Map
자료구조 중 하나인 Map은 키(key)와 값(value)를 쌍으로 갖는 STL입니다. Map의 특징 중 하나는 키 값이 중복되지 않는 다는 것입니다. C++에 있는 Map은 레드블랙트리로 이루어져있으며 검색, 삽입, 삭제가 O(log n)입니다.
코드를 보면서 어떻게 사용할 수 있는지 확인해보도록 하겠습니다. map을 사용하기 위해서는 아래와 같이 map 헤더파일을 include해주어야합니다.
#include <map>
1. 데이터 삽입, 조회, 변경
#include <iostream>
#include <map>
#include <string>
using namespace std;
int main() {
map<string, string> m;
m["seoul"] = "02";
m["kyungki"] = "031";
m["daegu"] = "051";
m["incheon"] = "032";
//맵의 모든 데이터를 순환
//first, second를 보아 pair객체를 사용하는 것을 알 수 있다.
for (auto iter : m) {
cout << iter.first << "의 지역번호:" << iter.second << endl;
}
cout << endl;
//[]로도 접근 가능
cout <<"seoul:"<< m["seoul"] << endl;
//변경
m["daegu"] = "053";
cout << "daegu:" << m["daegu"] << endl;
}배열 인덱스를 다루듯이 사용할 수가 있습니다.
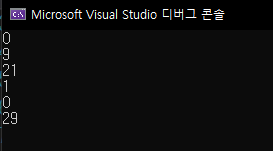
아래는 결과화면입니다.

그런데 한가지 유심히 보면 map의 키,값을 순회할때 키가 오름차순으로 나오고 있네요(daegu - incheon - kyungki - seoul). 내림차순으로 map을 구성하고 싶다면 아래와 같이 사용하세요.
map<string, string,greater<string>> m;그리고 insert()함수를 통해서 삽입할 수도 있습니다. Map은 내부적으로 pair 객체를 이용하여 키와 값을 저장하는데요. first는 키, second는 값이 들어가게 됩니다.
#include <iostream>
#include <map>
#include <string>
using namespace std;
int main() {
map<string, string> users;
users.insert({ "010-3343-1111","reakwon" });
users.insert({ "010-1133-0000","lee" });
users.insert({ "010-1999-9991","huh" });
users.insert({ "010-1192-1928","so" });
users.insert(make_pair<string, string>("010-4444-4455", "kim"));
for (auto it : users)
cout << "name:" << it.second << ", phone:" << it.first << endl;
}
2. 키가 존재하는지 확인
find함수로 키가 존재하는지 확인할 수 있습니다. iterator로 내부적으로 순환하면서 비교하고 찾기 때문에 만약 키가 존재하지 않으면 iterator의 end()를 반환하게 됩니다.
if (users.find("010-1133-0000") != users.end()) {
cout << "키가 존재" << endl;
}
else {
cout << "키가 존재하지 않음" << endl;
}
3. 키-값 삭제
삭제 연산은 erase함수로 키과 값 쌍을 삭제할 수 있습니다.
3-1. 입력된 키와 같은 pair를 삭제
users.erase("010-3343-1111");
3-2. 데이터 모두 삭제
users.erase() 혹은 clear() 함수로 데이터를 모두 삭제할 수 있습니다. 아래와 같이 사용합니다.
users.erase(users.begin(),users.end());
users.clear();
4. 저장된 키-값 수
size() 함수를 사용하면 현재 map에 데이터가 저장된 수를 알 수 있습니다.
users.size()
Map을 이용한 문제풀이
Map을 사용하면 아래의 문제를 쉽게 풀수가 있습니다. 한번 문제보시면서 풀어보시구요. 정답 코드는 아래에 있습니다.
https://www.acmicpc.net/problem/1764
1764번: 듣보잡
첫째 줄에 듣도 못한 사람의 수 N, 보도 못한 사람의 수 M이 주어진다. 이어서 둘째 줄부터 N개의 줄에 걸쳐 듣도 못한 사람의 이름과, N+2째 줄부터 보도 못한 사람의 이름이 순서대로 주어진다.
www.acmicpc.net
#include <iostream>
#include <map>
#include <string>
#include <vector>
using namespace std;
int n, m;
int main() {
cin >> n >> m;
//값은 0으로 default로 설정됨
map<string, int> outsiders;
vector<string> ans;
for (int i = 0; i < n+m; i++) { //듣+보 전부 한꺼번에 입력받음(n+m)
string name;
cin >> name; //이름이 2번 등장하면 outsiders[name] = 2가 된다
outsiders[name]++;
}
//2면 정답
for (auto it : outsiders) {
if (it.second == 2) ans.push_back(it.first);
}
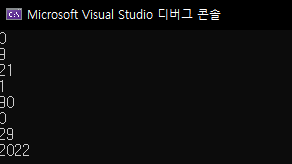
cout << ans.size() << endl;
for (int i = 0; i < ans.size(); i++)
cout << ans[i] << endl;
}
이상으로 포스팅 마치도록 하겠습니다~
'언어 > C++' 카테고리의 다른 글
| [C++] STL vector 개념과 정리 - 사용법 파헤치기 (0) | 2022.03.24 |
|---|---|
| [C언어/C++] lower_bound(하한)과 upper_bound(상한)을 C와 C++에서 사용하는 예제 코드 (0) | 2021.03.23 |
| [C++] new,delete 키워드와 오버라이딩(Overriding),다형성(Polymorphism)의 개념과 virtual키워드 사용방법, 객체의 this 포인터 개념 (0) | 2021.03.18 |
| [C++] 클래스와 상속(Inheritance)의 개념과 사용법, 캡슐화의 이해 (0) | 2021.03.16 |
| [C++]C++ 함수의 특징(오버로딩, 디폴트 인수, 참조자, 인라인 함수) (0) | 2019.05.06 |

REAKWON
와나진짜