우리가 저질렀던 이런 방법의 프로그래밍은 조금 위험하다는 것을 알아야합니다.
왜요?
모두가 접근 가능한 변수나 메소드는 제약 조건없이 쉽게 데이터가 변경 가능하기 때문입니다.
우리는 이 데이터가 안전하게 변경되기 위해서 포장, 또는 알맹이처럼 쌓아야하는 의무가 있습니다. 그게바로 객체지향에서 말하는 캡슐화라고 하는 것이죠.
어떻게 캡슐화가 이루어지는 지 상황을 통해서 알아보도록 합시다.
우리는 계좌의 5만원의 잔액을 갖고 있는 클래스 BankAccount가 있다고 칩시다. 간단하게 정의해보겠습니다.
class BankAccount{
int balance=50000;
}
우리는 이 클래스의 객체로부터 인출하는 동작을 하고 싶다는 것입니다.
그럴때 외부에서 직접적으로 balance 변수에 접근하게 된다면 balance가 음수가 될 수도 있다는 겁니다. 인출은 절대 음수가 될 수 없다는 원칙을 깨고 원치않는 프로그램의 오류가 생기게 됩니다. 실제 이렇게 된다면 피해가 막심할 것입니다.
그러니, 우리는 데이터를 제어해야합니다.
우선 balance라는 변수는 그 클래스 외부에서 절대 접근을 불가하게 만들고 알맞은 로직을 갖고 있는 멤버함수를 두어, 그 balance를 변경하게 만들면 되지 않을까요??
접근 제어자가 우리의 작은 소망을 들어 줄 수 있습니다.
접근지정자
그 전에 우리는 접근 지정자, 또는 접근 제한자라고 하는 녀석들부터 알아야합니다.
자바의 접근 지정자에는 4개가 있습니다. public, protected, default, private라는 녀석들이지요. 이 4개의 접근 지정자들은 멤버 변수나 멤버 메소드를 어떤 범위 내에서 접근하게 허락할 것인지를 정의하게 해줍니다.
다음의 표와 그림이 범위를 보여주고 있습니다.
접근 지정자
오직 클래스
같은 패키지
자식 클래스
외부 어디서나
public
O
O
O
O
protected
O
O
O
default
O
O
private
O
public > protected > default > private 순으로 범위가 점점 좁아지는 것을 알 수 있습니다.
이 접근 제어자를 통해서 위의 코드의 문제점을 잡아보도록 하지요.
class BankAccount{
private int balance=50000;
public int withdraw(int m){
if(balance<m)
return 0;
balance-=m;
return m;
}
}
변수는 private로 지정해서 BankAccount내에서만 제어가 가능하게 만들어 줍니다.
그리고 메소드를 통해서 m만큼의 돈을 인출하는 withdraw를 정의하는 겁니다. public 지정자로 withdraw메소드를 정의했으니, 누가나 withdraw를 호출할 수 있습니다. 또한, withdraw메소드는 BankAccount 멤버이기 때문에 balance라는 변수에 접근이 가능하며 이 메소드에서 제어를 하고 있습니다. 만일 인출하려는 금액 m이 지금 잔액(balance)보다 크다고 하면 0을 반환하는 것입니다. 그 외에는 그 금액을 인출하는 것이죠. 물론 잔액은 줄어들게 됩니다.
이렇게 원치않는 변경을 막기 위해 접근 지정자를 쓰게 된다면 balance를 보호할 수가 있습니다.
캡슐화가 이해되셨나요?
상속 관계만 데이터 접근 protected
우리는 상속관계에서 부모클래스의 데이터나 메소드를 자식 클래스만 접근을 허락해야 할 때도 있습니다. 이때 사용하는 지정자가 protected입니다.
example이라는 패키지에 두개의 클래스를 A, A를 상속받은 클래스 B를 정의합니다.
package example;
public class A{
protected int a;
public A(){}
}
package example;
public class B extends A{
public B(){
a=30;
}
}
B는 A를 상속했으니 a에 대한 변수에 접근이 가능합니다.
같은 패키지의 main함수와 다른 패키지의 main에서 실험해보세요. 같은 패키지에서는 a에 접근이 가능하고, 다른 패키지에는 아래 그림에서 처럼 a가 proposals조차에서도 보이지 않습니다.
왜냐면 protected지정자로 지정된 변수나 메소드는 같은 패키지에서 모두 접근이 가능하기 때문이지요.
우리는 다른 패키지에 있는 클래스 역시 상속을 할 수 있기 때문에 상속관계에서만 데이터 접근을 허락할 때는 protected 접근 지정자를 사용해야합니다.
우리는 이제부토 상속이란 클래스 관점으로 보면 됩니다. 클래스에는 변수와 메소드가 있죠. 클래스 입장에서는 이것이 재산이라고 생각하면 됩니다. 그래서 자식이 되는 클래스는 이런 재산을 코드의 추가없이 그대로 사용하거나, 변경해서 사용할 수 있습니다.
여기서 왜 우리는 상속을 해야하는 지 알 수 있습니다. 바로 코드의 재사용성을 더욱 확대하는 것이지요. 그렇다면 그냥 복사, 붙여넣기를 하면 되는 것이 아닌가? 라고 생각할 수도 있지만, 코드의 변경 역시 신경써야합니다. 그리고 관리도 복잡하게 되구요.
가장 중요한 것은 상속을 통해서 다형성을 만족시킬 수 있다는 점입니다. 이 부분에 대해서는 이 다음에 알아보도록 하지요.
extends
상속을 하는 방법 아래와 같습니다.
class 자식클래스 extends 부모클래스
어떤 클래스를 정의함과 동시에 extends 예약어로 다른 클래스를 포함하게 된다면 extends 이후에 나오는 클래스를 상속하게 되는 것입니다.
어떤 클래스는 자동적으로 Object클래스를 상속했다고 했는데, 그럼 이런 형태일까요?
class 자식클래스 extends 부모클래스 extends Object
아닙니다. 자바에서는 클래스의 다중상속(여러 부모클래스를 두는 것)을 허용하지 않습니다. 이런 경우에는 이미 부모클래스가 Object클래스를 이미 상속받고 있기 때문에 자식클래스는 부모클래스를 상속받음으로써 Object클래스의 메소드를 사용할 수 있는 것입니다.
이렇게 되는 것이죠.
class 부모클래스 extends Object { ... }
class 자식클래스 extends 부모클래스 { ... }
코드를 통해 알아보자.
이쯤되면 코드를 볼 타이밍이겠군요.
class Parent{
int age=45;
String name="Parent";
public Parent(){
System.out.println("Parent Default Constructor");
}
public Parent(int _age,String _name){
age=_age;
name=_name;
System.out.println("Parent Constructor");
}
public void showInfo(){
System.out.println("Name:"+name+", age:"+age);
}
}
class Child extends Parent{
public Child(int _age, String _name){
System.out.println("Child Constructor");
}
}
public class Main {
public static void main(String[] args){
Child a=new Child(25,"REAKWON");
a.showInfo();
}
}
우선 Child 클래스는 Parent 클래스를 상속받고 있군요.
코드에 대해서 간단하게 요약하면 Parent 클래스는 아래와 같은 특징이 있군요.
- Default 생성자를 갖고 있다.
- 매개변수를 갖는 생성자도 있다.
- showInfo라는 메소드가 있다.
Child클래스는 그저 매개변수를 받는 생성자가 다에요.
main메소드에서는 Child 객체를 초기화값을 넣어 생성자를 호출합니다. 어떤 결과가 나올까요? 결과를 봅시다.
Parent Default Constructor
Child Constructor
Name:Parent, age:45
어? 부모클래스의 생성자를 우선 호출하는 군요. Default 생성자를 호출하네요.
아아, 우리가 아무 클래스를 상속하게 된다면 부모클래스의 디폴트 생성자를 우선 호출하는 군요.
그리고 우리는 Child클래스에서 showInfo라는 메소드를 만들지 않았음에도 불구하고 main함수에서는 사용하고 있습니다. Parent 클래스를 상속 했기 때문이죠.
근데 좀 부족해요. 뭔가 2%만족이 되지 않는군요.
Child a=new Child(25,"REAKWON");
우리는 생성자를 통해서 age와 name을 바꾸고 싶다는 거죠. 어떻게 해야될까요?
super, this
우리는 위의 코드를 조금 변경해서 age와 name 변수의 데이터를 바꿀 수 있습니다. 바로 부모클래스의 데이터를 직접 변경하는 것이죠.
class Child extends Parent{
public Child(int _age, String _name){
age=_age;
name=_name;
System.out.println("Child Constructor");
}
}
우리는 이미 Parent클래스를 상속받은 상태입니다. 그렇기 때문에 Parent클래스의 변수를 접근할 수도 있습니다(물론 부모클래스가 허용한다면).
그런데 우리는 이미 정의된 부모 클래스의 생성자를 다시 활용해보고 싶습니다.
자식클래스에서 부모클래스를 super클래스라고 부릅니다. 그렇기 때문에 부모클래스의 변수나 메소드, 생성자에 접근할땐 super라는 키워드를 사용합니다.
class Child extends Parent{
public Child(int _age, String _name){
super(_age,_name);
System.out.println("Child Constructor");
}
}
이런식으로 부모클래스의 생성자(super( args))를 호출함으로써 구현해낼 수도 있습니다.
super. 을 눌러 어떤 변수와 메소드들이 있는지 확인해보세요. 부모클래스가 허락한다면 super클래스의 변수와 메소드를 직접 사용할 수도 있습니다.
이제 코드를 조금 더 변형시켜보도록 해서 실험해 봅시다.
class Child extends Parent{
public Child(int age, String name){
age=age;
name=name;
System.out.println("Child Constructor");
}
}
이제 매개변수와 클래스 멤버 변수의 이름이 같습니다. 이런 경우에는 어떤 일이 벌어질까요?
결론은 클래스의 멤버 변수는 변하지 않습니다. 메소드가 호출할때는 매개변수나 그 안의 지역변수가 항상 우선순위를 갖기 때문입니다.
클래스에서 자기 자신을 가리킬 때는 this라는 키워드를 사용합니다. 그렇기 때문에 이런 코딩을 해야합니다.
class Child extends Parent{
public Child(int age, String name){
this.age=age;
this.name=name;
System.out.println("Child Constructor");
}
}
this.age는 자기 자신의 변수 age를 명시적으로 나타냅니다. 어? 우리는 Child에는 age와 name이라는 변수가 없는데요?
아까 말했다시피 상속을 받았기 때문에 슈퍼클래스의 변수도 이제 Child 클래스의 것입니다. 그래서 super.age이건 this.age이건 age접근하는 것은 결론적으로 같습니다.
생성자는 어떨까요?
생성자 역시 다르지 않습니다.
this(args)를 통해서 자기 자신의 생성자를 호출 할 수 있습니다.
class Child extends Parent{
public Child(){
System.out.println("Child Default Constructor");
}
public Child(int age, String name){
this();
this.age=age;
this.name=name;
System.out.println("Child Constructor");
}
}
this()를 보세요. 자신의 Default 생성자를 호출하고 있습니다.
다만, 한가지 주의해야할 점은 자기 자신의 생성자나 슈퍼클래스의 생성자를 다른 생성자 메소드에서 호출해야 될 때에는 호출할 생성자 메소드의 최상위에 코딩을 해야합니다.
overriding
우리는 슈퍼클래스의 메소드를 우리 나름대로 다시 정의해보고 싶습니다. 그것도 역시 가능합니다.
우리는 부모가 정의한 메소드를 우리 입맛에 맞게 바꾸는 것을 Overriding이라고 합니다.
코드와 함께 보도록 합시다.
class Parent{
int age=45;
String name="Parent";
public Parent(){
System.out.println("Parent Default Constructor");
}
public Parent(int _age,String _name){
age=_age;
name=_name;
System.out.println("Parent Constructor");
}
public void showInfo(){
System.out.println("Name:"+name+", age:"+age);
}
}
class Child extends Parent{
public Child(){}
public Child(int _age, String _name){
super(_age,_name);
System.out.println("Child Constructor");
}
@Override
public void showInfo(){
System.out.println("Child showInfo");
super.showInfo();
}
}
public class Main {
public static void main(String[] args){
Child a=new Child(25,"REAKWON");
a.showInfo();
}
}
Child클래스의 showInfo()를 보세요. 부모 클래스의 메소드를 오버라이딩한다는 것을 알리기 위해 @Override annotation으로 명시하고 있습니다. @Overriding이라는 annotation을 써주지 않아도 오류는 없지만, 우리는 컴파일러에게 부모클래스의 메소드를 오버라이딩한다는 것을 알려주어 원치않는 코딩(오타)을 막을 수 있습니다.
또한 Child클래스의 showInfo()는 super클래스의 showInfo() 역시 호출하며 코드를 줄이고 있습니다.
class라는 키워드로 Human이라는 클래스를 정의하고 있습니다. 클래스 안에는 데이터가 있고, 이 데이터들을 활용하여 행동을 정의하고 있습니다. 하지만 이렇게 클래스를 정의했다고 해서 바로 써먹을 수 있는 것은 아닙니다.
객체생성
자바에서는 모든 데이터를 객체로 취급합니다. 클래스를 정의한 이후에 클래스를 통해서 객체를 생성해야합니다. 객체를 생성하는 방법은 new라는 키워드로 메모리에 할당을 해야하는데요. 간단합니다.
Human human=new Human();
클래스를 통해서 메모리에 생성을 했습니다. 이제 human이라는 객체!가 생성이 된것이죠.
C++을 배웠다면 new라는 키워드가 익숙할 겁니다. 네, C++에서의 new와 거의 동일한 역할을 합니다. 하지만 우리는 객체를 쓰고 닫을때 C++에서와 같이 메모리를 해제하지 않아도 됩니다. 왜냐하면 Garbage Collector가 알아서 메모리를 해제해 주거든요. C++에 대해 배우지 않았어도 상관없습니다.
우리는 앞서 클래스를 정의할때 메소드 들을 정의했었습니다. 그렇기 때문에 이 메소드들을 사용할 수 있는 것입니다. 물론 그 객체의 변수들도 바꾸어 줄 수 있습니다.
아래처럼요.
public class Main {
public static void main(String[] args){
Human human=new Human();
human.eyes="쌍꺼풀 수술한 눈";
human.useEyes();
human.useEars();
human.useNose();
}
}
물론 데이터가 바뀌었으니, 메소드의 연산도 바뀔 수 있습니다.
생성자
우리는 new라는 키워드를 통해서 객체를 생성할 때
Human human=new Human();
라는 표현으로 객체를 생성했습니다. 하지만 눈 여겨 보면 괄호가 있는 것을 확인 할 수 있지요.
분명 괄호를 쓰는 이유가 있을 겁니다. 메소드처럼 그 안에 데이터를 매개변수로 전달하거나 하는 이유가 있지 않을까요?
우리는 클래스로부터 객체를 생성할때 초기 데이터를 전달해줄 수 있습니다. 그것이 바로 생성자라고 합니다.
생성자는 객체가 생성될때 가장 처음 호출하는 메소드라고 보면 됩니다. 이 생성자는 꼭 호출이 됩니다. 그리고 객체가 생성되지요. 하지만 우리는 생성자를 선언하지 않았습니다. 하지만 객체를 만들 수는 있었죠.
왜 일까요? 우리가 명시적으로 생성자를 선언하지 않아도 자동으로 default 생성자를 알아서 자바가 정의해줍니다. 물론 아무 기능을 하지 않는 생성자로요.
생성자의 정의는 일반 메소드를 정의하는 것과 같지만
1. 반환값이 없습니다.
2. 생성자의 이름은 클래스의 이름과 정확히 같아야합니다.
3. 생성자는 매개변수에 따라 여러개가 정의 될 수 있습니다.
4. public이라는 접근제어자여야 합니다.
위의 Human은 아무 매개변수가 없는 Default 생성자가 자동으로 호출이 된 것입니다.
아래 코드는 생성자를 통해서 객체를 초기화 시키는 방법을 보여줍니다.
class Human{
String eyes="눈";
String ears="귀";
String nose="코";
String mouth="입";
public Human(){
//default 생성자
}
public Human(String _eyes, String _ears, String _nose, String _mouth){
eyes=_eyes;
ears=_ears;
nose=_nose;
mouth=_mouth;
}
public void useEyes(){
System.out.println(eyes+"으로 봄");
}
public void useEars(){
System.out.println(ears+"로 소리를 들음");
}
public void useNose(){
System.out.println(nose+"로 냄새를 맡음");
}
public void useMouth(){
System.out.println(mouth+"로 욕을 함");
}
}
public class Main {
public static void main(String[] args){
Human human=new Human("라식한 눈","귀","코털 삐져나온 코","험악한 입");
human.useEars();
human.useEyes();
human.useMouth();
human.useNose();
}
}
위에서 생성자를 정의한 규칙대로 생성자를 정의해주었습니다. 그리고 default 생성자를 명시적으로 정의해주었습니다.
우리는 단지 위 4개의 메소드만을 정의했습니다. 하지만 우리가 정의하지 않은 메소드들도 리스트에 나옵니다. 우리는 분명이 아래와 같은 hashCode, notify, wait 과 같은 메소드들은 정의하지 않았습니다. 이것들은 무엇일까요? 우리는 이 정체를 밝혀내기 위해서 우선 Object 클래스를 알아야합니다.
사실 위의 메소드들은 Object클래스의 메소드들입니다. 위의 메소드들이 Object클래스에 그대로 존재하고 있다는 것을 확인하고 있지요.
허나 왜 Object클래스의 메소드가 왜 내가 만든 클래스에 딸려 나오는 것이냐?
모든 클래스는 Object클래스를 자동으로 상속받게 됩니다.
상속(Inheritance)?
아직 이야기하지는 않았습니다. 간단히 말해서 어떤 클래스의 변수와 메소드들을 물려받는다고 지금은 그렇게 이해하시기 바랍니다. 상속을 쓰게 되면 코드의 재활용이나 유지보수가 더욱 더 쉬워집니다. 상속을 사용하는 방법은 클래스를 정의하기 전 중괄호( { )에서 extends 클래스명 을 통해 이루어 집니다.
그렇기 때문에 extends Object를 명시해주지 않아도, 우리는 Object클래스의 메소드를 사용할 수 있는 겁니다.
모든 클래스입니다. 모든 클래스는 Object 클래스를 상속받는다는 것을 기억하세요.
아직은 Object 클래스의 메소드들을 일일이 설명하는 것은 좀 오바인것 같습니다.
포스팅을 하면서 중간중간에 설명하는 것으로 하거나, 정 궁금하다면 자바 Doc를 보아주세요.
자료구조에서 스택은 어떤 자료구조일까요? 스택은 영어 단어 자체에서 힌트를 얻을 수 있습니다.
stack
1. (보통 깔끔하게 정돈된) 무더기 2. 많음, 다량 3. (특히 공장의 높은) 굴뚝
1. 쌓다
stack은 쌓다, 무더기 이런 의미로 쓰이죠.
이 의미가 자료구조에 그대로 반영이 됩니다.
우리는 어떤 물건을 쌓는다면 가장 먼저 쌓은 물건은 아래에 깔리고 가장 최근 쌓은 물건은 위에 쌓이게 되지요.
꺼낼때는 어떨까요?
나중에 쌓은 물건을 먼저 꺼내겠죠?
이처럼 나중에 쌓은 것이 먼저 나오고 먼저 쌓은 물건은 더 나중에 나온다 라는 개념이 LIFO(Last In First Out)이라고 합니다. 그와 반대, 먼저 들어온 것이 먼저 나간다의 개념은 FIFO(First In First Out)라고 합니다.
종류
스택은 두 가지 정도의 종류가 존재합니다.
● 배열형태의 스택
● 연결리스트 형태의 스택
두 형태는 스택을 구현하는 기능은 같더라도 효율성에서 다릅니다.
배열형 스택은 우선 접근 속도가 빠릅니다. 하지만 다시 크기를 확장하거나 줄일때 효율성이 떨어지게 되죠. 생각해보세요. 스택 크기가 10인 스택이 데이터를 더 저장하기 위해 스택의 길이를 늘리게 되면 우선 배열의 크기를 다시 할당하고 난 후에 값을 복사해야합니다. 길이가 10인 스택이라 그렇지 크기가 크면 클 수록 성능이 저하되는 것을 알 수 있습니다.
그리고 사용자가 얼마만큼의 스택 크기가 필요한지 예측을 할 수도 없습니다.
반면 연결리스트형 스택은 가변적으로 스택의 크기를 줄였다 늘였다 할 수 있습니다. 반면 값에 접근하려면 그 효율성이 떨어지게 됩니다. 연결리스트 형 스택을 구현하려면 linked list 자료구조를 우선 알아야합니다.
스택의 사용처
스택은 함수의 호출 뿐만 아니라 수식에서도 사용되며 사용처는 많습니다. 우리가 즐겨쓰는 인터넷의 뒤로가기 역시 스택 자료구조가 쓰이게 됩니다. 심지어 미로를 찾는데에도 스택을 쓸 수 있습니다.
구현
기본적으로 스택은 여러 언어에서 표준 라이브러리로 제공이 되긴 합니다만 어떻게 구현이 되어있는지 정도는 이해하고 있어야합니다.
아래의 코드는 배열형 스택을 c++ 코드로 구현한 것입니다.
#include <iostream>
#define stack_size 100
using namespace std;
struct stack {
int top = -1;
int arr[stack_size];
void push(int data) {
if (top == stack_size-1) {
printf("stack is full\n");
return;
}
arr[++top] = data;
}
int pop() {
if (empty()) {
printf("stack is empty\n");
return -1;
}
return arr[top--];
}
int peek() {
if (empty()) {
printf("stack is empty\n");
return -1;
}
return arr[top];
}
bool empty() {
return top <= -1;
}
};
int main() {
stack st;
//현재 스택은 비워져있는 상태
cout << "is stack empty? "<<st.empty() << endl;
cout << st.pop() << endl;
cout << st.peek() << endl;
//for 루프가 돌면 스택은 1개만 저장 가능한 상태
for (int i = 0; i < stack_size-1; i++)
st.push(i + 1);
cout << endl;
cout << "after for loop"<<endl;
st.push(15);
//스택은 전부 채워져 있는 상태
st.push(120);
//스택에서 한 개가 비워짐, 1개 채울 수 있는 상태
st.pop();
st.push(120);
cout<<endl;
//스택이 비워지면 while루프 종료
while(!st.empty())
cout << st.pop() << endl;
}
stack은 다음과 같은 연산을 하게 됩니다.
push: 데이터를 쌓습니다.
pop : 데이터를 하나 꺼내옵니다.
peek : 데이터를 하나 봅니다. 꺼내오지는 않습니다.
empty : 스택이 비어있는 지 확인합니다.
위의 코드를 이해하기 쉽게 그림으로 표현해보겠습니다.
1. 초기 스택의 상태는 이런 그림입니다. top은 맨 아래, -1이라는 배열의 인덱스로 쓸 수 없는 위치에 있지요.
그래서 stack.empty()는 true(1)입니다. stack에서 peek이나 push 연산을 해도 데이터가 없기 때문에 stack is empty라는 메시지를 보게 되고 -1이 반환됩니다.
2. 그 이후 for 루프로 스택의 최상위 위치를 빼고 전부 push연산으로 채웁니다.
top은 아래의 위치에 있습니다.
3. 이제 15을 push하게 되면 스택은 전부 채워졌고, 다음 120은 모두 채워져있기 때문에 스택에 쌓이지 못합니다.
4. 이후 스택에서 pop연산을 했으니 공간이 하나 남고, 다시 120을 push하면 스택에 들어가게 됩니다.
5. 이제 while루프를 돌며 pop연산을 하게 됩니다. 스택에 데이터가 남아있는 동안 출력하게 됩니다. 최종적으로 스택은 초기상태가 됩니다.