버퍼
C 표준입출력 라이브러리에서는 내부적으로 버퍼를 도입하여 입출력을 효율적으로 처리합니다. printf나 scanf 등의 라이브러리 함수는 결국 입력과 출력을 read, write를 통해서 이루어집니다. 버퍼라는 공간을 두는 이유는 내부적으로 write, read를 적시에 최소한으로만 호출하기 위한 것이 목적입니다. 왜 그런 뻘짓을 하느냐구요? CPU를 많이 사용하지 않기 위해서입니다. 한 글자 씩 계속 입력을 받거나 출력을 하면 그만큼 read, write 콜이 잦아지는데 이러면 CPU에 부담이가 성능에 안좋을 영향을 끼치게 되는 겁니다. 버퍼를 사용하는 것은 라이브러리 함수인면에서 응용 프로그램에서는 신경쓰지 않아도 되지만, 버퍼의 처리 방식을 모르게 되면 낭패를 봅니다.
어떻게 버퍼를 이용하는 것을 버퍼링이라고 하고 따라서 세가지 버퍼링 방식이 있습니다.
전체 버퍼링(Full buffering)
이러한 버퍼링은 내부 버퍼에 데이터가 꽉 차게 되면 그제서야 입출력이 되는 방식입니다. 그러니까 버퍼가 전부 차기 전에는 이 데이터를 가지고만 있고 입출력은 하지 않는 것이죠. 위에서 얘기했듯이 이러한 버퍼링의 목적은 read, write를 최소한으로 사용하기 위함입니다. 그래서 버퍼가 전부 찰 때까지 기다리고 있죠. 이 때 "버퍼의 크기가 크면 무조건 좋은 거 아닌가?" 라는 물음을 던질 수 있는데, 정도라는 것이 있듯 최적의 버퍼 크기가 정해져있습니다. 이것을 표준 입출력 라이브러리가 정해줍니다. 우리는 개-꿀만 빨면 됩니다.
보통 파일을 디스크로부터 읽을 때의 버퍼링 방식입니다.
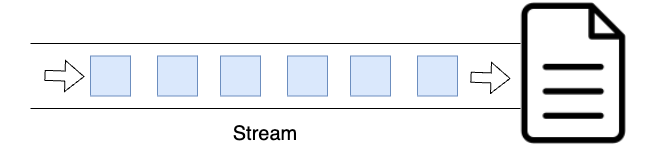
아래와 같은 경우가 전체 버퍼링의 예를 보여줍니다. 붉은 사각형은 비어있는 데이터를 의미하며 파란 사각형은 채워진 데이터를 의미합니다. 현재는 버퍼에 2바이트의 데이터가 모자라서 파일에 기록하지 않고 있습니다. 이때 2바이트가 채워지고 있는 모습입니다.
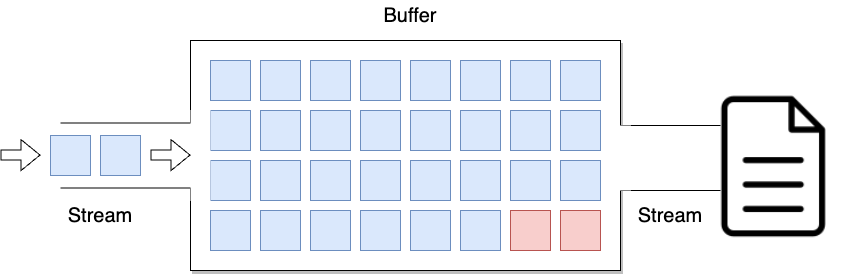
이 때 완전히 버퍼가 채워지면 그제서야 데이터를 한꺼번에 파일로 전송하게 됩니다.
줄 단위 버퍼링(Line buffring)
scanf나 fgets, fgetc 등의 표준 입력 함수나 printf, fputs, putc 등의 함수를 이용한 표준 출력을 사용할 때 이러한 줄 단위 버퍼링이 적용됩니다. 줄 단위 버퍼링은 새 줄 문자('\n')가 나올 때 까지 입력이나 출력을 하는 것입니다. 또한 버퍼가 차게 되면 입출력을 진행합니다. 이 때 버퍼의 크기는 보통 전체 버퍼링의 버퍼 크기보다 작습니다.
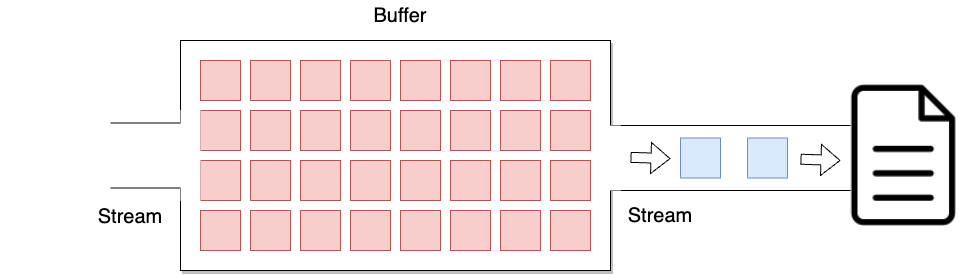
아래와 같은 경우가 줄 단위 버퍼링을 보여줍니다. 아직 데이터가 전부 채워지지 않았으며 이 때 개행 문자인 '\n'이 입력이 되고 있는 상황입니다.
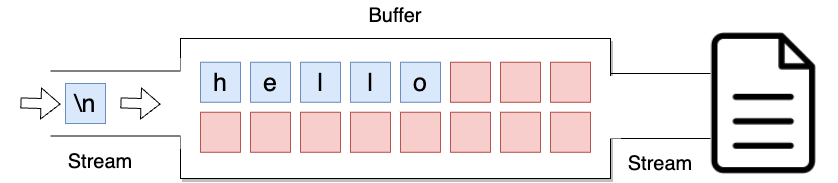
개행 문자를 만나면 버퍼가 채워져있지 않음에도 입출력을 진행하게 됩니다.

비 버퍼링(Unbuffered)
버퍼링은 하지 않는 방식입니다. 왜요? 급하기 때문입니다. 여러분도 급똥이면 장사없듯이 프로그램도 급하면 장사없습니다. 언제가 급할까요? 에러를 출력할때가 그런 상황입니다. 지체없이 에러를 해결해야할 상황이 생기기 때문이지요.
버퍼링 정보 가져오기
그렇다면 보통의 표준 입력, 표준 출력, 표준 에러나 파일에 대한 스트림은 어떤 버퍼링 방식을 갖고 버퍼 크기는 어떻게 결정이 될까요? 아래의 코드는 상황에 따른 입,출력 버퍼에 대한 정보를 표시해주는 코드입니다.
//buffer_info.c
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#ifdef __GLIBC__
#define _IO_UNBUFFERED 0x0002
#define _IO_LINE_BUF 0x0200
#endif
int main(int argc, char *argv[]){
FILE *fp;
char buf[32] = {0, };
if(argc =! 2){
printf("Usage : %s stdin | stdout | stderr | file_name\n",
argv[0]);
return 1;
}
if(!strcmp(argv[1], "stdin")){
fp = stdin;
fgets(buf, sizeof(buf), fp);
} else if(!strcmp(argv[1], "stdout")){
fp = stdout;
printf("stdout\n");
} else if(!strcmp(argv[1], "stderr")){
fp = stderr;
fprintf(fp, "stderr\n");
} else {
fp = fopen(argv[1], "r");
if(fp == NULL){
printf("fopen error\n");
return 1;
}
while(fgets(buf, sizeof(buf), fp) != NULL);
}
if(fp->_flags & _IO_UNBUFFERED)
printf("비버퍼링\n");
else if(fp->_flags & _IO_LINE_BUF)
printf("줄단위 버퍼링\n");
else
printf("전체 버퍼링\n");
printf(" 버퍼 사이즈 : %ld\n", fp->_IO_buf_end - fp->_IO_buf_base);
fclose(fp);
}
# ./a.out stdin
hello
줄단위 버퍼링
버퍼 사이즈 : 1024
# ./a.out stdout
stdout
줄단위 버퍼링
버퍼 사이즈 : 1024
# ./a.out stderr
stderr
비버퍼링
버퍼 사이즈 : 1
# ./a.out /etc/group
전체 버퍼링
버퍼 사이즈 : 4096
단순히 stdin, stdout, stderr에 대해서 fgets나 printf를 한번 호출하지 않고서 fp->_flags를 들여다보면 다른 결과가 나올 수 있습니다. 예를 들면 아래와 같이 fgets를 주석 처리하고 실행해보시면 다른 결과를 보실 수 있을 겁니다.
if(!strcmp(argv[1], "stdin")){
fp = stdin;
//fgets(buf, sizeof(buf), fp);아래의 결과가 위처럼 fgets를 주석처리한 예인데, 결과가 다르죠?
# ./a.out stdin
전체 버퍼링
버퍼 사이즈 : 0이러한 결과를 통해서 알 수 있는 것은 스트림을 열었다고 해서 그 버퍼링이 설정된다는 것이 아니라, read, write를 하는 함수들이 버퍼링을 결정해준다는 사실입니다.
버퍼링 설정
1. setbuf
#include <stdio.h>
void setbuf(FILE *stream, char *buf);setbuf 함수를 이용해서 버퍼링 방식을 설정할 수 있습니다. 대신 시스템이 정해준 버퍼인 BUFSIZ로만 사용이 가능합니다. 반대로 버퍼링을 끌 수도 있습니다.
버퍼를 설정하려면 buf[BUFSIZ]의 버퍼를 *buf인자에 전달해야하고, 버퍼를 끄려면 NULL을 전달하면 됩니다.
아래의 예를 한번 볼까요?
//setbuf.c
#include <stdio.h>
#include <unistd.h>
#include <pthread.h>
//버퍼링을 키거나 끄는 쓰레드
void* buf_control(void *arg){
char buf[BUFSIZ] = {0,};
int on;
while(1){
scanf("%d", &on);
switch(on){
case 0: //OFF
setbuf(stdout, NULL);
break;
case 1: //ON
setbuf(stdout, buf);
break;
}
}
}
//1초마다 "A"를 계속 찍는 쓰레드
void* print_line(void *arg){
while(1){
printf("A");
sleep(1);
}
}
int main(int argc, char *argv[]){
pthread_t tid1, tid2;
printf("[0] 버퍼 동작 X\t [1] 버퍼 동작 O\n");
pthread_create(&tid1, NULL, buf_control, NULL);
sleep(1);
pthread_create(&tid2, NULL, print_line, NULL);
pthread_join(tid1, NULL);
pthread_join(tid2, NULL);
}# ./a.out
[0] 버퍼 동작 X [1] 버퍼 동작 O
0
AAAAAAAAAAAAAAA1
0
AAAAAAAAAAAA1A
0
AAAAA1
0
AAA1
0
AAAAA^C
pthread의 개념을 몰라도 좋습니다. 단순히 buf_control이라는 함수, print_line이라는 함수가 동시에 수행되는 것만 아시면 됩니다.
buf_control이라는 함수에서는 버퍼링을 끄거나 키거나 할 수 있는데, 1은 버퍼링을 키는 동작, 0은 버퍼링을 끄는 동작이라는 것을 볼 수 있을 겁니다.
print_line함수는 한 글자씩 1초마다 printf를 통해서 출력을 해주는 함수입니다. 단 줄바꿈(\n)은 하지 않죠. printf는 디폴트 동작으로는 줄단위 버퍼링 방식을 사용하는 것을 위에서 확인했었죠?? 그래서 버퍼링을 설정하게 되면 줄바꿈이 나오지 않거나 버퍼 크기인 1024바이트가 채워지지 않으면 출력을 하지 않습니다.
2. setvbuf
#include <stdio.h>
int setvbuf(FILE *stream, char *buf, int mode, size_t size);세 가지의 버퍼링 방식을 설정할 수 있습니다. stream에 대해서 size만큼의 buf를 버퍼링합니다. 이때 mode는 비버퍼링(unbuffered), 줄 단위 버퍼링(line buffering), 전체 버퍼링(full buffering)을 설정할 때 쓰입니다. mode에 대한 설명은 아래를 참고하세요.
| mode | 설명 |
| _IONBF | 비버퍼링 모드 |
| _IOLBF | 줄 단위 버퍼링 모드 |
| _IOFBF | 전체 버퍼링(블록 버퍼링) 모드 |
setvbuf는 성공시 0, 실패시 0이 아닌 값을 설정하여 돌려줍니다.
확실히 setbuf 함수보다는 보다 세세한 설정이 가능하죠? 그렇다면 setvbuf함수를 통해서 버퍼링을 설정하는 예를 볼까요? 아래는 stdout을 줄 단위 버퍼링이 아닌 4바이트의 전체 버퍼링으로 바꾼 하나의 예입니다.
//setvbuf.c
#include <stdio.h>
#include <unistd.h>
#ifdef __GLIBC__
#define _IO_UNBUFFERED 0x0002
#define _IO_LINE_BUF 0x0200
#endif
#define BUF_SIZE 4
int main(){
char buf[BUF_SIZE] = {0,};
FILE *fp = stdout;
if(setvbuf(fp, buf, _IOFBF, BUF_SIZE) != 0){
printf("setvbuf _IOLBF error \n");
return 1;
}
if(fp->_flags & _IO_UNBUFFERED) printf("비버퍼링\n");
else if(fp->_flags & _IO_LINE_BUF) printf("줄단위 버퍼링\n");
else printf("전체 버퍼링\n");
while(1){
printf("A");
sleep(1);
}
}실행해보면 줄 단위 버퍼링이 아닌 전체 버퍼링으로 설정된 것을 볼 수 있습니다. 그리고 4초마다 버퍼가 꽉 채워지기 때문에 출력이 되는 동작을 확인할 수 있네요.
# ./a.out
전체 버퍼링
AAAAAAAAAAA^C'언어 > C언어' 카테고리의 다른 글
| [C언어] 시간 Format 함수 사용 방법 - strftime, strptime (0) | 2022.04.05 |
|---|---|
| [C/C++] 반복문 for문에 대한 이해 - 마무리는 별찍기 풀이 및 코드 (0) | 2022.03.29 |
| [C/C++] switch ~ case 문의 활용방법 - 흔한 실수까지 (0) | 2022.03.29 |
| [C언어] 조건문 If ~ else if ~ else 총정리 - 쉽게 하는 실수들까지 (0) | 2022.03.23 |
| [C/C++] 문자열 -> 16진수 String to Hex(Ascii to Hex) 소스 코드 구현 (0) | 2021.12.08 |

REAKWON
와나진짜